

作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明。谢谢!
本文主要是翻译及整理MSRA 刘铁岩团队在NIPS 2016 会议上发表的论文“Dual Learning for Machine Translation”。对于论文中的算法思想可能还没有理解透彻,还请诸位大牛多多指教。
1 简介
最先进的机器翻译系统,包括基于短语的统计机器翻译方法、最近出现的基于神经网络的翻译方法,严重依赖于对齐的平行训练语料。然而,实际收集这些平行语料数据的代价非常大,因此语料的规模也往往有限,这将会限制相关的研究和应用。
我们知道在互联网中存在海量的单语数据,很自然的想到,能否利用它们去提升机器翻译系统的效果呢?实际上,基于这个想法,研究人员已经提出了许多不同的方法,这里可以粗略的分为两类。第一类,目标语言的单语语料被用于训练语言模型,然后集成到翻译模型(从平行双语语料中训练出)中,最终提升翻译质量。第二类,通过使用翻译模型(从对齐的平行语料中训练)从单语数据中生成伪双语句对,然后在后续的训练过程中,这些伪双语句对被用于扩充训练数据。尽管上述方法能够在一定程度上提升翻译系统的效果,但是它们依然存在一定的局限性。第一类的方法只使用了单语数据来训练语言模型,并没有解决平行训练数据不足这个问题。尽管第二类方法可以扩充平行训练数据,但是并不能保证伪双语句对的质量。
在这篇文章中,刘铁岩团队提出了一种Dual-Learning(对偶学习)机制,可以有效地利用单语数据(源语言与目标语言)。通过使用他们提出的机制,单语数据与平行双语数据扮演着相似的角色,在训练过程中,可以显著降低对平行双语数据的要求。对偶学习机制应用在机器翻译中,可以想象成两个agent(机器)在玩通信游戏,如下图所示,
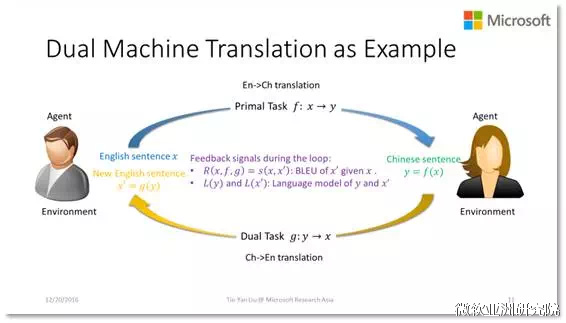
- 第一个机器,只理解语言A,通过噪声信道,发送一条信息(是语言A)给第二个机器,噪声信道通过翻译模型会将语言A转换成语言B;
- 第二个机器,只理解语言B,接收到翻译过来的信息(是语言B)。它检查这条信息,并通知第一个机器(第二个机器可能无法确认这个翻译的正确性,因为它不知道原始的消息)。然后,它通过另一个噪声信道(使用另外一个翻译模型,将接收到的消息从语言B转换为语言A)将接收到的信息发送给第一个机器。
- 从第二个机器接收到信息后,第一个机器会检查它,并通知第二个机器它接收到的信息是否包含它原来的信息。通过这个反馈,两个机器就可以知道这两个通信信道(也就是两个翻译模型)表现是否良好以及能否提高它们的效果。
- 这个游戏也可以从第二个机器开始,那么原始的消息就是语言B,这两个机器将会经过一个对称化的过程,通过反馈从而提高两个信道(翻译模型)的效果。
从上面的描述中,很容易发现,尽管两个机器可能没有对齐的双语语料,它们依然可以获得两个翻译模型的翻译质量方面的反馈,然后基于反馈持续提升模型的效果。这个游戏可以玩任意轮,两个翻译模型通过强化过程(例如,通过策略梯度方法)得到持续改善。通过这种方式,他们开发了一个通用的学习框架,通过对偶学习游戏,这个框架可用于训练机器翻译模型。
对偶学习机制很一些不同的特点。首先,我们通过强化学习从未标注数据中训练翻译模型。这个工作显著降低了对对齐双语数据的要求,它打开了一个新的窗口,可以从头开始(甚至不使用任何平行数据)学习一个翻译模型。实验结果显示,这个方法很有前景。
其次,显示出深度强化学习(DRL)在复杂真实世界中的应用,而不仅仅是在游戏这个领域。在最近几年,深度强化学习吸引了很多科研人员的注意力。但是,大部分应用还是集中在视频或者棋盘游戏,将深度强化学习应用到更加复杂的应用(规则没有事先定义好,并且没有明确的奖励信号),依然存在很大挑战。对偶学习提供了一种很有前景的方式,可以在真实世界应用中,例如,机器翻译,抽取出强化学习需要的奖励信号。
