

又一次认识java(一) ---- 万物皆对象
假设你现实中没有对象。至少你在java世界里会有茫茫多的对象,听起来是不是非常激动呢?
对象,引用,类与现实世界
现实世界里有许很多多的生物,非生物,跑的跳的飞的,过去的如今的未来的,令人眼花缭乱。我们编程的目的,就是解决现实生活中的问题。所以不可避免的我们要和现实世界中各种奇怪的东西打交道。
在现实世界里。你新认识了一个朋友,你知道他长什么样,知道了他的名字年龄。地址。
知道他喜欢干什么有什么特长。你想用java语言描写叙述一下这个人。你应该怎么做呢?
这个时候。就有了类的概念。
每个类相应现实世界中的某一事物。比方现实世界中有人。
那么我们就创建一个关于“人”的类。
每个人都有名字。都有地址等等个人信息。
那么我们就在“人”的类里面增加这些属性。
每个人都会吃,会走路,那么我们就在“人”的类里面增加吃和走的方法。
当这个世界又迎来了一个新生命,我们就能够“new”一个“人”,“new”出来的就叫”对象“。
每个人一出生,父母就会给他取个名字。
在程序里,我们须要用一种方式来操作这个“对象”,于是。就出现了引用。我们通过引用来操作对象。设置对象的属性。操作对象的方法。
这就是最主要的面向对象。
【 现实世界的事物】 —抽象—> 【类 】—new—>【对象 】<—控制— 【引用】
从创建一个对象開始
创建对象的前提是先得有一个类。
我们先自己创建一个person类。
//Person类
public class Person {
private String name;
private int age;
public void eat(){
System.out.println("i am eating");
}
}创建一个person对象。
Person p = new Person();怎么理解这句简单的代码呢?
- new Person :一个Person类型的对象
- () : 这个括号相当于调用了person的无參构造方法
- p : Person对象的引用
有的人会觉得p就是new出来的Person对象。
这是错误的理解,p仅仅是一个Person对象的引用而已。那么问题来了,什么是引用?什么又是对象呢?这个要从内存说起。
创建对象的过程
java大体上会把内存分为四块区域:堆,栈。静态区。常量区。
- 堆 : 位于RAM中,用于存放全部的java对象。
- 栈 : 位于RAM中,引用就存在于栈中。
- 静态区 : 位于RAM中。被static修饰符修饰的变量会被放在这里
- 常量区 :位于ROM中, 非常明显。放常量的。
事实上,我们不须要关心java的对象,变量究竟存在了哪里。由于jvm会帮我们处理好这些。
可是理解了这些。有助于提高我们的水平。
当运行这句代码的时候。
Person p = new Person();首先,会在堆中开辟一块空间存放这个新来的Person对象。然后,会创建一个引用p。存放在栈中,这个引用p指向Person对象(事实上是,p的值就是Person对象的内存地址)。
这样。我们通过訪问p。然后得到了Person的内存地址,进而找到了Person对象。
然后又有了这样一句代码:
Person p2 = p;这句代码的含义是:
创建了一个新的引用,保存在栈中,引用的地址也指向Person的地址。
这个时候。你通过p2来改变Person对象的状态,也会改变p的结果。由于它们指向同一个对象。(String除外。之后会专门讲String)
此时。内存中是这样的:
用一种非常通俗的方式来解说一下引用和对象。
大家都应该用过windows吧。win有一个奇妙的东西叫做快捷方式。
我们桌面的图标大部分都是快捷方式。它并非我们安装在电脑上的应用的可运行文件(不是.exe文件),那么为什么点击它能够打开应用程序呢?这个我不用讲了把。
我们的对象和引用就和快捷方式和它连接的文件一样。
我们不直接对文件进行操作,而是通过快捷方式来进行操作。
快捷方式不能独立存在,同样,引用也不能独立存在(你能够仅仅创建一个引用。可是当你要使用它的时候必须得给它赋值。否则它将毫无用处)。
一个文件能够有多个快捷方式。同样一个对象也能够有多个引用。而一个引用仅仅能同一时候相应一个对象。
