
[标点符...] 机器学习算法之XGBoost -什么是XGBoost? -优势&运算流程 -算法原理&数学原理 -一棵树的生成细节 -主要参数介绍
引用&搬运
- https://www.biaodianfu.com/xgboost.html 机器学习算法之XGBoost
- https://zhuanlan.zhihu.com/p/92837676 XGBoost、GBDT超详细的数学公式推导 (这一部分涉及大量的运算,写到了笔记本上,博客未同步)
- https://www.cnblogs.com/TimVerion/p/11436001.html XGBoost 重要参数(调参使用)
01 什么是XGBoost?
- 全称:extreme Gradient Boosting (极端梯度提升算法)
- 基础: GBDT (梯度boosting迭代形、树模型)
- 适用范围:分类、回归
- 优点: 速度快、效果好、支持自定义Loss函数
- 缺点:算法参数过多,需要调参,不适合处理超高维度特征的数据(慢!)
- 项目地址:https://github.com/dmlc/xgboost
02 复习 & XGBoot的优势
复习
- DT:decision tree,决策时
- boosting:组合多个基(弱)学习器,组合成一个强学习器
值得一提的是 Boosting 有三个要素:
1. 损失函数:如分类问题使用交叉熵(cross entropy),回归问题使用的是均方差(mean squared error)
2. A weak learner to make predictions:例如决策树。
3. 一个具有累加性的模型:组合多个基(弱)学习器,组合成一个强学习器,从而不断减少目标的损失函数 - gradient boosting:梯度提升算法,在boosting组合弱学习器的时候
- gradient boosting的实现比较慢的原因是:因为每次都要先构造一个树模型并添加到整个模型序列中,然后使用梯度下降算法来降低损失函数,模型融合
XGBoot的优势
-
正则化:
- xgboost在代价函数中增加了正则项,用于控制模型的复杂度;
- 正则化作用:降低了模型的方差(variance),使学习出来的模型更加简单,防止过拟合;普通的GBDT没有这个特性
- 正则项:包含了树的叶子节点个数、每个叶子结点上输出的score的L2模的平方和
- 正则项的计算公式:
- L1和L2的区别:
-
xgboost支持并行
- 普通GBDT:是以树粒度进行串行的(boosting)
- xgb:也是以树粒度进行串行的,xgboost也是一轮迭代完毕才能进行下一轮;
- 决策树:决策树学习最耗时的步骤是在对特征值进行排序的时候(因为需要确定最佳的切割点)
- xgb并行是在特征粒度上的,xgboost在训练之前,预先对数据进行了排序,然后保存为bolck结构,后面的迭代中重复使用这个结构,大大减少了计算量;这个block结构为
并行提供了可能;在节点分裂的时候,需要计算每个特征的增益,最终选择增益最大的那个特征去做分裂,那么每个特征的增益都可以开多线程进行计算。 - 高度的灵活性,XGBoost支持用户自定义目标函数和评估函数,只要目标函数二阶可导就行。
- 缺失值处理。内置缺失值的处理逻辑,可以进行学习,需要指定该缺失值的类型
- 剪枝:当分裂时(最佳的分裂选择就是)遇到一个负损失时,XGBoost会一直分裂到指定的最大深度(max_depth),然后再回过头来剪枝,如果某个节点之后不再有正值,它会去除这个分裂(减少无用的分数);而GBDT会遇见负的损失后,就不再深入搜索——容易造成局部最优解。如当一个负损失(如-2)后面有个正损失(如+10)的时候,GBM会在-2分处停止下来,XGBoot只要深度允许会得到-2+10=+8分。
- 内置交叉验证
03 XGBoost算法原理知识 & 数学原理
xgboost算法的内部的决策树使用的是回归树
回归树的分裂特点: (不懂装懂~~~~~~~~~~~~~~~~~~~~~~~)
对于平方损失函数,拟合的就是残差;
对于一般损失函数(梯度下降),拟合的就是残差的近似值,分裂结点划分时枚举所有特征的值,选取划分点。
最后预测的结果是每棵树的预测结果相加。
xgboost的分裂特点之寻找分裂结点的候选集
- 暴力枚举
- 近似方法, 近似方法通过特征的分布,按照百分比(分位数)来确定一组候选分裂点,然后遍历所有的候选分裂点来确定最佳的分裂点.