2 相关背景
对偶学习框架可以应用到基于短语的统计机器翻译和神经机器翻译中。在这篇文章中,我们主要聚焦在后者--神经机器翻译,因为它作为一个端到端的系统,很简单,不需要人工设计精巧的工程。
神经机器翻译系统通常是通过基于编码-解码框架的循环神经网络(RNN)来实现。这个框架从源语言句子 到目标语言 学习了一个概率映射 P(y|x),其中,xi 和 yt 分别是句子x的第i个词和句子y的第t个词。
更具体一些,神经机器翻译的编码器读取源语言句子 x ,然后基于RNN生成 个状态,
是时刻t的隐状态,函数f是循环单元,例如Long Short-Term Memory(LSTM)单元或者Grated Recurrent Unit(GRU)。然后,神经网络的解码器计算每个目标词 的条件概率,对于 ,已知它先前的词 和源语言句子,例如, 基于概率链式法则, 使用 来确定 。 如下列所示,
其中, 是解码器RNN在时刻t的隐状态,相似地,也是通过LSTM或者GRU进行计算; 根据编码器的隐状态定义了生成词 的上下文信息。 可以是句子 x 的全局信息,例如 , 或者是局部信息,局部信息通过注意力机制实现,例如 , 其中, 是一个前馈神经网络。
我们将神经网络中待优化的所有参数定义为 ,将用于训练的源语言-目标语言数据集定义为 D ,然后要学习的目标函数就是寻找最优的参数 。
3 对偶学习在机器翻译中的应用
在这章中,我们将会介绍对偶学习机制在神经机器翻译中的应用。注意到翻译任务经常是两个方向,我们首先设计一个有两个机器人的游戏,包含前向翻译步骤和反向翻译步骤,即使只使用单语数据,也可以给两个对偶翻译模型提供质量反馈。然后我们提出了对偶学习算法,称之为对偶神经机器翻译(简称dual-NMT),在游戏中,基于反馈回来的质量,提升两个翻译模型。
有两个单语语料 和 ,分别包含语言A和语言B的句子。需要注意的是,这两个语料并不需要互相对齐,甚至互相之间一点关系都没有。假设,我们右两个弱翻译模型,可以将句子从语言A翻译到语言B,反之亦然。我们的目标是使用单语语料而非平行语料来提高两个模型的准确率。从任何一个单语数据的句子开始,我们首先将其翻译为另一种语言,然后再将其翻译回原始语言。通过评估这两个翻译结果,我们将会了解到两个翻译模型的质量,并根据此来提升它们。这个过程可以迭代很多轮直到翻译模型收敛。
假设语料 有 个句子, 有 个句子。定义 和 为两个神经翻译模型,这里 和 是它们的参数(正如第2章中所描述)。
假设我们已经有两个训练好的语言模型 和 (很容易获得,因为它们只需要单语数据),每个语言模型获取一个句子作为输入,然后输出一个实数值,用于表示这个句子是它所属语言自然句子的自信度。这里,语言模型既可以使用其他资源,也可以仅仅使用单语数据 和 。
如果游戏是从 中的句子 s 开始 ,定义 作为中间翻译输出。这个中间步骤有一个中间的奖励 , 表示输出句子在语言 B 中的自然程度。已知中间翻译输出 ,我们使用从 还原过来的 s 的对数概率作为通信的奖励(我们将会交替使用重构和通信)。数学上定义, 奖励 。
我们简单采用语言模型奖励和通信奖励的线性组合作为整体奖励,例如, , 这里 是超参数。由于游戏的奖励可以视为s , 以及翻译模型 和 的函数,因此,我们可以通过策略梯度方法来优化翻译模型中的参数,从而达到奖励最大化,这个方法在强化学习中应用很广泛。
我们基于翻译模型 采样出 。然后我们计算期望奖励 关于参数 和 的梯度。根据策略梯度定理,很容易得到,
这里期望替换掉 。
