数据仓库建模
ODS层
是原始数据,存储总HDFS上
- 保持原数据不做修改,起到备份数据的作用
- 压缩数据,减少磁盘存储空间(lzo)
- 创建分区表,防止后续的全表扫描
LZO压缩:
解压速度非常快
允许在压缩部分以损失压缩速度为代价提高压缩率,解压速度不会降低。
算法无损,线程安全
DIM和DWD层
需构建维度模型,一般采用星型模型,呈现的状态一般为星座模型
维度建模的过程:
- 选择业务
一条业务线对应一张事实表 - 声明粒度
精确定义事实表中的一行数据表示什么,应该尽可能选择最小粒度,以此来应各种各样的需求。
eg:
支付事实表中一行数据表示的是一个支付记录。
订单事实表中一行数据表示的是一个订单中的一个商品项。 - 确定维度:
维度的主要作用是描述业务是事实,主要表示的是“谁,何处,何时”等信息。
确定维度的原则是:后续需求中是否要分析相关维度的指标。例如,需要统计,什么时间下的订单多,哪个地区下的订单多,哪个用户下的订单多。需要确定的维度就包括:时间维度、地区维度、用户维度。 - 确定事实
此处的“事实”一词,指的是业务中的度量值(次数、个数、件数、金额,可以进行累加),例如订单金额、下单次数等。
在DWD层,以业务过程为建模驱动,基于每个具体业务过程的特点,构建最细粒度的明细层事实表。事实表可做适当的宽表化处理。
事实表和维度表的关联比较灵活,但是为了应对更复杂的业务需求,可以将能关联上的表尽量关联上。
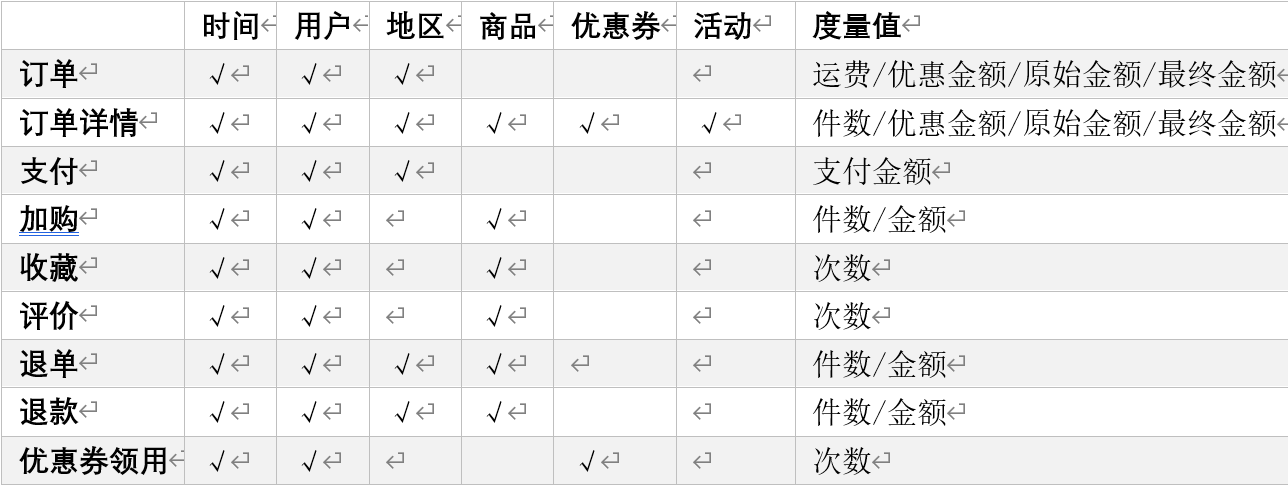
至此,数据仓库的维度建模已经完毕,DWD层是以业务过程为驱动。
DWS层、DWT层和ADS层都是以需求为驱动,和维度建模已经没有关系了。
DWS和DWT都是建宽表,按照主题去建表。主题相当于观察问题的角度。对应着维度表。
DWS层与DWT层
DWS层和DWT层统称宽表层,这两层的设计思想大致相同
- 问题引出:两个需求,统计每个省份订单的个数、统计每个省份订单的总金额
- 处理办法:都是将省份表和订单表进行join,group by省份,然后计算。同样数据被计算了两次,实际上类似的场景还会更多
那怎么设计能避免重复计算呢?
针对上述场景,可以设计一张地区宽表,其主键为地区ID,字段包含为:下单次数、下单金额、支付次数、支付金额等。上述所有指标都统一进行计算,并将结果保存在该宽表中,这样就能有效避免数据的重复计算。 - 总结:
- 需要建哪些宽表:以维度为基准。
- 宽表里面的字段:是站在不同维度的角度去看事实表,重点关注事实表聚合后的度量值。
- DWS和DWT层的区别:DWS层存放的所有主题对象当天的汇总行为,例如每个地区当天的下单次数,下单金额等,DWT层存放的是所有主题对象的累积行为,例如每个地区最近7天(15天、30天、60天)的下单次数、下单金额等。
ADS层
对电商系统各大主题指标分别进行分析。
作者:Zhbeii
出处:https://www.cnblogs.com/zhbeii/p/15800200.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?