HDFS
简介
定义:
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
优点:
- 高容错性
- 数据自动保存多个副本,通过增加副本的形式,提高容错性
- 某一个副本丢失以后,他可以自动恢复
- 适合处理大数据
- 数据规模:GB,TB,PB
- 文件规模:处理百万规模以上的文件数量
- 可构建在廉价机器上,通过多副本机制,提高可靠性
缺点:
- 不适合低延时的数据访问,比如毫秒级的数据存储
- 对大量小文件进行存储很低效
- 存储大量的小文件,会占用NameNode大量的内存来存储文件目录和块信息,但NameNode的内存是有限的
- 小文件的寻址时间会超出读取时间,违反了HDFS的设计目标
- 不支持并发写入、文件的随机修改
- 一个文件只能有一个写,不允许多个线程同时写
- 仅支持数据append,不支持文件的svjixqg
组成架构
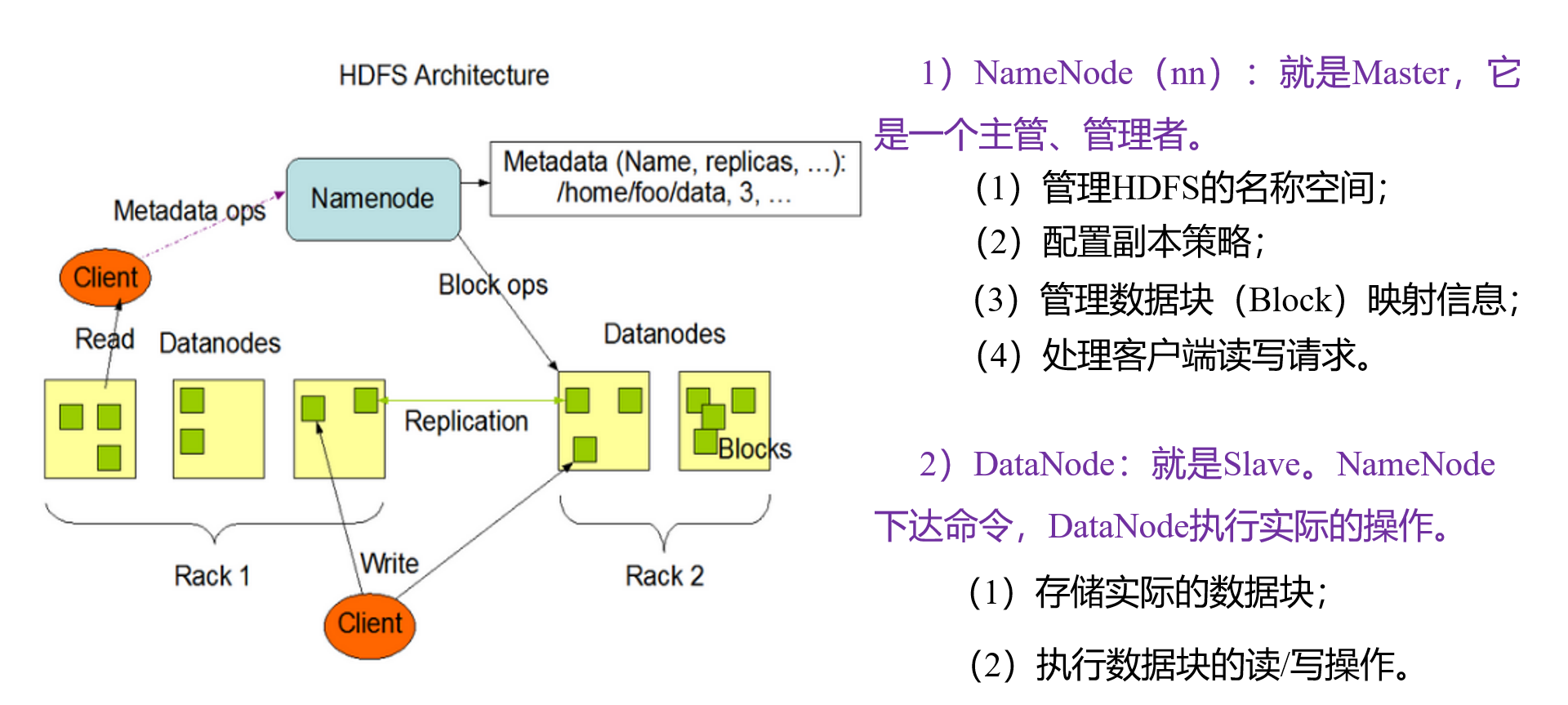

文件块大小
- 块设置太小,会增加寻址时间,程序一直在找块的开始位置
- 设置太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间,导致程序在处理这块数据时会非常慢。
HDFS块的大小设置主要取决于磁盘传输速度
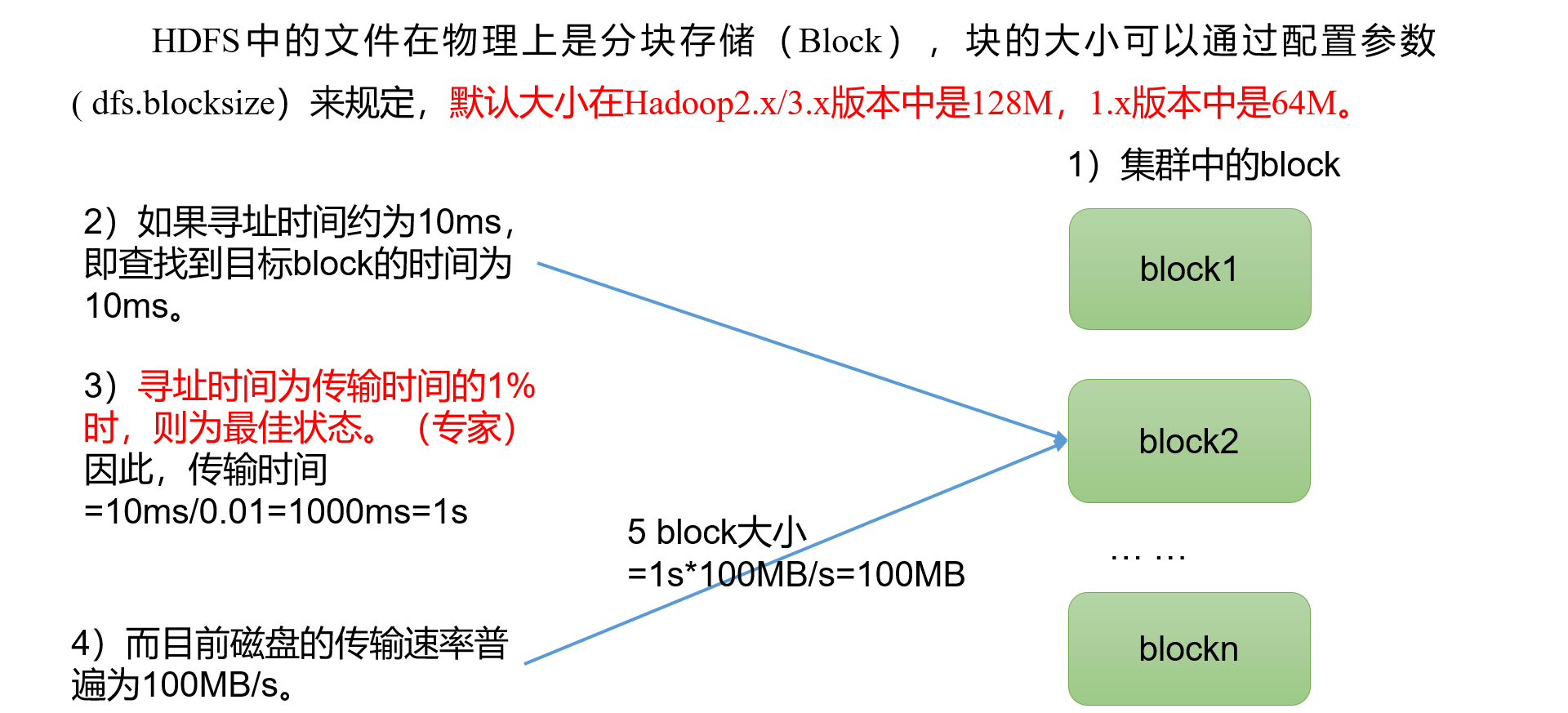
读写流程
写#