在java里,“=”不能被看成是一个赋值语句。它不是在把一个对象赋给另外一个对象,它的运行过程实质上是将右边对象的地址传给了左边的引用,使得左边的引用指向了右边的对象。java表面上看起来没有指针。但它的引用事实上质就是一个指针。在java里,“=”语句不应该被翻译成赋值语句,由于它所运行的确实不是一个简单的赋值过程。而是一个传地址的过程,被译成赋值语句会造成非常多误解,译得不准确。
特例:基本数据类型
为什么会有特例呢?由于用new操作符创建的对象会存在堆里,二在堆里开辟空间等行为效率较操作栈要低。而我们平时写代码的时候会经常创建一些“小变量”。比方int i = 1;假设每次都用Interger来new一个,效率不是非常高而且浪费内存。
所以针对这些情况。java提供了“基本数据类型”,基本数据类型一共同拥有八种,每个基本数据类型存放在栈中。而他们的值存放在常量区中。
举个样例:
int i = 2;
int j = 2;我们须要知道的是,在常量区中,同样的常量仅仅会存在一个。当运行第一句代码时。先查找常量区中有没有2,没有。则开辟一个空间存放2。然后在栈中存入一个变量i,让i指向2;
运行第二句的时候,查找发现2已经存在了,所以就不开辟新空间了。直接在栈中保存一个新变量j。让j指向2。
当然,java堆每个基本数据类型都提供了相应的包装类。
我们依然能够用new操作符来创建我们想要的变量。
Integer i = new Integer(1);
Integer j = new Integer(1);可是,用new操作符创建的对象是不同的,也就是说,此时,i和j指向不同的内存地址。由于每次调用new操作符。都会在堆开辟新的空间。
当然,说到基本数据类型,不得不提一下java的经典设计。
先看一段代码:
为什么一个是true一个是false呢?
我就不讲了,应该都知道吧。我就贴一个Integer的源代码(jdk1.8)吧。
Integer 类的内部定义了一个内部类,缓存了从-128到127的全部数字,所以,你懂得。
又一个特例 :String
String是一个特殊的类,由于它被final修饰符所修饰。是一个不可改变的类。当然。看过java源代码后你会发现,基本类型的各个包装类也被final所修饰。这里以String为例。
我们来看这样一个样例
运行第一句 : 常量区开辟空间存放“abc”,s1存放在栈中指向“abc”
运行第二句,s2 也指向 “abc”。
运行第三句,由于“abc”已经存在,所以直接指向它。
所以三个变量指向同一块内存地址,结果都为true。
当s1内容改变的时候。这个时候,常量区开辟新的空间存放“bcd”,s1指向“bcd”,而s2和s3指向“abc”所以仅仅有s2和s3相等。
这样的情况下,s1,s2,s3都是字符串常量,相似于基本数据类型。(假设运行的是s1 = “abc”,那么结果会都是true)
我们再看一个样例:
运行第一行代码: 在堆里分配空间存放String对象,在常量区开辟空间存放常量“abc”,String对象指向常量。s1指向该对象。
运行第二行代码:s2指向上一步new出来的string对象。
运行第三行代码: 在堆里分配新的空间存放String对象。新对象指向常量“abc”,s3指向该对象。
到这里,非常明显。s1和s2指向的是同一个对象
接着就非常诡异了,我们让s1 依然= “abc”,可是结果s1和s2指向的地址不同了。
怎么回事呢?这就是String类的特殊之处了。new出来的String不再是上面的字符串常量,而是字符串对象。
由于String类是不可改变的。所以String对象也是不可改变的。我们每次给String赋值都相当于运行了一次new String(),然后让变量指向这个新对象,而不是在原来的对象上改动。
当然,java还提供了StringBuffer类,这个是能够在原对象上做改动的。假设你须要改动原对象。那么请使用StringBuffer类。
值传递和引用传递的战争
java是值传递还是引用传递的呢?毫无疑问,java是值传递的。那么什么又叫值传递和引用传递呢?
我们先来看一个样例:
这是一个非常经典的样例,我们希望调用了swap函数以后,a和b的值能够互换。可是事实上并没有。为什么会这样呢?
