

python的一些乱码处理
当我们写代码时,都会碰到这样那样子的乱码问题,有时候在网络上面搜索半天也不一定可以解决,今天根据我的经历,总结一下。
(1)首先呢,不管怎么样我们写代码养成一个好习惯,在头部主动添加以下,代码会省掉不少麻烦
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
(2)然后碰到中文乱码,我们引入字符串。
例如 s1 = "中国"
有时候我们代码上面操作是很容易出现乱码,我们可以在前面定义或者使用的时候加一个u
s1=u"中国"
(3)还有一种json的乱码,一个明明的json的字符串,却不能使用json.loads(),这里给大家看一下例子。
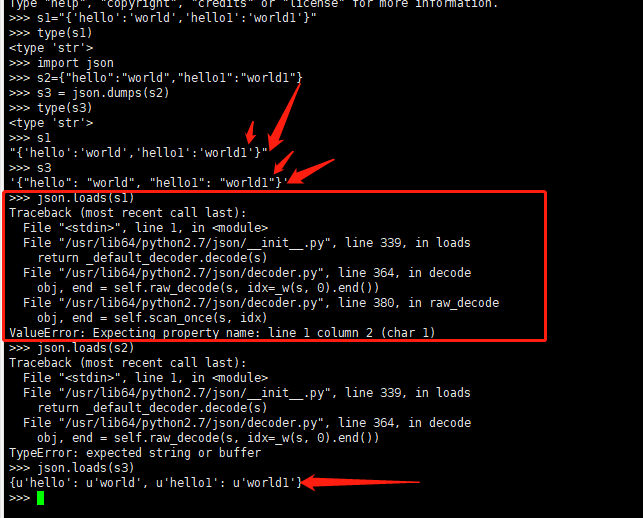
json.loads的时候,他只认里面是双引号的,那是不是把他替换之后就可以认了呢?

看上面很明显可以,但是有一种情况下,当前的情况还不能处理,还需要多加一步操作,具体就是替换引号前的 u-> 空 :
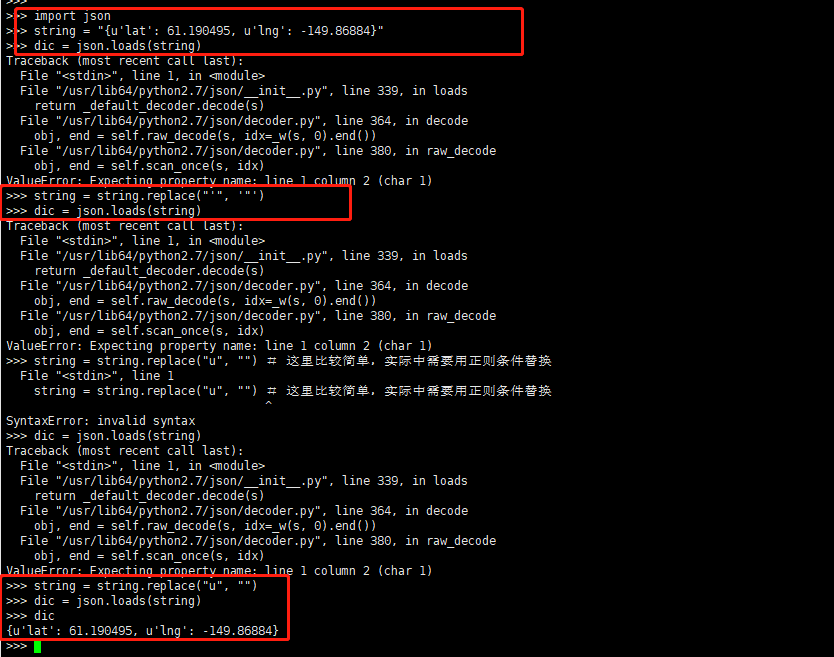
(4)浏览器传参的时候,乱码的问题,需要
urllib.unquote("传参") --屏蔽特殊的字符、比如如果url里面的空格!url里面是不允许出现空格的。
按照标准, URL 只允许一部分 ASCII 字符(数字字母和部分符号),其他的字符(如汉字)是不符合 URL 标准的。
所以 URL 中使用其他字符就需要进行 URL 编码
以上是我在开发过程遇到的编码问题,希望可以帮助到大家!

