随笔分类 - 离线数仓
摘要:代码埋点:通过调用埋点SDK函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据。例如,我们对页面中的某个按钮埋点后,当这个按钮被点击时,可以在这个按钮对应的 OnClick 函数里面调用SDK提供的数据发送接口,来发送数据 可视化埋点:需要研发人员集成采集 SDK,不需要写埋点代码,业务人员就
阅读全文
摘要: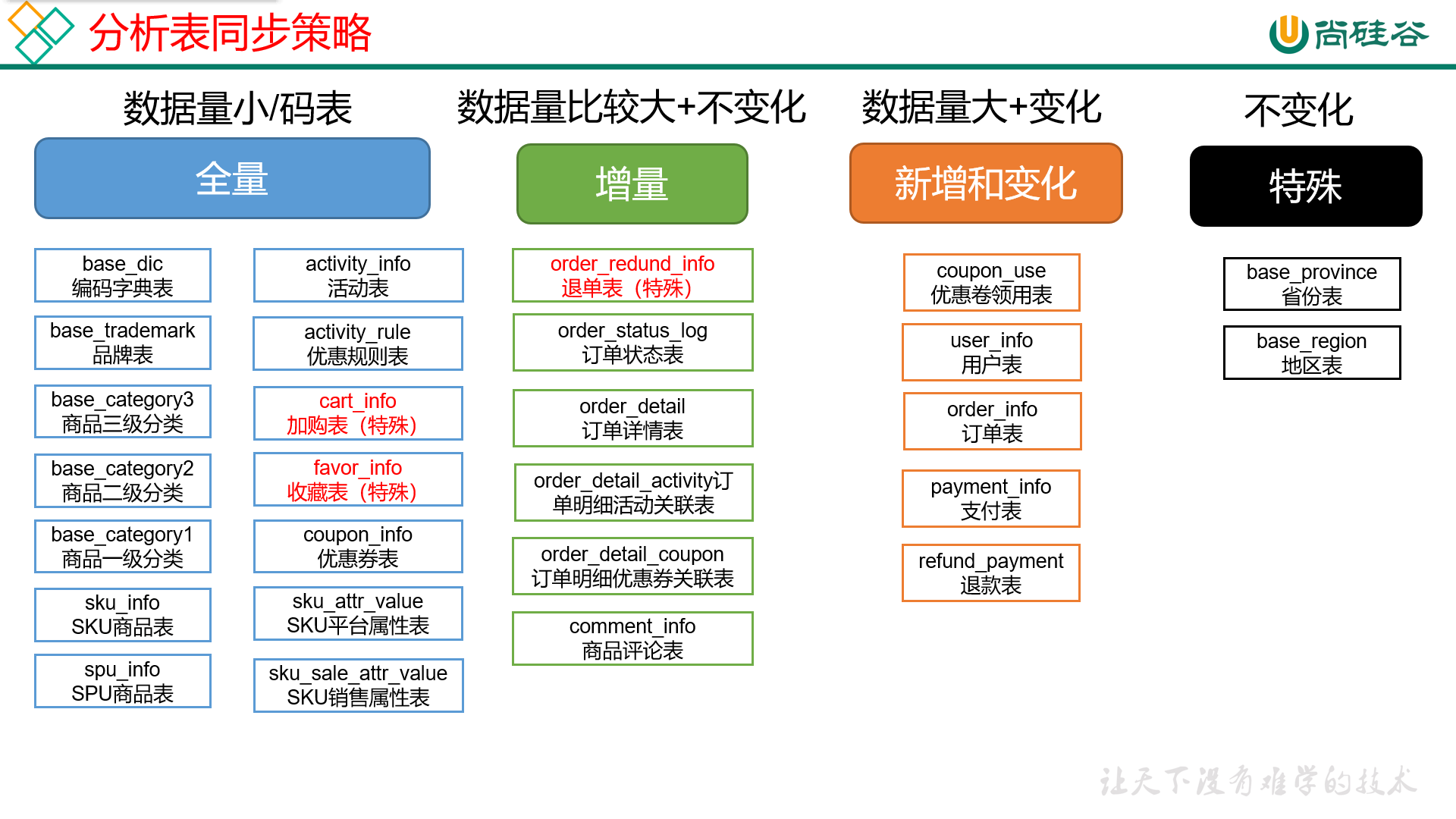
阅读全文
摘要:教程:https://zhuanlan.zhihu.com/p/264346586 (1)单引号不取变量值 (2)双引号取变量值 (3)反引号`,执行引号中命令 (4)双引号内部嵌套单引号,取出变量值 (5)单引号内部嵌套双引号,不取出变量值
阅读全文
摘要:ODS层 是原始数据,存储总HDFS上 保持原数据不做修改,起到备份数据的作用 压缩数据,减少磁盘存储空间(lzo) 创建分区表,防止后续的全表扫描 LZO压缩: 解压速度非常快 允许在压缩部分以损失压缩速度为代价提高压缩率,解压速度不会降低。 算法无损,线程安全 DIM和DWD层 需构建维度模型,
阅读全文
摘要:分层 为什么要分层 把复杂问题简单化:将复杂的任务分解成多层来完成,每一层只处理简单的任务,方便定位问题 减少重复的开发:规范数据分层,通过的中间层数据,能够减少极大的重复计算,增加一次计算结果的复用性 隔离原始数据:不论是数据的异常还是数据的敏感性,使真实数据与统计数据解耦开 数仓命名规范 表命名
阅读全文
摘要:Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。在导出数据时采用--input-null-string和--input-null-non-string两个参数。导入数据时采用--null-string和--null-non-stri
阅读全文
摘要:sqoop 是“Hadoop中的各种存储系统(HDFS、HIVE、HBASE) 和关系数据库(mysql、oracle、sqlserver等)服务器之间传送数据”的工具。 导入数据:MySQL,Oracle 导入数据到 Hadoop 的 HDFS、HIVE、HBASE 等数据存储系统 导出数据:从
