
说说python自带的speech和speech_recognition的使用以及效果
人工智能这么火爆的时代,近来正好有时间就想研究以下智能语音这块的内容,虽然感觉自带的模块应该识别不太准确,不然就不会有百度的padder,google的tensorflow等框架,但是路要一步步走,饭也要一步步吃,初学的时候总要各种尝试一下。以下内容是我最近两天的尝试结果。
环境win10,python3.7
先说说speech,这个贼简单
pip install speech
目前我使用的是这个:recognize_sphinx,因为
以上七个中只有 recognition_sphinx()可与CMU Sphinx 引擎脱机工作, 其他六个都需要连接互联网。
SpeechRecognition 附带 Google Web Speech API 的默认 API 密钥,可直接使用它。其他六个 API 都需要使用 API 密钥或用户名/密码组合进行身份验证,因此本文使用了 Web Speech API。
安装之后就可以让他说话了,在import speech的时候,会出现一些环境的配置,我这边是win10的系统,就会出现语音识别的相关设置,按照提示操作即可。
import speech #这边三行是自己会说话 speech.say("小王王 你好呀") speech.say("hello world") speech.say("要开始啦") #这边是进行对话 while True: print(u"开始说话") say = speech.input() # 接收语音 speech.say("you said:" + say) # 说话 print(u"说话结束") if say == "你好": speech.say("How are you?") elif say == "天气": speech.say("今天天气棒棒棒!") elif say == "小王王": speech.say("小王王 棒棒棒") elif say == "小丽平": speech.say("小丽平 六六六") else: speech.say("对不起 我不知道你说什么")
运行完,以上程序,我发现它总是不知道我在说啥,于是回复我-->对不起 我不知道你说什么,就一个你好回答对了,不过还是要尝试一下。
然后我就想说可不可以自己录一个音频,实现识别的效果,于是发现speech_recognition这个库,也是很简单直接安装一下,但是需要安装别的包。
pip install speech_recognition -i https://mirror.baidu.com/pypi/simple
然后这个还需要pocketsphinx这个库,于是win10安装一直报错,我就干脆直接下载wheel的轮子,去这个网站https://www.lfd.uci.edu/~gohlke/pythonlibs/#pocketsphinx,搜索pocketsphinx,下载对应的版本到本地即可,然后直接pip install 你下载的.wheel就可以啦
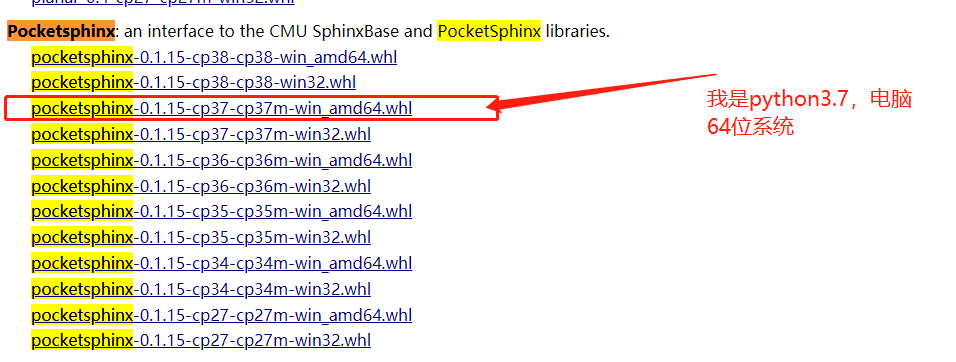