基于公式(6)和公式(7),我们可以采用任何的采样方法来估计期望的梯度。考虑到随机采样将会带来非常大的方差,并且会导致机器翻译中出现不合理的结果,针对梯度计算,我们使用束搜索来获取更加有意义的结果(更加合理的中间翻译输出),例如,我们贪婪地产生top-K个高概率的中间翻译输出,然后使用束搜索的平均值来近似真实的梯度。如果游戏是在 中的句子 s 开始,梯度的计算就是一个对称,在此,我们忽略掉它。
游戏可以重复很多轮。在每一轮中,一个句子从 中采样,另一个句子是从 中采样,我们基于游戏(分别从两个句子开始)来更新这两个翻译模型。具体的细节在算法1中给出。

4 相关实验
我们做了一系列实验来测试提出的对偶学习机制在机器翻译上的效果。
4.1 实验设置
我们使用两个基准系统和对偶机器翻译方法进行对比,1)标准神经机器翻译(简称NMT),2)最近提出的基于NMT的方法,通过单语语料生成伪双语句对用于辅助训练(简称pseudo-NMT)。我们的所有实验都是使用Theano实现的辅助NMT系统来完成。
我们评估这些算法在一对翻译任务上的效果,包括英语翻译为法语(En->Fr)和法语到英语(Fr->En)。具体地,我们使用相同的双语语料,语料来源于WMT14,共有1200万句对。然后将newstest2012和newstest2013作为开发数据集,newstest2014作为测试数据集。WMT14 提供的“News Crawl:articles from 2012”作为单语数据。
我们使用GRU网络并遵循论文1(D. Bahdanau, K. Cho, and Y. Bengio. Neural machine translation by jointly learning to align
and translate. ICLR, 2015.)中的实践来设置实验参数。对于每种语言,我们用平行语料中最频繁的3万个词构造词汇表,将包含至少一个OOV单词的句子删除。每个词被映射到620维的连续向量空间,循环单元的维度是1000。我们将训练集中超过50个词的句子删除。batch的大小为80,每20个batch被预取,并按照句子长度排序。
对于基准的NMT模型,我们完全按照论文1提出的设置。对于基准的pseudo-NMT模型,我们使用训练好的NMT模型从单语数据中生成伪双语句对,删除超过50个词的句子,将生成的数据与原始平行训练数据融合在一起,然后训练这个模型,并用于测试。每个基准系统通过AdaDelta算法在K40m GPU进行训练,直到它们的效果在开发集上不再提升为止。
对偶神经机器翻译(简称dual-NMT)模型需要每种语言的语言模型。我们对于每种语言,使用相应的单语语料,训练了基于RNN的语言模型。实验中,语言模型就固定了,然后收到信息的对数似然作为通信信道(例如,翻译模型)的奖励。
在玩游戏时,我们使用暖启动翻译模型(已经从双语语料中训练出来的)来初始化信道,然后观察dual-NMT模型能否有效提升模型翻译准确率。在我们的实验中,为了从双语数据训练的初始模型平滑过渡到完全从单语数据训练的模型,我们采用了以下软着陆策略。在每次对偶学习过程的开始,对于每个mini batch,我们使用单语数据一半的句子和双语数据(从数据中采样出来的用于训练初始模型)中一半的句子。目标就是基于单语数据最大化奖励(在第3部分定义的)的加权之和以及基于双语数据的似然度(在第2部分定义)。随着训练过程的持续,我们逐渐在mini batch中增加单语数据的比例,直到完全不使用双语数据。这里,我们在实验中测试了两个测试:
- 第一个设置(参考Large),我们在软着陆阶段,使用全部的1200万双语句对。也就是,暖启动模型是基于全部双语数据进行学习的;
- 第二个设置(参考Small),我们在1200万双语句对中随机采样了10%的数据,并在软着陆阶段使用它;
