android日记(十)
上一篇:android日记(九)
1.Release包如何调试?
官方文档:android:debuggable是否可以调试应用(即使在处于用户模式的设备上运行时)。如果可以调试,则设为"true";如果无法调试,则设为"false"。默认值为"false"。- 默认地,debug默认debuggable=true,release默认debuggable=false。
- 可以配置Release包的debuggable也为true,重新打个包后,便可以调试了,有两种配置方法。
buildTypes { release { debuggable true } }or
<application xmlns:tools="http://schemas.android.com/tools" android:debuggable="true"></application> - Release下的WebView也可以在Chorme devTools中调试,设置方式如下,
WebView.setHorizontalScrollBarEnabled(true)
- 也可以通过对手机系统root,或者刷机后,修改系统的ro.debuggable为1,调试Release。
2.Android签名V1和V2
- 在打签名包时,签名有V1和V2两个版本。其中,V1(Jar Signature)只对jar包进行签名检验,V2(Full APK Signature)对整个apk都进行签名校验,更加安全。

-
由于V2版本的签名在Android7.0才开始支持,对7.0以下将无法安装。因此当app的minSdkVersion需要兼容7.0以下设备时,不能只采用V2签名;换言之,如果app无需兼容7.0以下,则应当选择V2签名,确保签名包完全无法被更改,更安全。
- 如果只选择V1签名,7.0以下设备不受影响,7.0以上设备也还是能够正常安装,只是不够安全。
- 但当targetSdk升级到android11(API 30)后,仅使用V1签名的apk将无法在android11上安装或更新。
![]()
- 一般地,为了兼容7.0以下设备,打包时,同时选择V1和V2签名,所有机型都能安装,还能保证7.0及以上的安全。

3.通过adb shell命令dump app的信息
- 手机里安装了某个app,有时候我们想知道该app的一些信息,比如版本号、唤起协议、签名版本、targetSdk版本等,就可以通过adb shell 命令获取。
- 完整命令如下
adb shell dumpsys package <package_name> //获取全部信息 adb shell dumpsys package <package_name> | grep XXX //获取XXX信息
- 在此前之前,需要先知道目标app的包名,打开目标app后,使用下面的命令获得
adb shell dumpsys window | grep mCurrentFocus // 或者 adb shell dumpsys window | grep mFocusedWindows
- 比如查看查看微信,其包名为com.tencent.mm

查看微信的包信息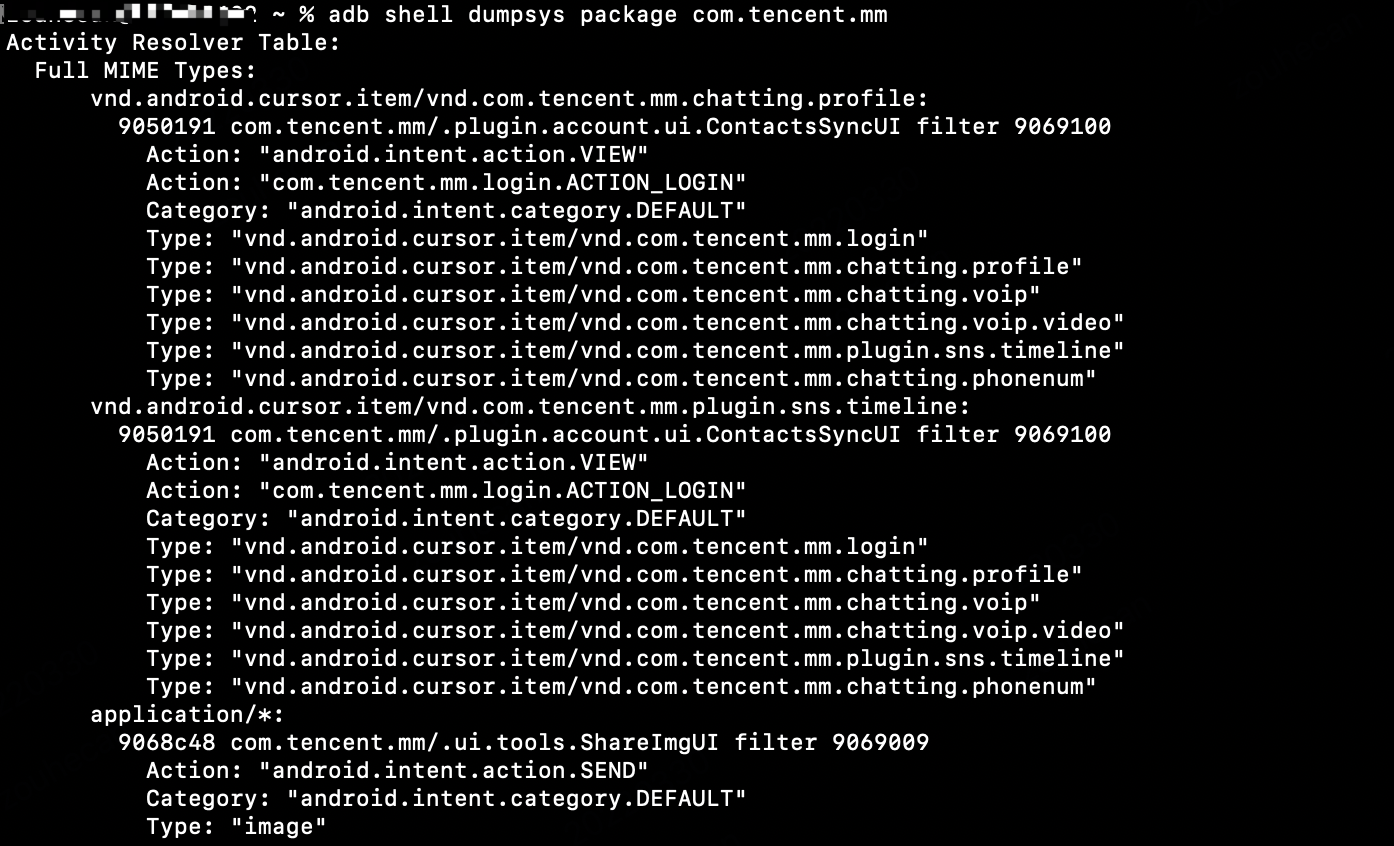
- 信息太多,可在抓取时搜索过滤。
![]()

4.android应用设置里的“清除缓存”与“清除数据”分别清除了什么数据
- app应用数据存储在data/data/app_package_name/