- 陈天奇提出并从概率角度证明了一种带权重的分布式的Weighted Quantile Sketch (加权 分位数 概述) (不懂装懂~~~~~~~~~~~~~~~~~~~~~~~)

04 xgboost的一棵树的生成细节 (https://zhuanlan.zhihu.com/p/92837676)
1. 分裂一个结点
当建立第t棵树的时候,XGBoost采用贪心法进行树节点的分裂
a.对树中的每个叶子结点尝试进行分裂
b.每次分裂后, 原来的一个叶子结点继续分裂为左右两个叶子结点,原来的叶子结点中的样本集将根据该结点的判断规则分散到左右两个叶子结点
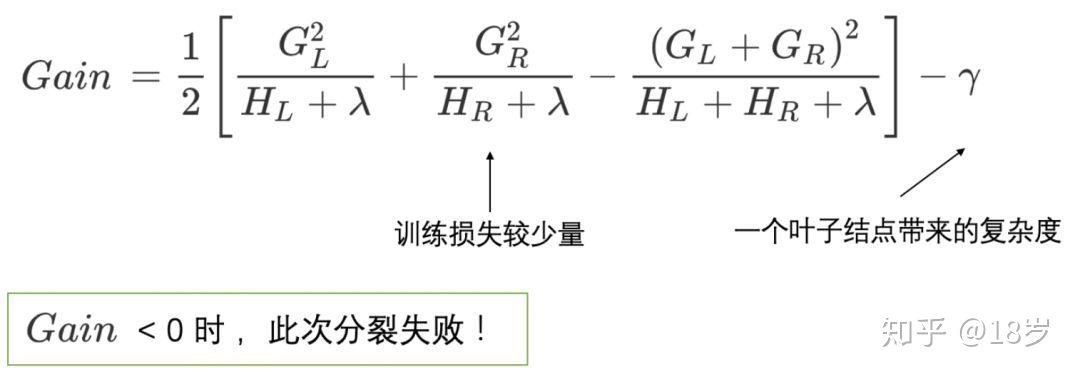
c.新分裂一个结点, 需要判断这次分裂是否会给损失函数带来增益,增益定义如下:
- 即: 不分裂的目标函数 - (左节点的目标函数 + 右节点的目标函数) - 分裂两个结点造成的复杂度增加
- 注: 目标函数 = 损失函数+树的复杂度

d. 如果结点的增益Gain > 0, 则目标函数下降, 正向, 可以考虑进行分裂.
e. 接下来寻找多个增益中的最佳分裂点
2. 寻找最佳分裂点 以及 XGBoost的优化 https://zhuanlan.zhihu.com/p/92837676
当前待分裂的结点存在多个特征可供分裂,如BCD三个特征,如下:
a.遍历每个结点的每个特征
b.对每个特征进行一次排序
c.线性扫描每个特征值, 找出每个特征的最佳分裂点 (即是分裂后目标函数增益最大的那个特征以及特征的分裂点的特征值)
XGBoost提出了一系列加快寻找最佳分裂点的方案:
- **特征预排序+缓存: ** 将每个特征进行预排序, 保存为block结构,后面迭代中可以重复使用这个结构
- 分位点近似法: 类似于lgb的箱型图结——仅仅选出常数个的特征值作为该特征的候选分割点
- 并行查找: xgboost可以利用多个线程来并行利用block结构,加快增益的计算
3. 停止生长 https://zhuanlan.zhihu.com/p/92837676
a. 先从顶到底建立所有可行的最优的分支;然后再自顶部向底部开始剪枝;当新引入的一次分裂所带来的增益Gain<0时,放弃当前的分裂(剪掉)。这是训练损失和模型结构复杂度的博弈过程。
b. 树深度的限制
c. 超参数:最小样本权重和的限制 不可低于每个叶子结点的样本权值和,防止过细,限制最低的
4. 处理缺失值
传统的GBDT没有涉及对缺失值进行处理,XGBoost为什么对缺失值不敏感?
