
爬虫实现免登入
近来身边很多人问,爬虫怎么实现免登入,这边介绍几种方法。
1、scrapy的FormRequest模块
2、requests的post实现免登入
3、selenium实现自动化登入过程
接下来,我们来实现http://oursteps.com.au/的免登入
我们先说前两种的情况,使用scrapy和requests的模拟登入
打开浏览器,输入http://www.oursteps.com.au/bbs/portal.php回车
定义好请求的地址,使用fiddler抓包抓取到网页登入输入的信息

然后我们就知道他们的用户名和密码的键对应的是username、password
其实很简单就是我们需要请求这个接口地址http://www.oursteps.com.au,加上用户名和密码参数,并设置对应的头部配置好ua信息,然后进行请求
scrapy的FormRequest,跳过新建scrapy工程以及新建爬虫的步骤了,直接干代码,上面的注释非常详细了


# -*- coding: utf-8 -*- import scrapy from scrapy.http import Request,FormRequest class LoginSpider(scrapy.Spider): name = 'login' allowed_domains = ['oursteps.com.au'] #这个默认的起点网址可以不用,因为我们下面配置了start-requests的方法,他们的功能类似,都是去爬第一个起始的网址 #start_urls = ['http://oursteps.com.au/'] #这个header可以是任何浏览器的头文件,用于伪装 header = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0" } #里面的查询地址最好是使用在fidder里面看见的地址,cookiejar设为真,parse是用一个回调函数,执行爬取信息之后对应的操作 def start_requests(self): return [Request("http://www.oursteps.com.au/", meta={"cookiejar": 1}, callback=self.parse)] #发送一个post请求,数据是字典格式的,发送完了之后执行另外一个回调函数 def parse(self, response): data = { "username": "your username", "password": "your password", } print("ready to login") # 通过FormRequest.from_response()进行登陆 return [FormRequest.from_response(response, # 设置cookie信息 meta={"cookiejar": response.meta["cookiejar"]}, # 设置headers信息模拟成浏览器 headers=self.header, # 设置post表单中的数据 formdata=data, # 设置回调函数,此时回调函数为next() callback=self.next, )] #回调函数,直接把返回的页面保存下来 def next(self,response): data=response.body #注意是二进制格式 f=open("E:/temp/ourstep/a.html","wb") f.write(data) f.close() #登录成功了之后,再跳转到另外一个页面去,记住带着cookie的状态 yield Request("http://www.oursteps.com.au/bbs/portal.php?mod=article&aid=82186",callback=self.next2,meta={"cookiejar": True}) #保存新页面的内容 def next2(self,response): data=response.body f = open("E:/temp/ourstep/b.html", "wb") f.write(data) f.close()
requests的模拟登入代码
# -*- coding: utf-8 -*- import requests headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36', } data = { "username": "your username", "password": "your password", } url ='http://www.oursteps.com.au/' session = requests.Session() session.post(url,headers = headers,data = data) # 登录后,我们需要获取另一个网页中的内容 response = session.get('http://www.oursteps.com.au/bbs/portal.php?mod=article&aid=82186',headers = headers) print(response.status_code) print(response.text) f = open("E:/temp/ourstep/c.html", "wb") f.write(response.text.encode("utf-8")) f.close()
执行结果:a.html是登入的情况,b.html和c.html都是使用登入的cookie进行相关页面打开
a.html,看到a.html的xww123说明已经登入进来了
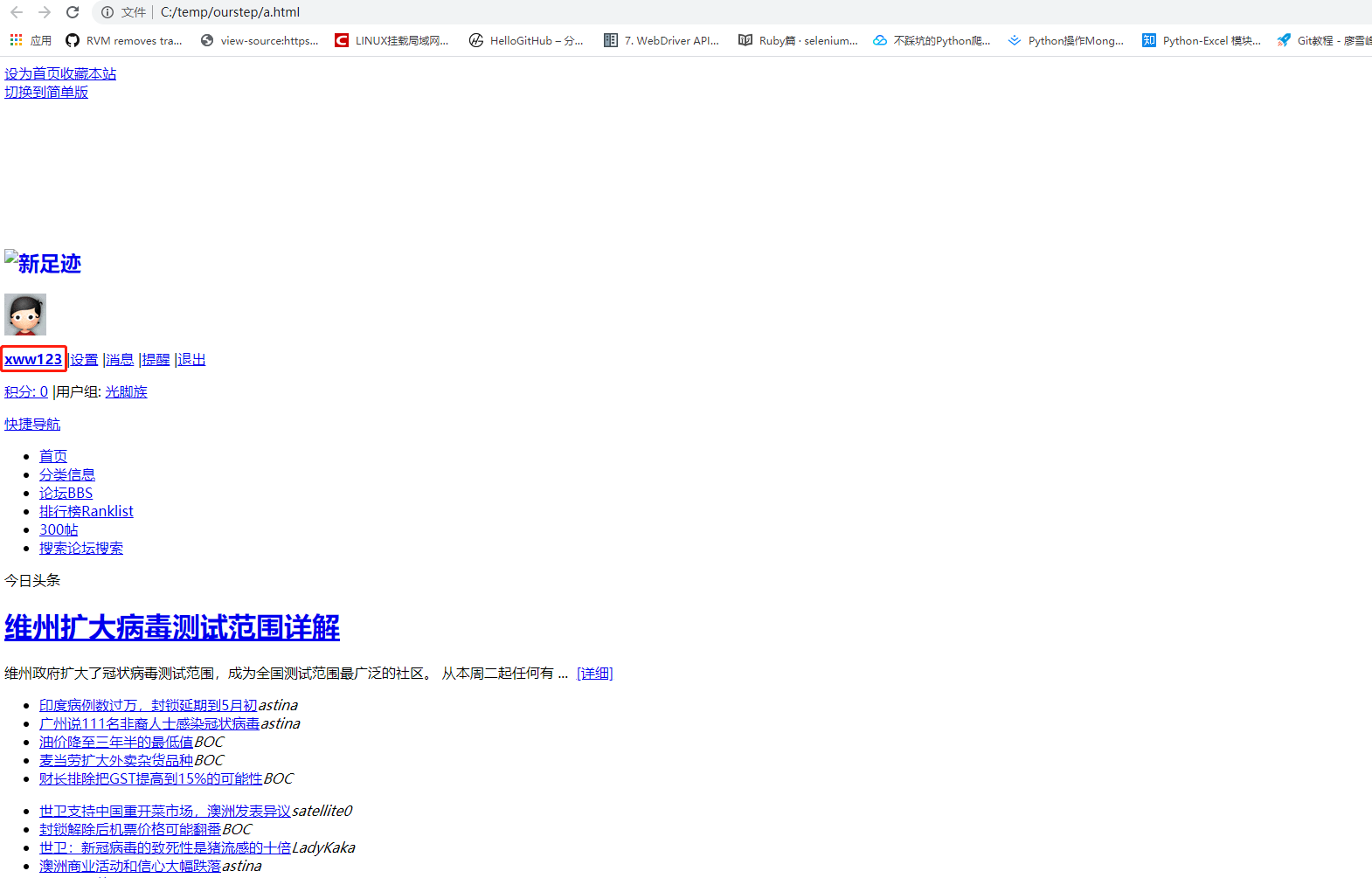
b.html
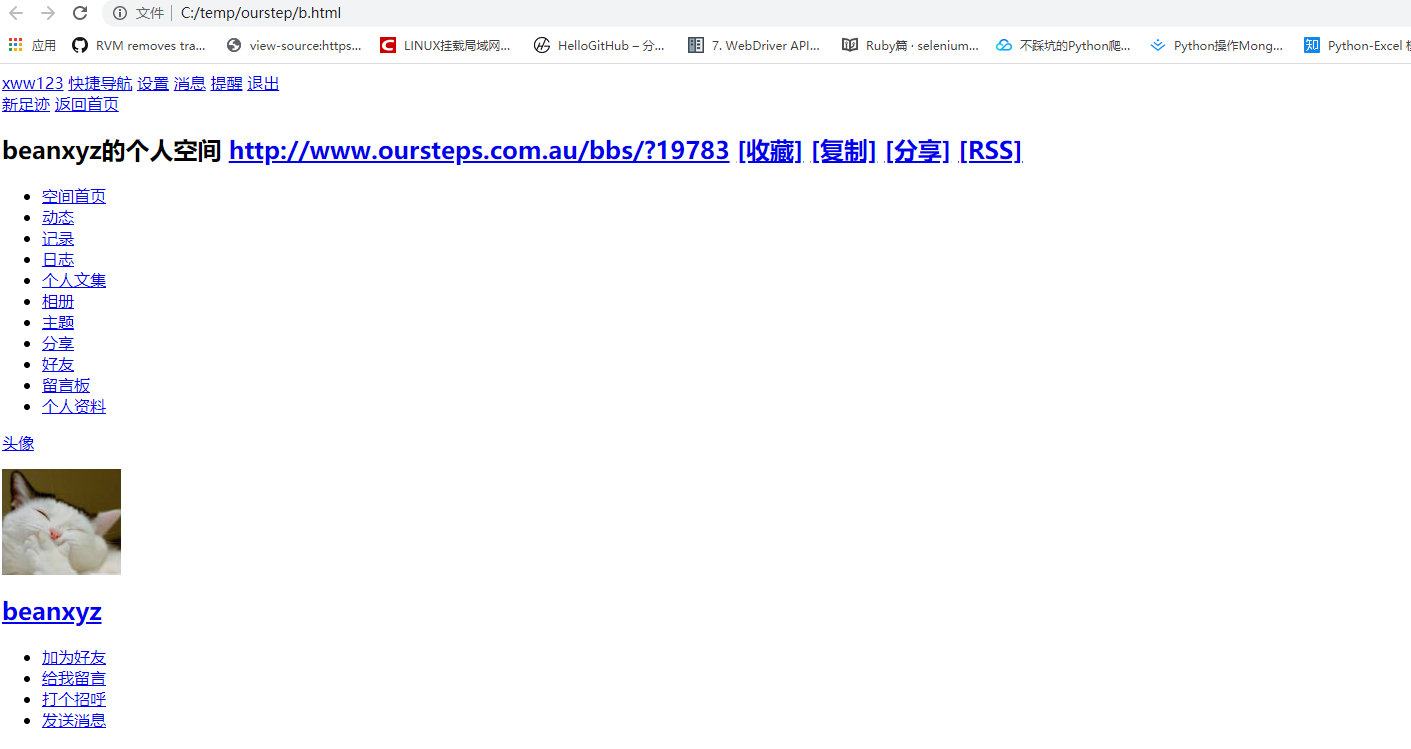
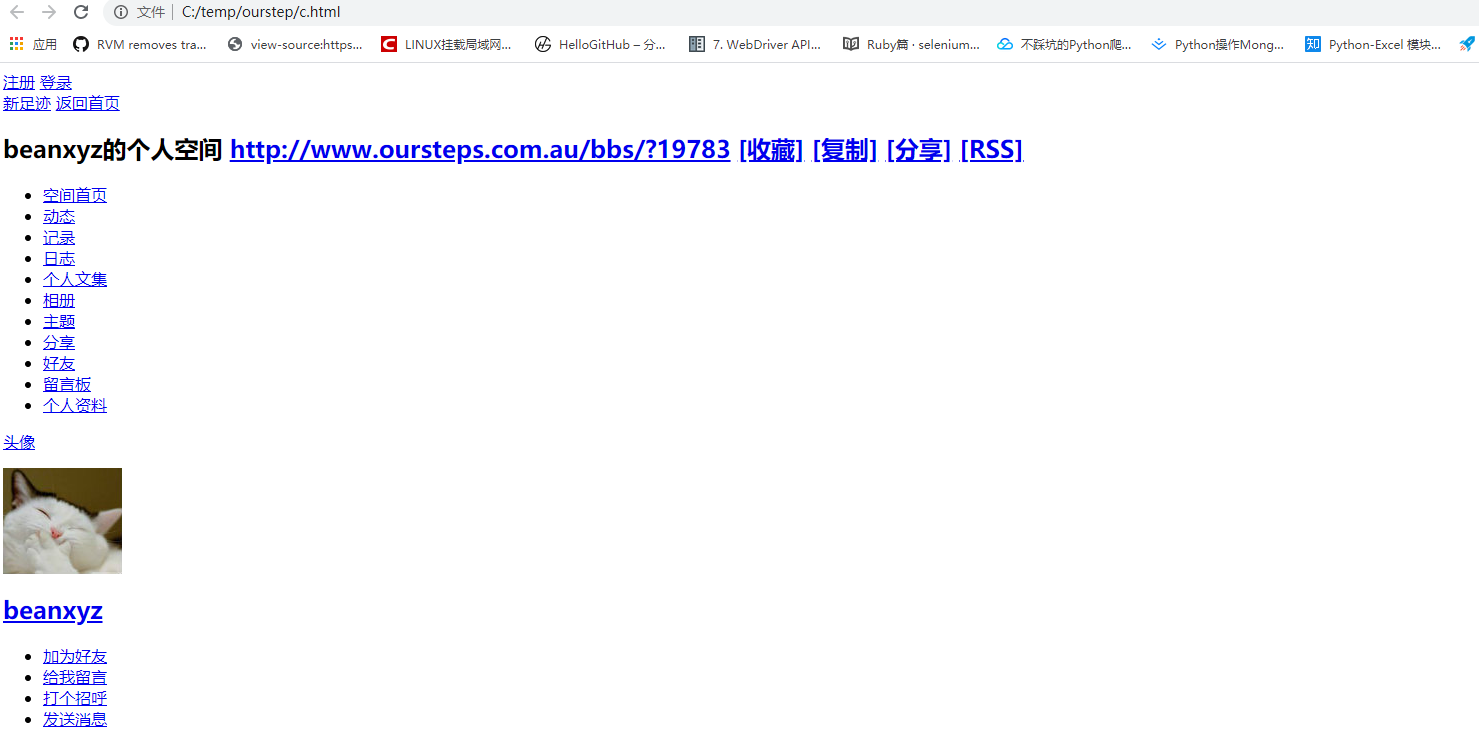
c.html
selenium模拟手动登入,输入用户名密码,代码如下:
# coding:utf-8 from selenium import webdriver import re,time,urllib2 from random import choice from selenium.webdriver import Chrome from selenium.webdriver import ChromeOptions import time option = ChromeOptions() # option.add_experimental_option('excludeSwitches', ['enable-automation']) driver = Chrome(options=option,executable_path='E:\seop\chrome_80\chromedriver') time.sleep(5) driver.get('http://www.oursteps.com.au/bbs/portal.php') driver.maximize_window() driver.find_element_by_xpath("//*[@id=\"ls_username\"]").send_keys("your username") driver.find_element_by_xpath("//*[@id=\"ls_password\"]").send_keys("your password") driver.find_element_by_xpath("//*[@id=\"lsform\"]/div/div/table/tbody/tr[2]/td[3]/button").click() time.sleep(5) driver.quit()
使用selenium登入效果如下,如果登入别的页面,在登入后直接driver.get("页面url")就可以
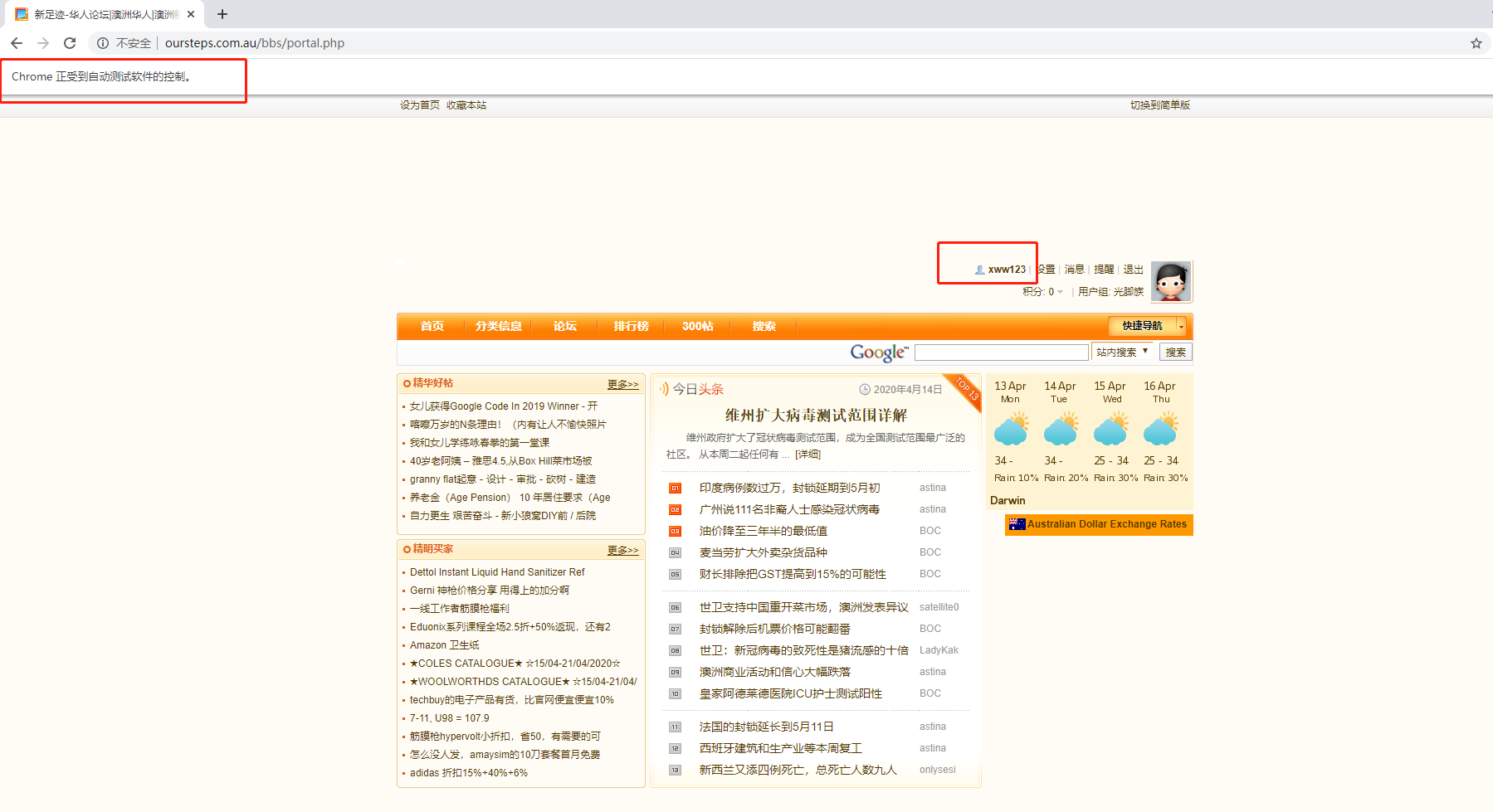
以上三种,都可以实现免登入的效果。
ps:
还有一种就是使用requests,使用cookie登入,就需要把登入的cookie保存下来,然后带上cookie直接请求这个url就可以,这个和post方法类似,就不做介绍啦。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号