- 清除数据 —— 清除全部应用数据
- 在应用数据目录中,存在cache文件夹
- 清除数据 —— 清除cache文件夹中的数据
5.Android文件缓存目录
- 手机ROM存储空间,包括外部公共目录、外部私有目录和内部目录
- 外部公共目录,路径为/storage/emulated/0,通过getExternalStorageDirectory()访问,app卸载时不会清除
- 外部私有目录,路径为/sdcard/Android/data/app_package_name/,通过getExternalFilesDir()和getExternalCacheDir()访问,app卸载时会清除
- app内部目录,路径为/data/data/app_package_name,通过getCacheDir()和getFilesDirs()访问,app卸载时会清除
- 应用管理中的清除缓存,会清除/data/data/app_package_name/cache目录
- android10(targetSdkVersion=29)新变更,在此之前访问所有存储目录都无需权限,但此之后,访问外部公共目录需要授权。android11后变为强制,未授权访问会导致崩溃。外部存储空间-共享存储空间、外部存储空间-其它目录 App无法通过路径直接访问,不能新建、删除、修改目录/文件等, 需要通过Uri访问
6.Java内部类引入外部局部变量为何必须是final修饰
- final本身只是一个语法层面的修饰符,在编译后的字节码中没有任何意义
- 内部类,包括匿名内部类,引用外部变量时,分两种情况。
- 一是:外部变量是外部类的全局变量,内部类实际上持有外部类的引用,从而能够正常引用和操作外部类的全部变量。
int index = 1; protected void onResume() { super.onResume(); backImage.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { index ++;//编译无误 } }); } - 二是:外部变量是外部类方法的局部变量,外部类方法里的局部变量在方法执行完时,方法栈的生命就结束了。那为什么内部类里还能引用到这个局部变量呢?这是因为局部变量被“拷贝”了一份到内部类中。
protected void onResume() { super.onResume(); int index = 1; backImage.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { index ++;//编译不过 } }); } - 正是因为这种拷贝机制的存在,内部类里操作的局部变量,和外部方法里的局部变量,只是表面看着一样,实则不是同一个变量。那就导致了,内部类里对局部变量的修改,不会同步到外部方法的变量。java设计者为了避免这种“无效修改”对开发人员造成困惑,从而在语法层面规定,内部类里只能引用外部方法中被final修饰过的局部变量,杜绝修改。
7.Kotlin内部类引用外部局部变量并修改的原理
- 在java中,内部类只能引用外部final的局部变量,但是kotlin内部类中却可以引用和修改外部var修饰的局部变量。
- 这并不是局部变量方法栈的生命周期发生了变化,而是内部类对外部局部变量的引用发生了变化。
- kotlin会将内部类用到的外部类局部变量自动进行一层包装,包装类对象引用是final修饰的,局部变量做为包装类的一个成员属性,将包装类引用传到内部类中,内部类中便可以随意修改包装类的这个成员属性,而不改变包装类引用本身。例如,