这就是由于java是值传递的。也就是说,我们在调用一个须要传递參数的函数时,传递给函数的參数并非我们传进去的參数本身。而是它的副本。说起来比較拗口,可是事实上原理非常easy。我们能够这样理解:
一个有形參的函数。当别的函数调用它的时候。必须要传递数据。
比方swap函数,别的函数要调用swap就必须传两个整数过来。
这个时候,有一个函数按耐不住寂寞,扔了两个整数过来。可是,swap函数有洁癖,它不喜欢用别人的东西。于是它把传过来的參数复制了一份。然后对复制的数据修改动改。而别人传过来的參数动根本没动。
所以,当swap函数运行完成之后,交换了的数据仅仅是swap自己复制的那一份。而原来的数据没变。
也能够理解为别的函数把数据传递给了swap函数的形參,最后改变的仅仅是形參而实參没变,所以不会起到不论什么效果。
我们再来看一个复杂一点的样例(Person类增加了get,set方法):
能够看到,我们把p1传进去,它并没有被替换成新的对象。由于change函数操作的不是p1这个引用本身,而是这个引用的一个副本。
你依然能够理解为,主函数将p1复制了一份然后变成了chagne函数的形參,终于指向新Person对象的是那个副本引用,而实參p1并没有改变。
再来看一个样例:
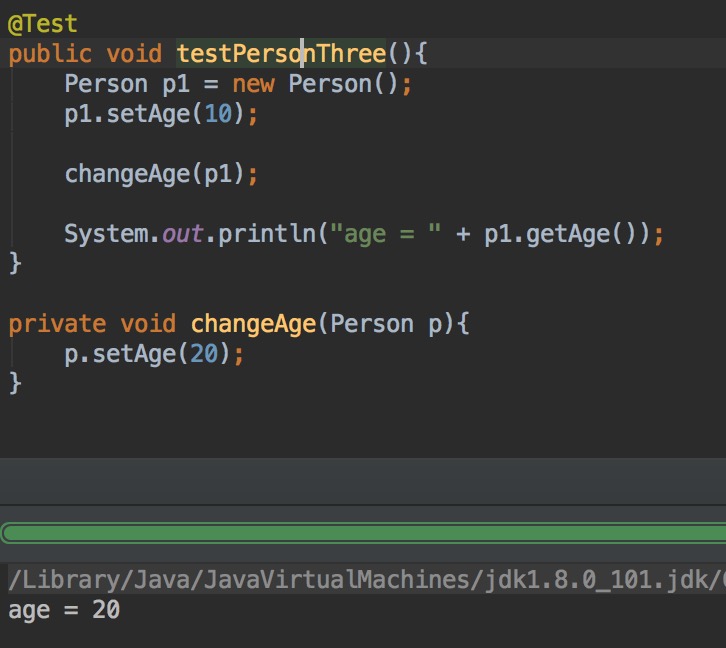
这次为什么就改变了呢?分析一下。
首先。new了一个Person对象,暂且叫他小明吧。然后p1指向小明。
小明10岁了,随着时间的推移,小明的年龄要变了,调用了一下changgeAge方法。把小明的引用传了进去。
传递的过程中,changgeAge也有洁癖。于是复制了一份小明的引用,这个副本也指向小明。
然后changgeAge通过自己的副本引用,改变了小明的年龄。
由于是小明这个对象被改变了,所以全部小明的引用调用方法得到的年龄都会改变
所以就变了。
最后简单的总结一下。
java的传值过程,事实上传的是副本,无论是变量还是引用。
所以,不要期待把变量传递给一个函数来改变变量本身。
对象的强引用,软引用,弱引用和虚引用
Java中是JVM负责内存的分配和回收,这样尽管使用方便,程序不用再像使用c那样担心内存,但同一时候也是它的缺点(不够灵活)。
为了解决内存操作不灵活这个问题,能够採用软引用等方法。
先介绍一下这四种引用:
强引用
曾经我们使用的大部分引用实际上都是强引用。这是使用最普遍的引用。
假设一个对象具有强引用,那就相似于不可缺少的生活用品。垃圾回收器绝不会回收它。当内存空 间不足,Java虚拟机宁愿抛出OutOfMemoryError错误。使程序异常终止,也不会靠任意回收具有强引用的对象来解决内存不足问题。
软引用(SoftReference)
假设一个对象仅仅具有软引用。那就相似于可有可物的生活用品。假设内存空间足够,垃圾回收器就不会回收它,假设内存空间不足了,就会回收这些对象的内存。仅仅要垃圾回收器没有回收它。该对象就能够被程序使用。
软引用可用来实现内存敏感的快速缓存。
软引用能够和一个引用队列(ReferenceQueue)联合使用。假设软引用所引用的对象被垃圾回收,JAVA虚拟机就会把这个软引用增加到与之关联的引用队列中。