相关录音代码识别
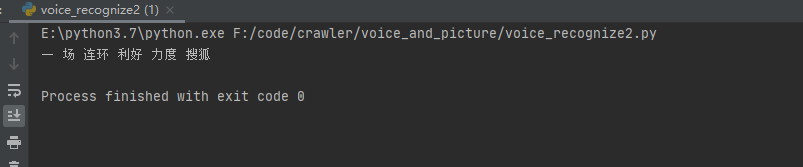
# -*- coding: utf-8 -*- import speech_recognition as sr AUDIO_FILE = "11.wav" r = sr.Recognizer() with sr.AudioFile(AUDIO_FILE) as source: audio = r.record(source) # read the entire audio file res = r.recognize_sphinx(audio) res1 = res.split(" ") # for each in res1: print(" ".join(res1))
运行结果:(其实我说的是你好你好 运动 生活)
说道这里,大家可能会遇到一些问题,比如碰到这个错误
第一种错误:
Audio file could not be read as PCM WAV, AIFF/AIFF-C, or Native FLAC; check if file is corrupted or in another format
这个是啥意思呢,就是你的音频文件必须是wav的格式,而不是你录音之后就直接修改后缀名就可以的,我的是华为手机,录制的音频是ma4,
首先我要转换为wav,我们可以去这个网上在线转换后下载https://www.aconvert.com/cn/audio/m4a-to-mp3/,