- 客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
- NameNode返回是否可以上传。
- 客户端请求第一个 Block上传到哪几个DataNode服务器上。
- NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
- 客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成
- dn1、dn2、dn3逐级应答客户端。
- 客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答
- 当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)
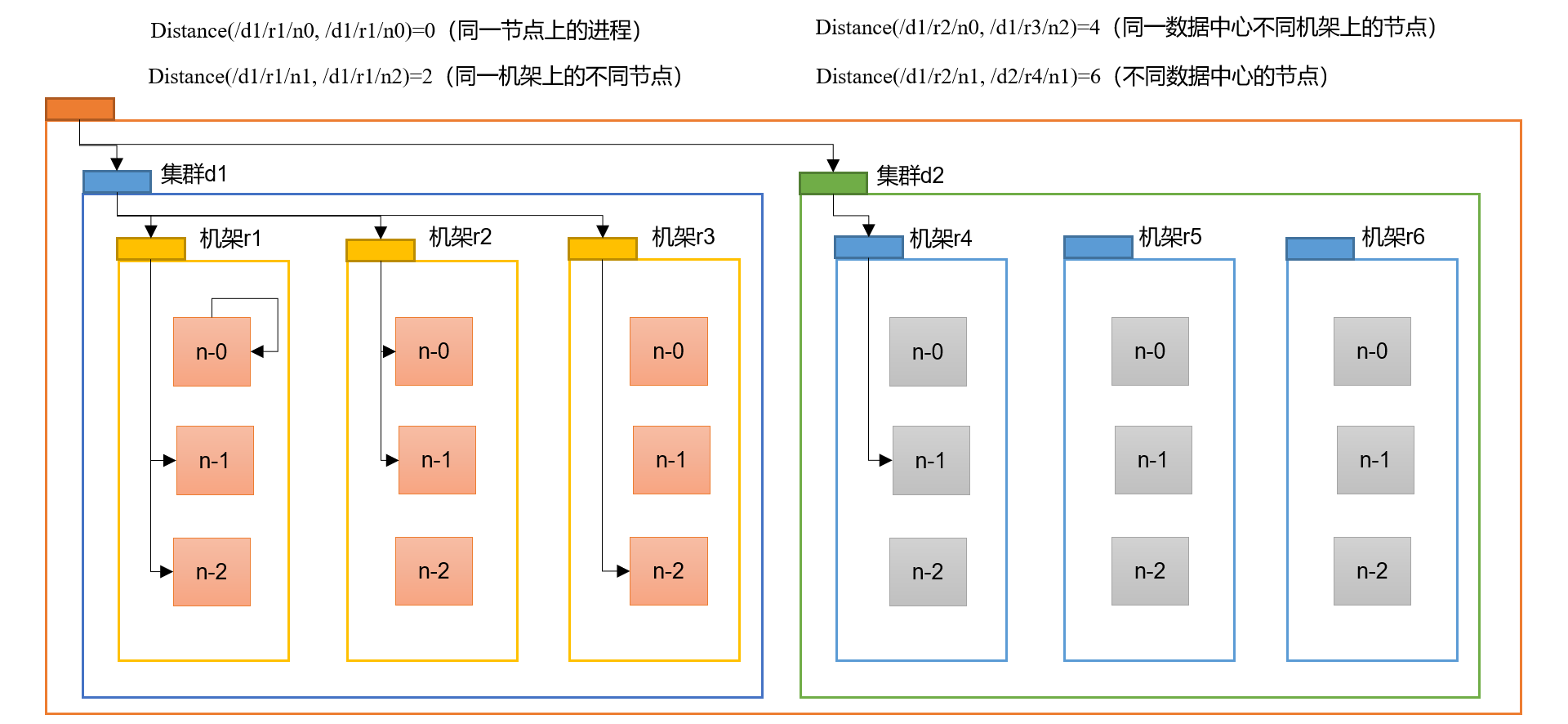
网络拓扑-节点距离计算#
在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据
节点距离:两个节点到达最近的共同祖先的距离总和。
可以理解为二叉树最近的公共祖先
机架感知(副本存储节点选择)#
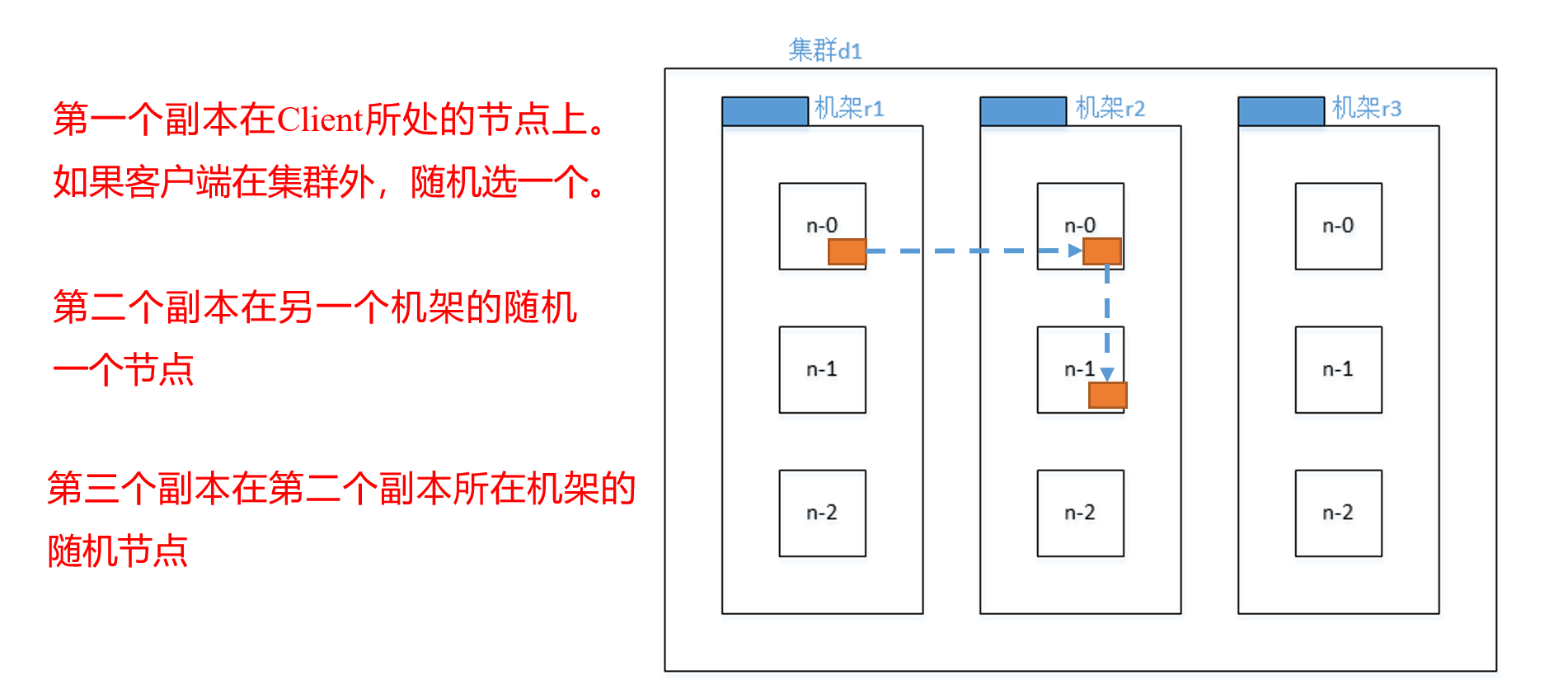
- 第一个副本选在Client上,因为在本地速度会快
- 第二个在另一个机架的随机节点,因为保证可靠性
- 第三个还是在第二个副本的地方,因为这样比较有效率
读#
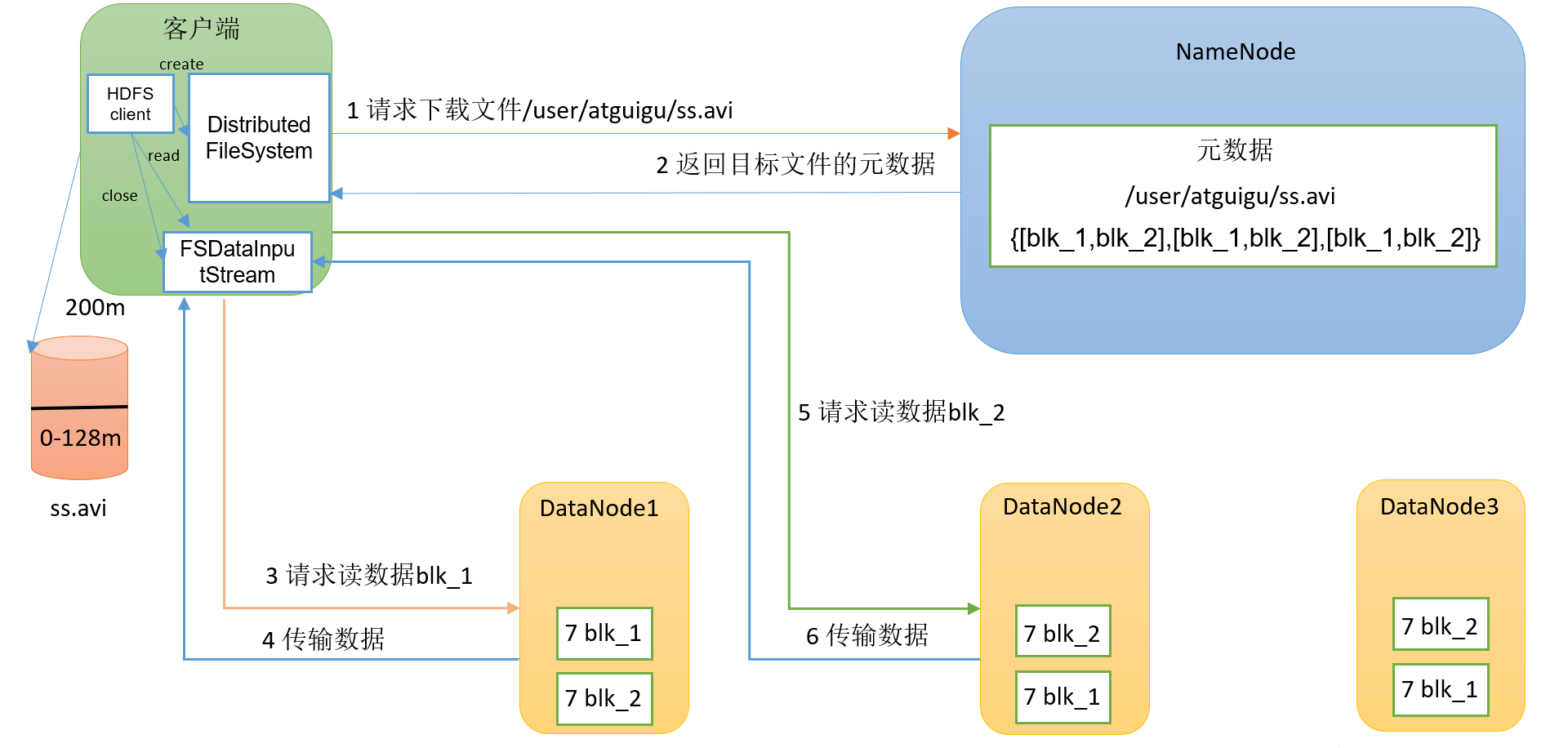
- 客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
- 挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
- DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)
- 客户端以Packet为单位接收,先在本地缓存,然后写入目标文件
作者:Zhbeii
出处:https://www.cnblogs.com/zhbeii/p/15823053.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?