弱引用(WeakReference)
假设一个对象仅仅具有弱引用,那就相似于可有可物的生活用品。
弱引用与软引用的差别在于:仅仅具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它 所管辖的内存区域的过程中,一旦发现了仅仅具有弱引用的对象,无论当前内存空间足够与否,都会回收它的内存。只是。由于垃圾回收器是一个优先级非常低的线程, 因此不一定会非常快发现那些仅仅具有弱引用的对象。
弱引用能够和一个引用队列(ReferenceQueue)联合使用。假设弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用增加到与之关联的引用队列中。
虚引用(PhantomReference)
“虚引用”顾名思义,就是形同虚设。与其它几种引用都不同。虚引用并不会决定对象的生命周期。假设一个对象仅持有虚引用,那么它就和没有不论什么引用一样。在不论什么时候都可能被垃圾回收。
虚引用主要用来跟踪对象被垃圾回收的活动。
虚引用与软引用和弱引用的一个差别在于:虚引用必须和引用队列(ReferenceQueue)联合使用。
当垃 圾回收器准备回收一个对象时,假设发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用增加到与之关联的引用队列中。
程序能够通过推断引用队列中是 否已经增加了虚引用,来了解被引用的对象是否将要被垃圾回收。程序假设发现某个虚引用已经被增加到引用队列,那么就能够在所引用的对象的内存被回收之前採取必要的行动。
在实际开发中。弱引用和虚引用不经常使用,用得比較多的是软引用,由于它能够加速jvm的回收。
软引用的使用方式:
关于软引用,我之后会单独写一篇文章,所以这里先一笔带过。
对象的复制
java除了用new来创建对象,还能够通过clone来复制对象。
那么这两种方式有什么同样和不同呢?
- new
new操作符的本意是分配内存。
程序运行到new操作符时,首先去看new操作符后面的类型,由于知道了类型。才干知道要分配多大的内存空间。
分配完内存之后,再调用构造函数,填充对象的各个域,这一步叫做对象的初始化,构造方法返回后,一个对象创建完成,能够把他的引用(地址)公布到外部。在外部就能够使用这个引用操纵这个对象。
- clone
clone在第一步是和new相似的, 都是分配内存。调用clone方法时,分配的内存和源对象(即调用clone方法的对象)同样。然后再使用原对象中相应的各个域。填充新对象的域, 填充完成之后。clone方法返回,一个新的同样的对象被创建,同样能够把这个新对象的引用公布到外部。
怎样利用clone的方式来得到一个对象呢?
看代码:
对Person类做了一些改动
看实现代码:
这样就得到了一个和原来一样的新对象。
深复制和浅复制
可是,细心而且善于思考的人可能一经发现了一个问题。
age是一个基本数据类型,支架clone没什么问题。可是name可是一个String类型的啊。我们clone后的对象里的name和原来对象的name是不是指向同一个字符串常量呢?
