RDD的持久化
RDD Cache缓存
RDD 通过 Cache 或者 Persist 方法将前面的计算结果缓存,默认情况下会把数据以缓存在 JVM 的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 算子时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用
存储级别:
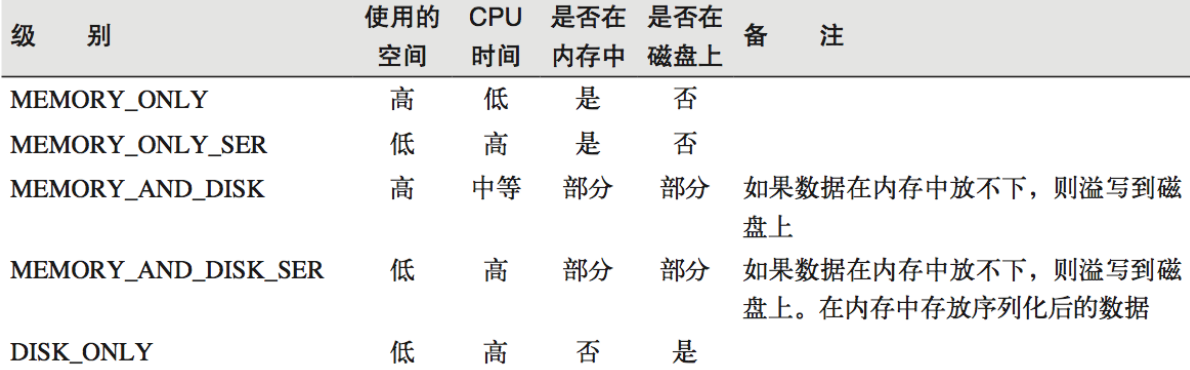
如果级别名字后面加上后缀_2,每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。
如果内存充足,要使用双副本高可靠机制
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD 的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于 RDD 的一系列转换,丢失的数据会被重算,由于 RDD 的各个Partition 是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部 Partition。
Spark 会自动对一些 Shuffle 操作的中间数据做持久化操作(比如:reduceByKey)。这样做的目的是为了当一个节点 Shuffle 失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用 persist 或 cache。
RDD CheckPoint检查点
将RDD的中间结果写入次品,当血缘依赖过长时,会造成容错成本过高
如果在中间阶段做检查点容错,即:
如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销
对 RDD 进行 checkpoint 操作并不会马上被执行,必须执行 Action 操作才能触发
缓存和检查点的区别
- Cache 缓存只是将数据保存起来,不切断血缘依赖。Checkpoint 检查点切断血缘依赖
- Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint 的数据通常存,储在 HDFS 等容错、高可用的文件系统,可靠性高。
- 建议对 checkpoint()的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存,中读取数据即可,否则需要再从头计算一次 RDD中读取数据即可,否则需要再从头计算一次 RDD

 浙公网安备 33010602011771号
浙公网安备 33010602011771号