如果是mp4的,这个地址转换wav格式,https://www.aconvert.com/cn/audio/mp4-to-mp3/。
明明你这玩意是中文的被翻译成英文的,因为这个库的安装路劲下面只有en-US,当然只能翻译成英文的啦
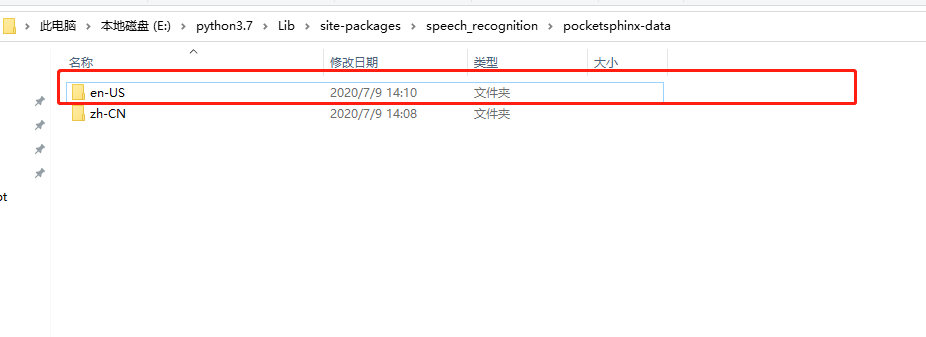
于是我们需要添加一个zh-CN的文件夹,下载对应的中文就可以啦
(1)到对应的python库安装路径下新建zh-CN
(2)https://sourceforge.net/projects/cmusphinx/files/Acoustic%20and%20Language%20Models/下载对应的中文库,下载对应的压缩包后解压
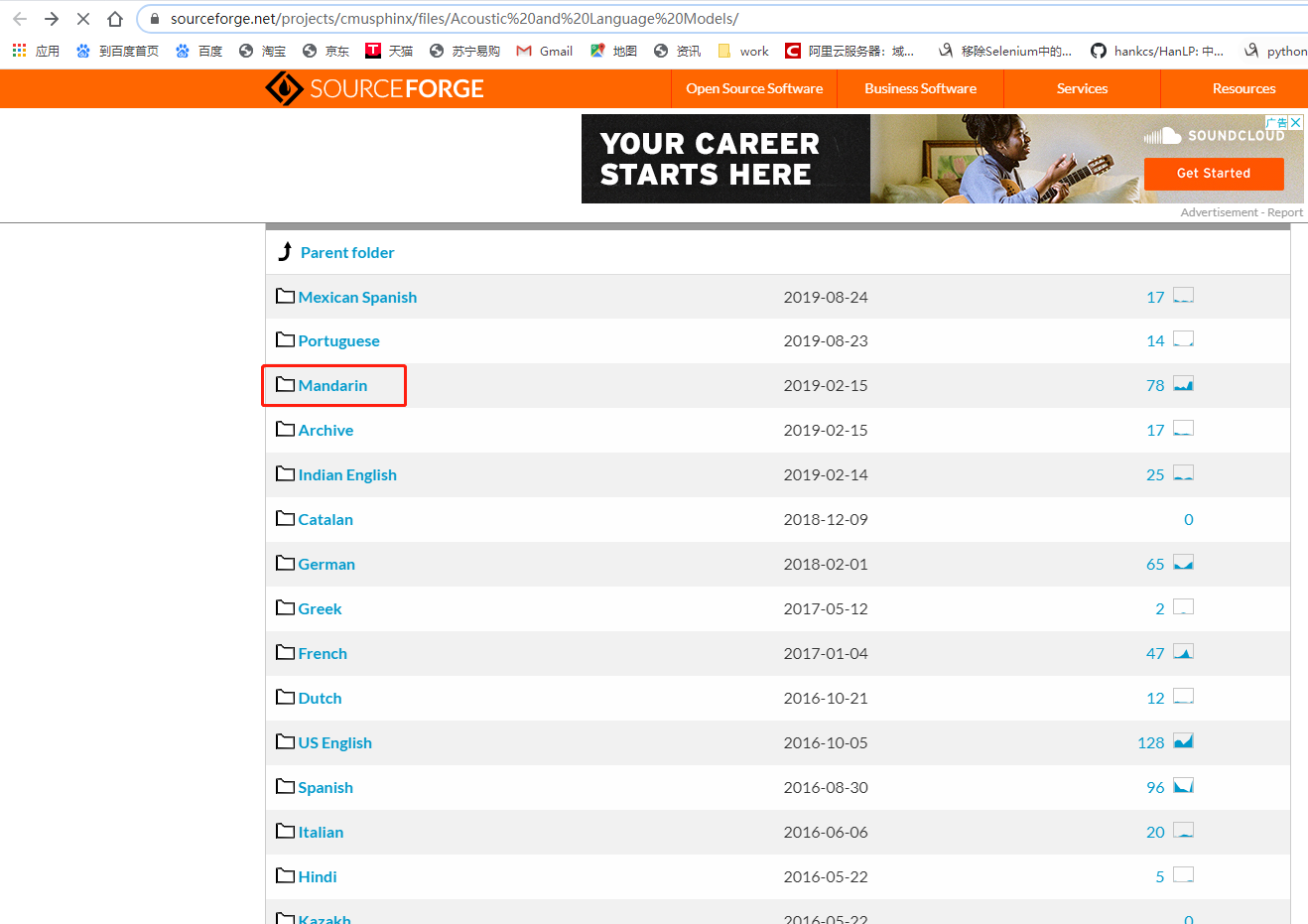
(3)复制以下内容并修改命名

最后发现为啥还是不行,因为代码初始化的时候默认是英文 en-US,所以这边代码修改一下,即可
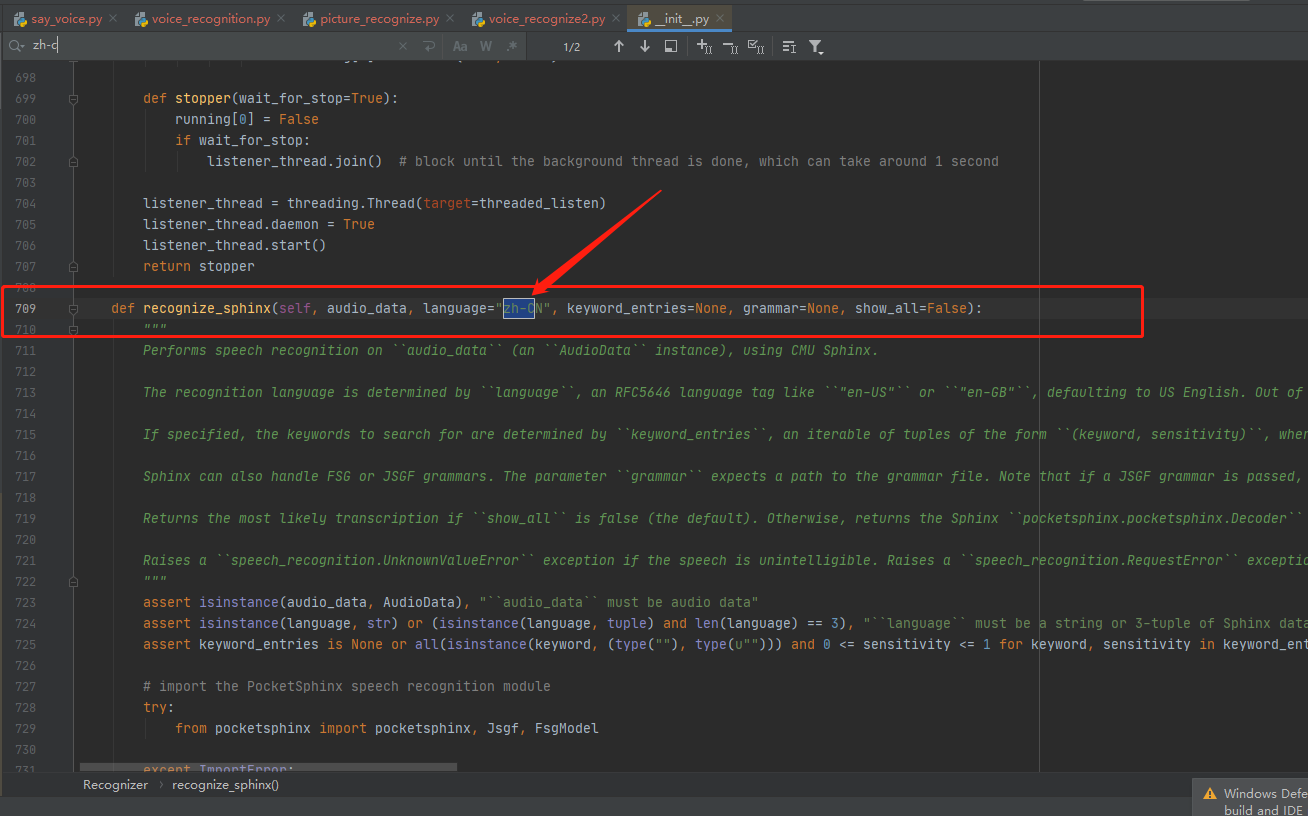
或者修改前面的传参:
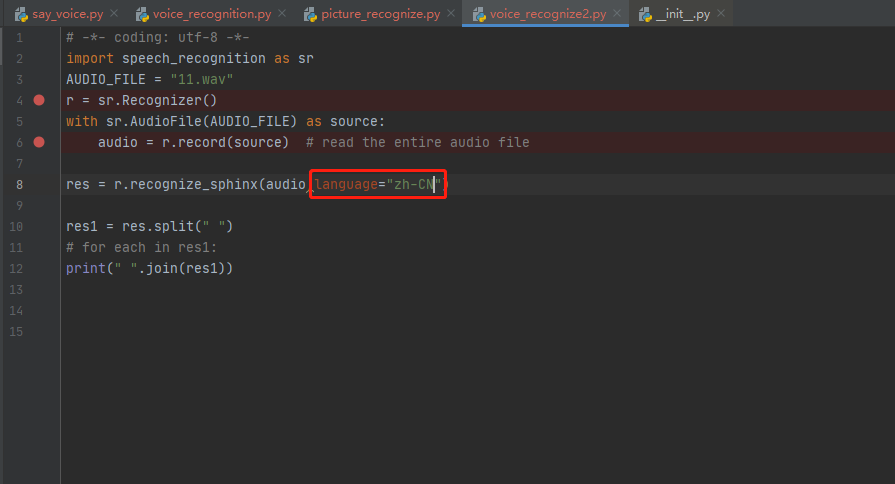
然后在执行以下你的代码就可以翻译成中文了,感觉python自带的库,最后的结果貌似不太理解,只好在研究研究啦,加油!我感觉可能配置上训练或者学习,可能可以实现比较好的效果,继续研究,有时间的话再分享。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号