override fun onViewCreated(view: View, savedInstanceState: Bundle?) { super.onViewCreated(view, savedInstanceState) var index = 1 mapView.setOnClickListener { index ++ } }反编译成java实现,可以看到,外部局部变量index,在内部类中的实际引用是IntRef包装类引用。
public void onViewCreated(@NotNull android.view.View view, @Nullable Bundle savedInstanceState) { Intrinsics.checkNotNullParameter(view, "view"); super.onViewCreated(view, savedInstanceState); final IntRef index = new IntRef(); index.element = 1; CtripUnitedMapView var10000 = this.mapView; if (var10000 == null) { Intrinsics.throwUninitializedPropertyAccessException("mapView"); } var10000.setOnClickListener((OnClickListener)(new OnClickListener() { public final void onClick(android.view.View it) { int var10001 = index.element++; } })); }
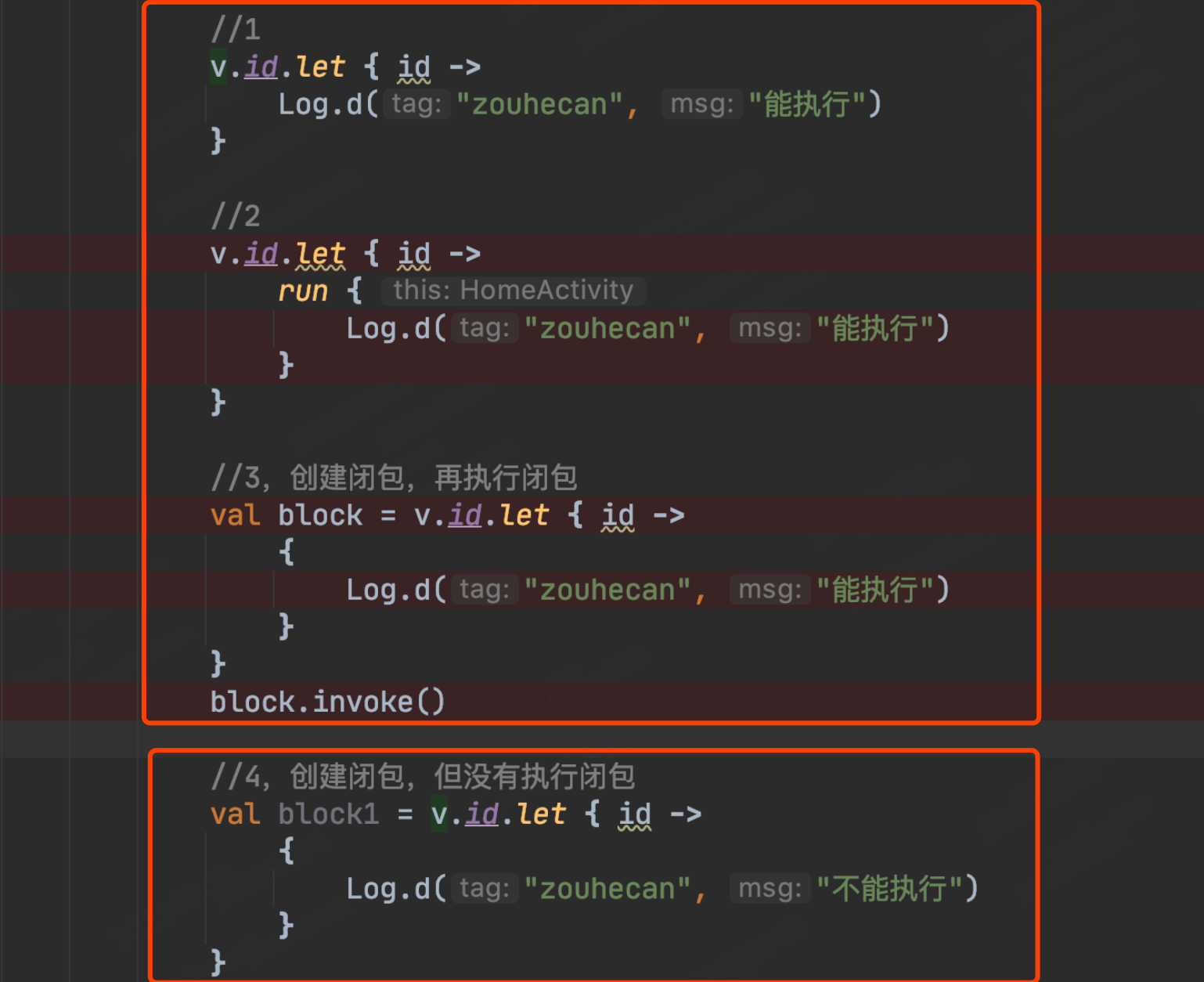
8.kotlin内联函数let、with、run、apply
- let函数,本质是当前对象的一个扩展函数。
![]()
-
with函数,本质不是扩展函数,而是定义了一个函数,并将当前对象做为函数的参数。
override fun onBindViewHolder(holder: ViewHolder, position: Int){ val item = getItem(position)?: return with(item){ holder.tvNewsTitle.text = StringUtils.trimToEmpty(titleEn) holder.tvNewsSummary.text = StringUtils.trimToEmpty(summary) holder.tvExtraInf.text = "难度:$gradeInfo | 单词数:$length | 读后感: $numReviews" ... } } - run函数,相当于let与with的结合,是当前对象的扩展函数,并将当前对象做为参数传入
val user = User("Kotlin", 1, "1111111") val result = user.run { println("my name is $name, I am $age years old, my phone number is $phoneNum") 1000 } - apply函数,结构与run函数一样,只是返回值不同。run函数返回的是必包最后一行的执行结果,而apply函数返回的对象本身。