对于每个设置,我们都是训练对偶机器翻译算法一周。我们在中间翻译过程中设置束搜索大小为2。实验中的所有超参数通过交叉验证来设置。我们使用BLEU作为评估标准,由moses提供的 脚本工具 进行计算。遵循常规的实践,在测试阶段,如同先前许多的工作,我们对于所有的算法均使用大小为12的束搜索。
4.2 实验结果分析
我们在这部分分析实验结果。回忆之前提到的两个基线系统,英语->法语和法语->英语是分别训练的,但是,dual-NMT系统一起训练这两个基线系统。我们在表1中总结了所有系统的效果,在源语言句子的各个长度上的BLEU分值曲线在图1中画出。
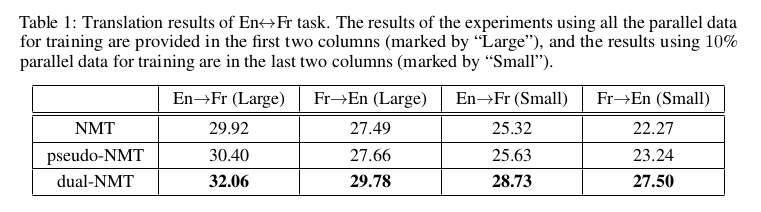
从表1中,我们可以看到dual-NMT系统在所有的设置中均超过了基线系统。在从英语翻译为法语的任务上,dual-NMT系统分别在第一种/第二种暖启动方式超过基线NMT系统大约2.1/3.4个百分点,超过pseudo-NMT大约1.7/3.1个百分点。在从法语翻译为英语的任务上,提升更加显著,dual-NMT系统在第一个/第二个暖启动方式上分别超过NMT大约2.3/5.2个百分点,超过pseudo-NMT大约2.1/4.3个百分点。令人惊讶的是,在只有10%的双语数据上法语翻译为英语的任务中,相比使用100%的常规NMT系统,dual-NMT取得了可比的翻译正确率。这些结果显示了dual-NMT算法的有效性。另外,我们也观察到如下结果:
- 尽管pseudo-NMT的效果超过NMT,它的提升并不显著。我们认为,可能是从单语数据中生成的伪双语句对质量不好,这个限制了pseudo-NMT的效果提升。需要注意的就是需要仔细选择和过滤生成的伪双语句对,以便pseudo-NMT可以取得更好的效果;
- 当平行双语数据较少时,dual-NMT可以有更大的提升。这个显示了对偶学习机器可以很好的利用单语数据。因此,我们认为dual-NMT在较少的有标签平行数据和更大的单语句对上更有用。dual-NMT打开了一个新的窗口,可以从头开始学习一个翻译模型。
我们在源语言句子的各个长度上的BLEU分值曲线在图1中画出。从这个图中,我们可以看出dual-NMT算法在所有的长度上超过了基准系统。
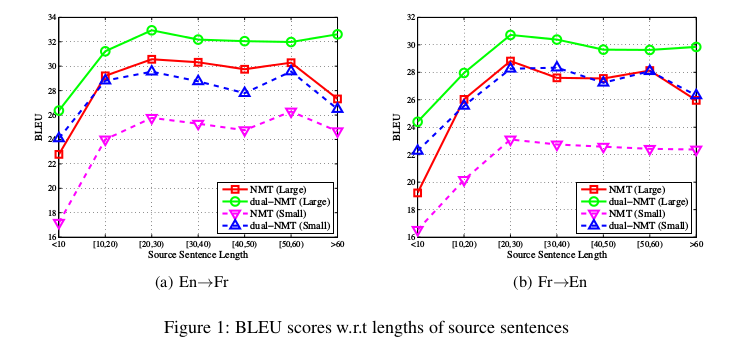
我们对dual-NMT算法做了一些更深入的研究,如表2所示。我们研究了各个算法的重构后的效果:对于测试集的每个句子,我们将它翻译到第4次并返回,然后使用BLEU分值来检查返回的翻译句子。我们使用束搜索生成所有的翻译结果。很容易地从表2中观察到,dual-NMT的重构后的BLEU分数比NMT和pseudo-NMT更高。实际上,在从大规模平行数据上训练的暖启动模型上,dual-NMT超出NMT大约11.9/9.6,在10%数据上训练的暖启动模型上,dual-NMT超出NMT大约20.7/17.8。
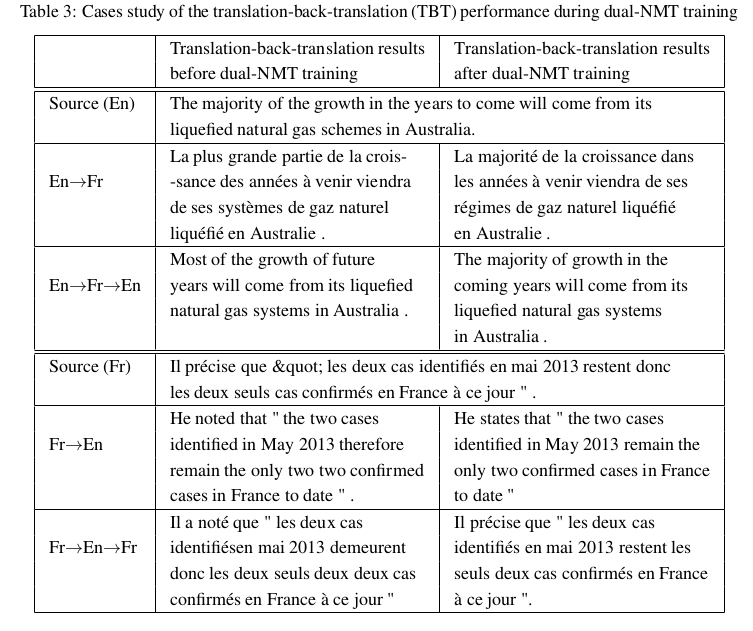
我们在表3上列出了几个例句,用于对比使用对偶学习之前和之后模型的重构结果。很明显,在对偶学习之后,重构的效果在两个方向(英语->法语->英语,法语->英语->法语)上都有很大提升。
总之,所有的结果均显示出对偶学习机器很有前景并且可以更好地利用单语数据。
5 扩展
在这部分,我们讨论对偶学习机制可能的扩展。
首先,尽管在我们在这篇文章中集中在机器翻译任务上,但是对偶学习的基本思想具有通用的应用性:只要两个任务具备对偶形式,我们就可以利用强化学习算法将对偶机学习机制应用到从未标注数据中同时学习两个任务。实际上,许多人工智能任务天然的是对偶形式,例如,语音识别和语音合成,图像抓取和图像合成,问题回答和问题生成,搜索(匹配查询词与文档的相似度)和关键词抽取(从文档中抽取关键字/查询词)等等。对于更多的对偶任务,而不仅仅是机器翻译,设计和测试对偶学习算法将会很有意义。