做个试验:
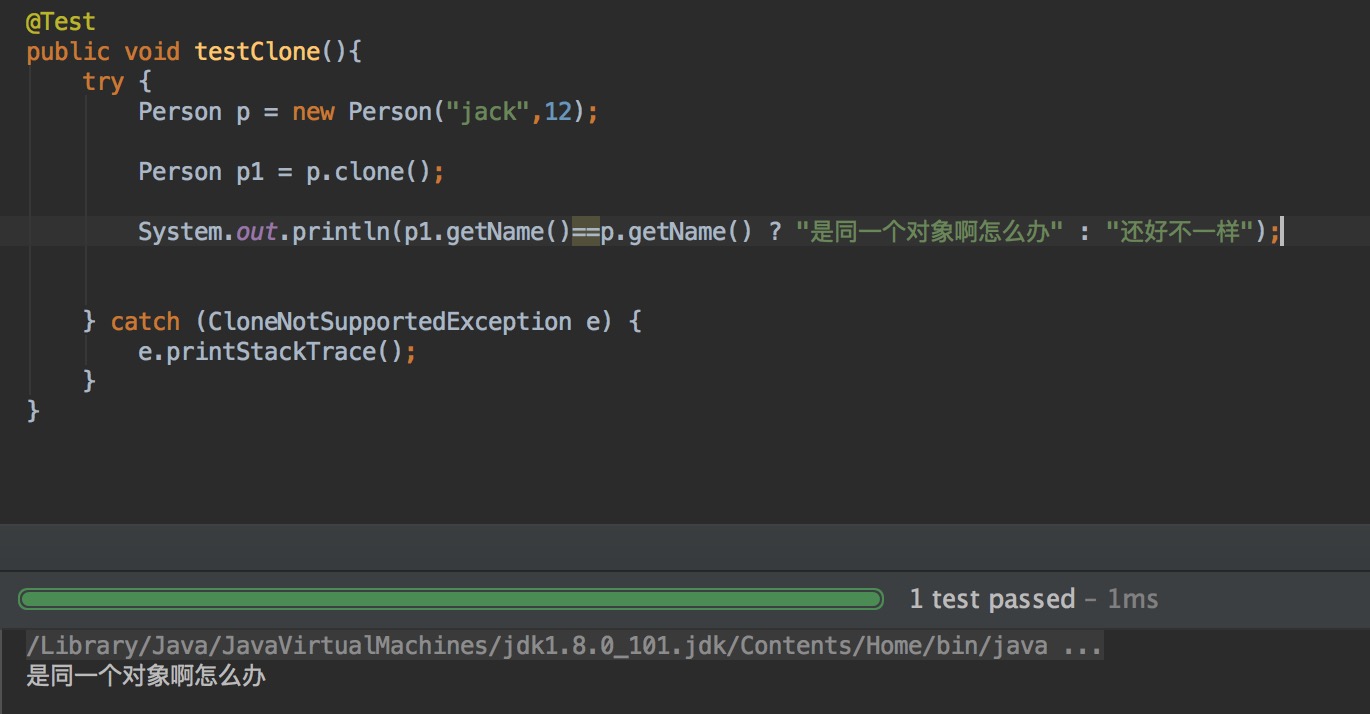
果然,是同一个对象。假设你不能理解。那么看这个图。
事实上假设仅仅是String还好,由于String的不可变性,当你随便改动一个值的时候,他们就会指向不同的地址了,可是除了String,其它都是可变的。这就危急了。
上面的这样的情况。就是浅克隆。
这样的方式在你的属性列表中有其它对象的引用的时候事实上是非常危急的。
所以,我们须要深克隆。也就是说我们须要将这个对象里的对象也clone一份。怎么做呢?
在内存中通过字节流的拷贝是比較easy实现的。把母对象写入到一个字节流中,再从字节流中将其读出来,这样就能够创建一个新的对象了。而且该新对象与母对象之间并不存在引用共享的问题,真正实现对象的深拷贝。
//使用该工具类的对象必须要实现 Serializable 接口,否则是没有办法实现克隆的。
public class CloneUtils {
public static <T extends Serializable> T clone(T obj){
T cloneObj = null;
try {
//写入字节流
ByteArrayOutputStream out = new ByteArrayOutputStream();
ObjectOutputStream obs = new ObjectOutputStream(out);
obs.writeObject(obj);
obs.close();
//分配内存,写入原始对象,生成新对象
ByteArrayInputStream ios = new ByteArrayInputStream(out.toByteArray());
ObjectInputStream ois = new ObjectInputStream(ios);
//返回生成的新对象
cloneObj = (T) ois.readObject();
ois.close();
} catch (Exception e) {
e.printStackTrace();
}
return cloneObj;
}
}使用该工具类的对象仅仅要实现 Serializable 接口就可实现对象的克隆,无须继承 Cloneable 接口实现 clone() 方法。
測试一下:
非常完美
这个时候,Person类实现了Serializable接口
是否使用复制,深复制还是浅复制看情况来使用。
关于序列化与反序列化以后会讲。
这篇文章到这里就临时告一段落了,兴许有补充的话我会继续补充,有错误的话,我也会及时改正。欢迎大家提出问题。
博客同步更新在http://blog.improvecfan.cn
事例代码放在github:https://github.com/CleverFan/JavaImprove