一些涉及到对样本距离的度量的模型,如SVM和KNN,如果缺失值处理不当,最终会导致模型预测效果很差。
而树模型对缺失值的敏感度低,大部分时候可以在数据缺失时时使用。
- 寻找分裂节点时,不会对缺失的样本值进行遍历;另外,为了保持完备性,会把含有缺失值的样本分配到左右两个叶子节点,然后选择分裂后增益最大的那个方向,作为预测时特征值缺失样本的默认分支方向。
- 如果训练集中没有缺失值,但是测试集中有,那么默认将缺失值划分到右叶子节点方向。
05 XGBoost的参数
- 通用参数:宏观函数控制。
- Booster参数:控制每一步的booster(tree/regression)。
- 学习目标参数:控制训练目标的表现。
通用参数
- booster[默认gbtree] 选择每次迭代的模型,有两种选择:
-** gbtree**
- gbliner:线性模型,使用带l1,l2 正则化的线性回归模型作为基学习器。
- dart: 表示采用dart booster (将深度神经网络社区的辍学技术(剔除一些琐碎的树)添加到boosting tree中,解决过度拟合问题) - **silent ** [默认0]
- nthread [默认值为最大可能的线程数,-1] 这个参数用来进行多线程控制,应当输入系统的核数。如果你希望使用CPU全部的核,那就不要输入这个参数,算法会自动检测它。
- num_pbuffer 指定了prediction buffer(该buffer 用于保存上一轮boostring step 的预测结果) 的大小。通常设定为训练样本的数量。该参数由xgboost 自动设定,无需用户指定。
- num_feature 样本的特征数量。通常设定为特征的最大维数。该参数由xgboost 自动设定,无需用户指定。
Tree Booster 参数
- eta[默认3] 和GBM中的 learning rate 参数类似。通过减少每一步的权重,可以提高模型的鲁棒性。范围为 [0,1],典型值为0.01-0.2。
- min_child_weight[默认1] 子节点的权重阈值。它刻画的是:对于一个叶子节点,当对它采取划分之后,它的所有子节点的权重之和的阈值。所谓的权重,对于线性模型(booster=gblinear),权重就是:叶子节点包含的样本数量,对于树模型(booster=gbtree,dart),权重就是:叶子节点包含样本的所有二阶偏导数之和。这个参数用于避免过拟合。当它的值较大时,可以避免模型学习到局部的特殊样本。但是如果这个值过高,会导致欠拟合。这个参数需要使用CV来调整。该值越大,则算法越保守(尽可能的少划分)。
- 如果它的所有子节点的权重之和大于该阈值,则该叶子节点值得继续划分
- 如果它的所有子节点的权重之和小于该阈值,则该叶子节点不值得继续划分 - max_delta_step[默认为0] 每棵树的权重估计时的最大delta step。取值范围为[0,∞],0 表示没有限制。
这个参数限制了每棵树权重改变的最大步长,如果这个参数的值为0,则意味着没有约束。如果他被赋予了某一个正值,则是这个算法更加保守。通常,这个参数我们不需要设置,但是当个类别的样本极不平衡的时候,这个参数对逻辑回归优化器是很有帮助的。 - max_depth[默认6] GBM中的参数相同,这个值为树的最大深度。这个值也是用来避免过拟合的。max_depth越大,模型会学到更具体更局部的样本。需要使用CV函数来进行调优。典型值:3-10
- max_leaf_nodes 树上最大的节点或叶子的数量。可以替代max_depth的作用。因为如果生成的是二叉树,一个深度为n的树最多生成n^2个叶子。如果定义了这个参数,GBM会忽略max_depth参数。
- gamma[默认0] 也称作最小划分损失min_split_loss。 它刻画的是:对于一个叶子节点,当对它采取划分之后,损失函数的降低值的阈值。该值越大,则算法越保守(尽可能的少划分)。默认值为 0
