


数组
数组与链表的区别
随机访问是数组与链表最本质的区别,而“数组适合查找,链表适合插入和删除”这种表述并不准确。数组查找的时间复杂度并不为O(1),即使排好序的数组,使用二分查找,时间复杂度也是O(logn)。数组支持随机访问,根据下标随机访问的时间复杂度为 O(1)。
数组特性
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
线性表
每个线性表上的数据最多只有前和后两个方向;
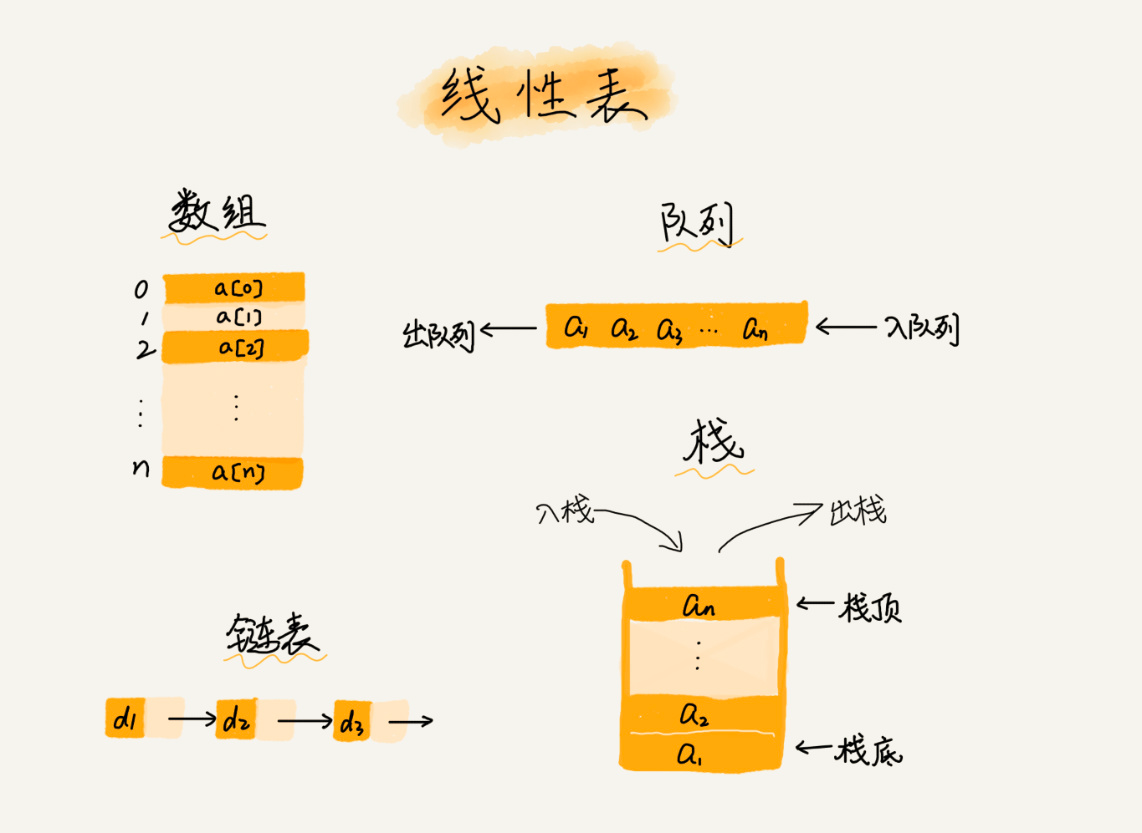
非线性表数据之间关系就会复杂很多,比如二叉树,堆,图。
连续的内存空间和相同类型的数据
随机访问正是因为这两个特性才能实现。这也导致删除和插入的时候,需要做大量数据搬移的工作。
如何根据下标随机访问数组元素
假设有有一个数组 int[] a = new int[10],内存块首地址为base_address = 1000.

根据寻址公式来计算该元素存储的内存地址:(data_type_size 表示数组中每个元素的大小)
a[i]_address = base_address + i * data_type_size
数组的插入
数组插入的平均时间复杂度为O(n),因为最坏情况需要移动所有的元素。
想要降低复杂度可以将要插入位置的旧元素挪到数组尾部,然后将新元素插入即可。

数组的删除
删除元素后一样会伴随搬移数据,为了保证内存的连续性。平均时间复杂度也为O(n).
特殊场景下可以把删除操作集中到一起执行,也就是每次删除操作并不是真正搬移数据,只是记录数据已经被删除。当数组没有更多空间存储时,再触发一次真正的删除操作,这样就大大减少了删除操作导致的数据搬移。JVM的标记清除算法就是如此。
容器与数组
容器(例如ArrayList)的最大优势就是可以将很多数组操作的细节封装起来,另外就是支持动态扩容,ArrayList不设默认长度时候,则先默认设置10的内存空间,之后如果长度大于10则扩容1.5倍,同时复制数组。
- 容器无法储存基本类型,如果要使用基本类型可以使用数组
- 底层开发可以为了性能考虑可以使用数组。
数组下标为什么从0开始
之前的寻址公式为:
a[k]_address = base_address + k * type_size
如果数组下标是从1开始,那么寻址公式就会变为:
a[k]_address = base_address + (k - 1) * type_size
每次随机访问元素都多了一次减法运算,对于CPU来说,就多了一次减法指令。
作者:六月的余晖
出处:http://www.cnblogs.com/zhaozihan/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。