mapContainer.addView(FrameLayout(this).apply { layoutParams = ViewGroup.LayoutParams(ViewGroup.LayoutParams.MATCH_PARENT, ViewGroup.LayoutParams.MATCH_PARENT) addView(initMapView(), ViewGroup.LayoutParams.MATCH_PARENT, ViewGroup.LayoutParams.MATCH_PARENT) })
9.1个字符的String.length()结果一定是1吗?
- 在java中,绝大多数字符的String.length()结果都是1,但有些却是2,比如字符‘𝄞’,
String str = "𝄞";//U+1D11E int length = str.length(); System.out.println(str + ".length()=" + length);
![]()
- 这是因为,String.length()返回的并不是字符的个数,而是字符编码占用的基本单元数。
- java使用utf-16编码,一个基本单元是16位,对于码点U+0xFFFF以内的字符,占用2个字节即1个编码单元;而U+0xFFFF以上的字符,会占用4个字节,2个编码单元
- 因此,对于码点U+0xFFFF以内的字符,String.length()结果为1;而U+0xFFFF以上的字符,String.length()结果为2
- 获取字符串长度科学方法位,判断字符串存在多少个码点,真实长度也就是多少。使用codePointCount方法,"𝄞"字符是一个完整的码点,故而长度为1
String str = "𝄞"; int length = str.length(); System.out.println(str + ".length()=" + length); int realLength = str.codePointCount(0, str.length()); System.out.println(str + ".realLength=" + realLength);
![]()


10.关于Unicode编码
- 不管什么编码方式,最终是要把字符转换成0和1的二进制表示
- 最开始的ASCII码,用1个字节(8位,最高为固定为0)来表示常用的128个字符(0-9,a-z, A-Z,和常用标点、控制符号),就可以完整进行英文编码了
- 那中文汉字如何编码呢?对ASCII码进行扩充,GB2312规定,用两个字节来表示一个汉字,一个小于127号的字符含义与原来相同,但是大于127号的字符的连续两个字节为一个汉字。其中高字节从0xA1-0xF7,低字节从0xA1-0xFE,这样可以表达7000多个简体汉字了
- GB2312还出现了一个小插曲,中文汉字实在太多了,很快发现一些生僻字没纳入进去,于是在GB2312的基础上,干脆规定只要高字节是大于127,低字节不用低于127也行,这样又扩充了2万多个汉字,这个编码规则叫GBK
- 世界上还有那么多国家和那么多文字,每个国家都自己弄一套标准,那互相谁都看不懂,全是乱码。于是Unicode做为一个统一的标准就被诞生了,其思想是收集所有的字符集组合成一个统一的字符集,未超过因为4字节(232-1)能表达42亿多字符,每个字符给予一个唯一的码点,通过unicode官网可以查询每个字符的码点
