随笔分类 - Spark
摘要: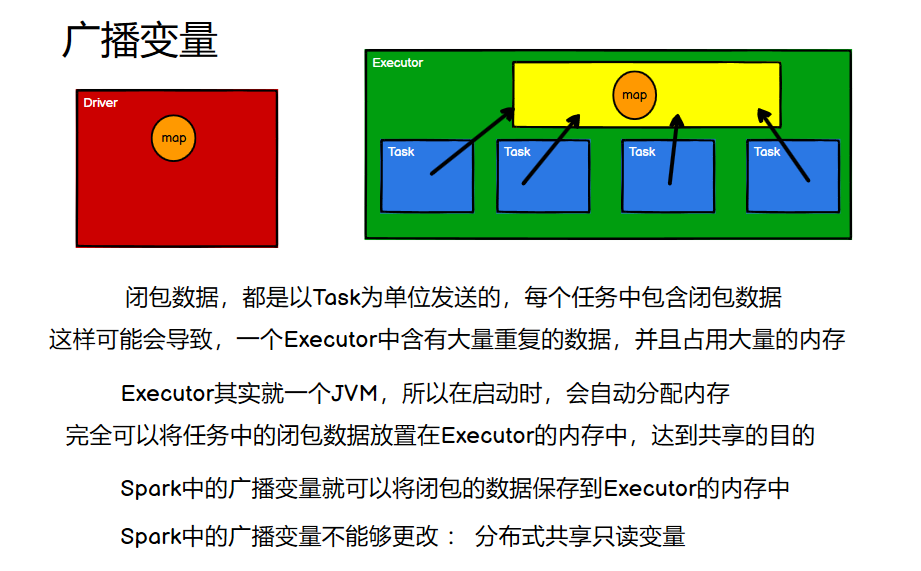
阅读全文
摘要:默认采用的是Hash分区 缺点:可能导致每个分区中数据量的不均匀,极端情况下会导致某些分区拥有RDD的全部数据 Ranger分区 要求RDD中的KEY类型必须可以排序 自定义分区 根据需求,自定义分区
阅读全文
摘要:**窄依赖:**窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用 **宽依赖:**宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会引起 Shuffle
阅读全文
摘要:Java 的序列化能够序列化任何的类。但是比较重(字节多),序列化后,对象的提交也比较大。Spark 出于性能的考虑,Spark2.0 开始支持另外一种 Kryo 序列化机制。Kryo 速度是 Serializable 的 10 倍。当 RDD 在 Shuffle 数据的时候,简单数据类型、数组和字
阅读全文
摘要:Spark的transformation算子(不少于8个)(重点) 单Value (1)map:将处理的数据逐条进行映射转换,这里的转换可以是类型的转换,也可以是值的转换 (2)mapPartitions:将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤
阅读全文
摘要:https://blog.csdn.net/erfucun/article/details/52275369 https://blog.csdn.net/matrix_google/article/details/80033524
阅读全文
摘要:RDD的基本性质 RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。 弹性 存储的弹性:内存与磁盘的自动切换 容错的弹性:数据丢失可以自动恢复 计算的弹性:计算出错重试机制 分片的弹性:可根据需要重新分片 分布式 数据集
阅读全文
摘要:Spark 框架有两个核心组件:Driver和Executor **Driver:**驱动整个应用运行起来的程序,也叫Driver类 将用户程序转化为作业(job) 在 Executor 之间调度任务(task) 跟踪 Executor 的执行情况 通过 UI 展示查询运行情况 Executor:
阅读全文
摘要:从集合(内存)中创建 RDD 从底层代码实现来讲,makeRDD 方法其实就是 parallelize 方法 val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark") val sparkContext = ne
阅读全文
摘要:累加器用来把 Executor 端变量信息聚合到 Driver 端。在 Driver 程序中定义的变量,在Executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 task 更新这些副本的值后,传回 Driver 端进行 merge。 从Accumulator中,获取数据,插入数据
阅读全文
摘要:RDD Cache缓存 RDD 通过 Cache 或者 Persist 方法将前面的计算结果缓存,默认情况下会把数据以缓存在 JVM 的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 算子时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用 存储级别: 如果级别名
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号