第二,尽管我们将对偶学习集中在两个任务上,但是我们的技术并不仅仅局限在两个任务。实际上,我们主要的想法是形成一个闭环,目的是我们通过比较原始输入数据和最终输出数据,能够提取出反馈信号。因此,如果有多于两个相关的任务可以形成闭环,我们可以应用这个技术来提升每个任务在无标签数据的效果。例如,对于英语句子 x ,我们可以先将它翻译为中文句子 y ,然后将 y 翻译为法语句子 z ,最终再将 z 翻译为英文句子 。句子 x 和 的相似度可以表示闭环中三个翻译模型的有效性,我们基于闭环中的反馈信号可以再次使用策略梯度方法来更新和提升这些模型。我们更愿意将这种通用的对偶学习命名为闭环学习,并且在未来会测试它的有效性。
6 展望
我们计划在后续探索如下的方向,第一,在实验中,我们使用了双语数据用于暖启动dual-NMT的训练。更加激动的方向就是从头学习,例如,直接从两种语言的单语数据(可能需要词汇词典)开始学习。第二,dual-NMT是基于NMT系统的,我们基本的想法也可以用于基于短语的统计机器翻译系统中,我们将会探索这个方向。第三,我们仅仅考虑一对语言,我们将会进行扩展,使用单语数据,联合训练至少3种语言的翻译模型。
7 从控制系统的角度思考对偶学习
在第5章中,提到了对偶学习可以视为一个闭环学习。闭环学习的概念来源于反馈控制系统。反馈控制系统,输入信号经过控制器、执行器,得到输出信号,然后再将输出信号采集回来,输入信号减去采集回来的输出信号,得到误差,根据误差来调节控制器,使得输出能够跟随输入信号。
对偶神经机器翻译系统可以视为一个反馈控制系统,这里以中文翻译为英文,再将英文翻译为中文为例。
- 通过中->英翻译模型将中文翻译为英文,就是将输入信号通过控制器、执行器,转换为输出信号,也就是英文;
- 通过英->中翻译模型将英文翻译为中文,就是将输出信号通过信号采集器返回给输入端,转换为与输入信号同等量纲的信号,也即中文;
- 通过指标,比较原始中文与翻译过来的中文的相似性,来评估两个翻译模型的效果,也就是计算输入信号与采集回来的信号之间的误差,从而通过控制器的调节,调整输出信号的变化;
循环迭代,直到输出信号能够跟随输入信号。
在控制系统的设计中,需要考虑三个指标:
- 稳定性
- 准确性
- 快速性
分别将这三个指标对应到对偶机器翻译系统中,
- 稳定性就是对偶机器翻译系统中两个翻译模型的稳定性,如果翻译系统存在漏翻译、翻译质量低等问题,能否在迭代过程中逐渐改善?如果不能得到改善,将会导致翻译质量会越来越低,而非越来越好,这个系统就会逐渐的变差,也就是这个系统是不稳定的。
- 准确性,也就是对偶机器翻译系统最终稳定时,翻译质量能达到多少?
- 快速性,如果对偶翻译系统需要达到一个期望的准确度,需要多少时间能达到?另外,如果要超越NMT基线系统,需要多少时间?
因此,我们可以发现,对偶机器翻译系统是反馈控制系统的一个特例,对偶机器翻译系统在设计时,同反馈控制系统一样,需要考虑稳定性、准确性和快速性三个指标。很期待对偶学习以及其在机器翻译领域的发展。
8 Reference
Di He, Yingce Xia, Tao Qin, Liwei Wang, Nenghai Yu, Tie-Yan Liu, and Wei-Ying Ma , Dual Learning for Machine Translation , NIPS 2016.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!