
深度学习中图像上采样的方法
深度学习中的图像上采样方法
所谓上采样,就是将图像从一个较低的尺寸 \([C, H, W]\) 恢复到一个较大的尺寸 \([C, sH, sW]\),其中 \(s\) 是上采样倍数,从小图到大图这一变换过程也叫图像的超分辨率重建。图像超分辨率重建是一个研究很深入的领域,对于大部分的应用场景,我们不需要对此做过多研究,通常使用一些简单且常用的方法对图像进行上采样进行预处理。在这里我们就介绍几种简单的上采样方式。
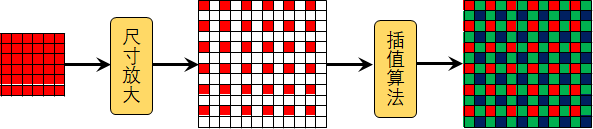
如下图所示,一般的上采样方式首先将原始图像的尺寸进行放大,空出来很多需要补充的区域,然后通过一定的插值算法来计算待补充的区域,从而实现图像的放大。常见的插值算法主要分为传统的插值算法和基于深度学习的插值算法两类。
一、传统的插值算法
传统的插值算法主要包括最邻近插值 (Nearest interpolation),双线性插值 (Bilinear interpolation) 和双三次插值 (Bicubic interpolation) 三种方法。
1.1 最邻近插值 (Nearest interpolation)
最邻近插值很好立即,就是选取与待填充位置最近的像素值作为该位置的值。在 PyTorch 中通过 nn.UpsamplingNearest2d() 来实现。具体的代码如下:
input = torch.arange(1,5, dtype=torch.float32).view(1,1,2,2) # 定义 input 输入
m = nn.UpsamplingNearest2d(scale_factor=2) # 创建最邻近插值实例
m(input) # 计算插值结果
tensor([[[[1., 1., 2., 2.],
[1., 1., 2., 2.],
[3., 3., 4., 4.],
[3., 3., 4., 4.]]]])
1.2 双线性插值 (Bilinear interpolation)
简单地将最邻近的值作为插值会带来明显的棋盘效应,因此一个改进的插值算法是双线性插值。计算方法如下:
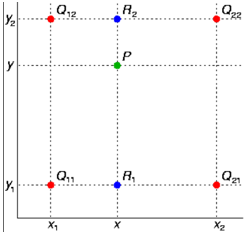
先分别对上下两行做一次插值计算,得到 \(R_{1}\), \(R_{2}\) ;
再对 \(R_{1}\), \(R_{2}\) 做一次插值,得到 \(P\)。
具体代码如下:
n = nn.UpsamplingBilinear2d(scale_factor=2) # 创建双线性插值实例
n(input) # 计算双线性插值结果
tensor([[[[1.0000, 1.3333, 1.6667, 2.0000],
[1.6667, 2.0000, 2.3333, 2.6667],
[2.3333, 2.6667, 3.0000, 3.3333],
[3.0000, 3.3333, 3.6667, 4.0000]]]])
1.3 双三次插值 (Bicubic interpolation)
双三次插值(Bicubic interpolation)也有一些文章会翻译为三线性插值,本文统一同双三次插值。其根据离待插值最近的4*4=16个已知值来计算待插值,每个已知值的权重由距离待插值距离决定,距离越近权重越大。具体的计算公式在这里就不再赘述了,有兴趣的可以查阅相关资料。代码如下:
k = nn.Upsample(scale_factor=2, mode='bicubic', align_corners=True) # 创建双三次插值实例
k(input) # 计算双三次插值输出
tensor([[[[1.0000, 1.3148, 1.6852, 2.0000],
[1.6296, 1.9444, 2.3148, 2.6296],
[2.3704, 2.6852, 3.0556, 3.3704],
[3.0000, 3.3148, 3.6852, 4.0000]]]])
二、基于深度学习的插值方法
2.1 反卷积 (Transposed Convolution)
反卷积是一种特殊的卷积,总是可以使用一种卷积来模拟反卷积的过程。然而该方式将引入许多‘0’的行和‘0’的列,导致实现上非常的低效。并且,反卷积只能恢复尺寸,并不能恢复数值,因此经常用在神经网络中作为提供恢复的尺寸,具体的数值往往通过训练得到。代码如下:
# 将一个 [1, 1, 3, 3] 的图像通过反卷积将尺寸上采样为 [1, 1, 5, 5]
input = torch.arange(1,10,dtype=torch.float32).view(1,1,3,3)
Transposed = nn.ConvTranspose2d(1,1,3,stride=2, padding = 1)
Transposed(input)
Out[122]:
tensor([[[[-0.1766, -0.3358, -0.2509, -0.2865, -0.3252],
[ 0.5506, -1.5407, 0.6985, -1.7486, 0.8463],
[-0.3995, -0.1880, -0.4738, -0.1388, -0.5481],
[ 0.9942, -2.1643, 1.1420, -2.3722, 1.2899],
[-0.6225, -0.0403, -0.6968, 0.0089, -0.7711]]]])
2.2 亚像素上采样 (Pixel Shuffle)
普通的上采样采用的临近像素填充算法,主要考虑空间因素,没有考虑channel因素,上采样的特征图人为修改痕迹明显,图像分割与GAN生成图像中效果不好。为了解决这个问题,ESPCN中提到了亚像素上采样方式。具体原理如下:
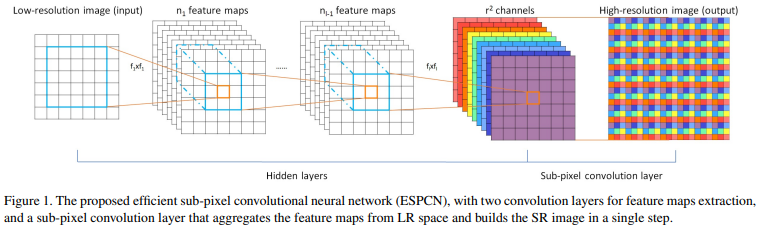
根据上图,可以得出将维度为 \([B, C, H, W]\) 的 feature map 通过亚像素上采样的方式恢复到维度 \([B, C, sH, sW]\) 的过程分为两步:
- 首先通过卷积进行特征提取,将 \([B, C, H, W]=>[B, s^{2}C, H, W]\)
- 然后通过Pixel Shuffle 的操作,将 \([B, s^{2}C, H, W] => [B, C, sH, sW]\)
Pixel Shuffle的主要功能就是将这 \(s^{2}\) 个通道的特征图组合为新的 \([B, C, sH, sW]\) 的上采样结果。具体来说,就是将原来一个低分辨的像素划分为 \(s^{2}\) 个更小的格子,利用 \(s^{2}\) 个特征图对应位置的值按照一定的规则来填充这些小格子。按照同样的规则将每个低分辨像素划分出的小格子填满就完成了重组过程。在这一过程中模型可以调整 \(s^{2}\) 个shuffle通道权重不断优化生成的结果。
在ESPCN中,具体的实现过程如下:
class Net(nn.Module):
def __init__(self, upscale_factor):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 64, (5, 5), (1, 1), (2, 2))
self.conv2 = nn.Conv2d(64, 32, (3, 3), (1, 1), (1, 1))
self.conv3 = nn.Conv2d(32, 1 * (upscale_factor ** 2), (3, 3), (1, 1), (1, 1)) # 最终将输入转换成 [32, 9, H, W]
self.pixel_shuffle = nn.PixelShuffle(upscale_factor) # 通过 Pixel Shuffle 来将 [32, 9, H, W] 重组为 [32, 1, 3H, 3W]
def forward(self, x):
x = torch.tanh(self.conv1(x))
x = torch.tanh(self.conv2(x))
x = torch.sigmoid(self.pixel_shuffle(self.conv3(x)))
return x
if __name__ == "__main__":
model = Net(upscale_factor=3)
input = torch.arange(1, 10, dtype = torch.float32).view(1,1,3,3)
output = model(input)
print(output.size())
# 输出结果为:
torch.Size([1, 1, 9, 9])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号