- 如果大于该阈值,则该叶子节点值得继续划分
- 如果小于该阈值,则该叶子节点不值得继续划分 - lambda[默认1] 权重的L2正则化项。(和Ridge regression类似)。这个参数是用来控制XGBoost的正则化部分的。该值越大则模型越简单。
- alpha[默认0] 权重的L1正则化项。(和Lasso regression类似)。 可以应用在很高维度的情况下,使得算法的速度更快。该值越大则模型越简单。
- scale_pos_weight[默认1] 用于调整正负样本的权重,常用于类别不平衡的分类问题。一个典型的参数值为:负样本数量/正样本数量。
- tree_method[默认为’auto’] 指定了构建树的算法,可以为下列的值(分布式,以及外存版本的算法只支持 ‘approx’,’hist’,’gpu_hist’ 等近似算法):
‘auto’: 使用启发式算法来选择一个更快的tree_method:
对于小的和中等的训练集,使用exact greedy 算法分裂节点;对于非常大的训练集,使用近似算法分裂节点;旧版本在单机上总是使用exact greedy 分裂节点
‘exact’: 使用exact greedy 算法分裂节点
‘approx’: 使用近似算法分裂节点
‘hist’: 使用histogram 优化的近似算法分裂节点(比如使用了bin cacheing 优化)
‘gpu_exact’: 基于GPU 的exact greedy 算法分裂节点
‘gpu_hist’: 基于GPU 的histogram 算法分裂节点
Dart Booster 参数
XGBoost基本上都是组合大量小学习率的回归树。在这种情况,越晚添加的树比越早添加的树更重要。
DART booster 原理:为了缓解过拟合,采用dropout 技术,随机丢弃一些树。
由于引入了随机性,因此dart 和gbtree 有以下的不同:
因为随机dropout不使用用于保存预测结果的buffer所以训练会更慢
因为随机早停可能不够稳定
学习目标参数 https://www.cnblogs.com/TimVerion/p/11436001.html
这个参数用来控制理想的优化目标和每一步结果的度量方法。
objective [缺省值=reg:linear]
- reg:linear– 线性回归
- reg:logistic – 逻辑回归
- binary:logistic – 二分类逻辑回归,输出为概率
- binary:logitraw – 二分类逻辑回归,输出的结果为wTx
- count:poisson – 计数问题的poisson回归,输出结果为poisson分布。在poisson回归中,max_delta_step的缺省值为0.7 (used to safeguard optimization)
- multi:softmax – 设置 XGBoost 使用softmax目标函数做多分类,需要设置参数num_class(类别个数)
- multi:softprob – 如同softmax,但是输出结果为ndata*nclass的向量,其中的值是每个数据分为每个类的概率。
eval_metric [缺省值=通过目标函数选择]
- r- mse: 均方根误差
- mae: 平均绝对值误差
- logloss: negative log-likelihood
- error: 二分类错误率。其值通过错误分类数目与全部分类数目比值得到。对于预测,预测值大于0.5被认为是正类,其它归为负类。 error@t: 不同的划分阈值可以通过 ‘t’进行设置
- merror: 多分类错误率,计算公式为(wrong cases)/(all cases)
- mlogloss: 多分类log损失
- auc: AUC(Area Under Curve)的曲线下的面积
- ndcg: Normalized Discounted Cumulative Gain
- map: 平均正确率