阅读全文
摘要:SPU:Xiaomi12 SKU:颜色+内存+网络 Xiaomi12 SKU = Stock Keeping Unit(库存量基本单位)。现在已经被引申为产品统一编号的简称,每种产品均对应有唯一的SKU号 SPU(Standard Product Unit):是商品信息聚合的最小单位,是一组可复用、
阅读全文
摘要:原因 在执行shuffle操作的时候,是按照key,来进行values的数据的输出、拉取和聚合的。 同一个key的values,一定是分配到一个reduce task进行处理的。 多个key对应的values,假设是90万。但是问题是,可能某个key对应了88万数据,key-88万values,分配
阅读全文
摘要:记录每条信息的生命周期:一单一条记录的生命周期结束,就重新开始一条新的记录,并把当前日期放入生效开始日期 如果信息当前还有效,就在生效结束日期中填入一个极大值(9999-99-99)
阅读全文
摘要:维度表: 一般是对事实的描述信息。每一张维表对应现实世界中的一个对象或者概念。 例如:用户、商品、日期、地区等 特征: 维表的范围很宽(具有多个属性、列比较多) 跟事实表相比,行数相对较小:通常< 10万条 内容相对固定:编码表 事实表 事实表中的每行数据代表一个业务事件(下单、支付、退款、评价等)
阅读全文
摘要:关系建模将复杂的数据抽象为两个概念——实体和关系,并使用规范化的方式表示出来。 关系模型严格遵循第三范式(3NF),数据冗余程度低,数据的一致性容易得到保证。由于数据分布于众多的表中,查询会相对复杂,在大数据的场景下,查询效率相对较低 eg: 维度模型以数据分析作为出发点,不遵循三范式,故数据存在一
阅读全文
摘要:图来自尚硅谷 函数依赖 第一范式核心原则:属性不可切割 eg: 第二范式核心原则:不能存在(非主键字段)部分函数依赖于(主键字段) 第二范式核心原则:不能存在传递函数依赖
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号