- Unicode统一了编码标准,但是问题在于每个字符需要4个字节表示,这极大增加了文件size,这便是utf-32
- utf-8解决了utf-32占用空间太大的问题,其核心思想是可变长,用1~4个字节来表示一个字符。编码规则为:单字节字符,首位为0,其他7位对应字符的码点,兼容ASCII码。N字节字符(N>1),第一个字节的前N位都是1,剩余N-1个字节的前两位都是10,剩下的二进制位使用字符的unicode码点来填充。具体需要几字节看字符的码点落在下表的哪个区间。反过来计算机在识别编码时,看首位为0的话,识别为单字节;首两位时10的话,认为是某个字符的低字节位;高位是11xxx0的,认为是一个字符的高字节开始。
![]()
比如“汉”字的码点0x6c49(110 1100 0100 1001),落在第3行,按照utf-8编码的话,那编码格式为 1110xxxx 10xxxxxx 10xxxxxx,按照规则填充埋点的二进制位得到的编码结果就是11100110 10110001 10001001,转换成16进制为0xE6 0xB1 0x89,占3个字节。 - java、javascript等语言使用的都是utf-16编码,基本单元为16位(2个字节),设计思想是将utf-8的变长与utf-32的定长结合起来,其编码的字符要么是2个字节,要么是4个字节。在Unicode码点中,0xD800-0xDFFF是一个空段,不映射任何码点。utf-16正是利用这个空段,规定:如果2字节的编码落在这个空段内,说明要和另外2字节组合为4字节字符;如果2字节的编码未落在这个空段内,则认为是这两个字节就是一个完整字符。因此,utf-16要达到的一个规则就是,对于码点在0xFFFF以内的码点,直接使用其码点进行编码。但对于0xFFFF以上的码点,要按照一种可逆的规则,给其拼接上可识别的空段。具体为:1)将码点(大于0xFFFF)-0x10000,得到20位的差值;2)将20位差值拆分位高10位(H)和低10位(L);3)H+0xD800,将高10位挪到0xD800-0xDBFF之间;4)L+0xDC00,将低10位挪到0xDFFF之间;如此一来,当收到一个2字节的编码时,便根据该字节落在哪个区段,便知道是一个独立字符还是一个4字节字符,并且知道是4字节字符的高字节还是低字节,该规则用公式表达为
-
H = Math.floor((c-0x10000) / 0x400)+0xD800 L = (c - 0x10000) % 0x400 + 0xDC00 - utf-16编码,以码点0x20BB7为例,因为码点大于0xFFFF,所以确定为4字节编码。1)0x20BB7 - 0x10000,得到0x10BB7;2)0x10BB7 = 0001 00001011 10110111,拆分为高低10位,H=0001000010,L=1110110111;3)H+0xD800,得到0xD842;4)L+0xDC00,得到0xDFB7;从而编码结果为0xDC00 0xDF87

- 2字节理论上最多可以表示65536个字符,这便基本能够涵盖了世界上最主要语言了。对英文来说,ubt-8编码为1字节,utf-16为2字节;对汉字来说(码点都在0xFFFF以内),按utf-8编码为3个字节,utf-16是2个字节。因此为了文档占有空间小,若文档中使用英文字符较多,应该使用utf-8;若文档中使用中文字符较多,应该使用utf-16
下一篇:android日记(十一)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号