
从GAN到WGAN的来龙去脉
一、原始GAN的理论分析
1.1 数学描述
其实GAN的原理很好理解,网络结构主要包含生成器 (generator) 和鉴别器 (discriminator) ,数据主要包括目标样本 \(x_r \sim P_{r}\), 随机输入样本 \(z \sim P_{z}\) 。生成器的目的就是根据 \(z\) 生成 \(G(z) \sim P_{r}\) ,而鉴别器则尽量区分出来 \(G(z)\) 与 \(x_{r}\) 的不同。生成器和鉴别器采用生成对抗的方式不断优化,最终能通过生成器得到期望输出(比如风格转换,人脸生成等)。联想到电影《无双》的情节,生成器就是造假币的机器,而鉴别器可以类似为鉴别假币的手段。在初始情况下,假币制造机只能生成不是很逼真的假币,此时鉴别器很轻松就能鉴别出来,于是便优化流程和材料,鉴别器鉴别错误之后再改进判别手段......如此往复,最终我们可以得到足以以假乱真的假币。
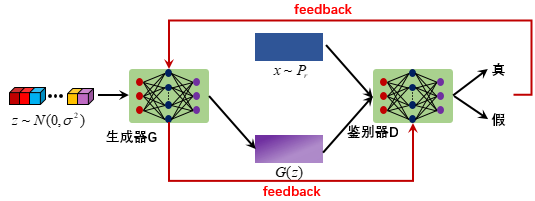
1.2 求出全局最优解
当固定 \(G\) 的参数时,优化 \(D\) 的参数:
因此,最大值为:
解得:
于是,将 \(D^{*}(x)\) 带入到公式 (4) 中,得到:
即:
由于\(P_{r}+P{g} \in [0,2]\),因此公式 (10) 可以写为:
最终:
因此,当 \(P_{r} = \dfrac{P_{r}+P_{g}}{2} = P_{g}\) 时,存在唯一极小值 \(P_{r} = P_{g}\),此时 \(D^{*}(x) = \dfrac{1}{2}\)。即公式 (4) 存在全局最优解,在全局最优解的情况下,生成器生成的概率分布与目标样本概率分布一样,此时鉴别器无法准确判断生成样本与目标样本的差异,判断正确和错误的概率各为0.5,类似于瞎猜。
1.3 原始GAN到底出了什么问题?
GAN的训练是依靠生成器和鉴别器的相互对抗来完成的,那么直观地思考一下:如果鉴别器过于差劲,给不到生成器任何有用的信息,那么生成器的更新就会没有方向;如果鉴别器太好,那么类似于造假币的机器极其差,而鉴别器直接就是验钞机,那么直观上也无法给生成器提供足够的信息去更新。因此,原始的GAN理论上可行,而实际上却受到鉴别器和生成器状态的影响,不一定能找到最优解,且训练不稳定。
从数学角度上来描述:我们在 1.2节 求全局最优解的过程中,先求出了鉴别器 \(D\) 的最优解,然后得到了公式 (11) ,在这种情况下相当于我用已经训练好的鉴别器来指导生成器的学习,将概率分布从 \(P_{z}\) 拉向 \(P_{r}\)。乍一看没什么问题,但是如果两个分布 \(P_{r}\),\(P_{z}\) 完全没有重叠的部分,或者它们重叠的部分可忽略,会发生什么情况呢?答案是无论换句话说,无论 \(P_{r}\) 跟 \(P_{g}\)是远在天边,还是近在眼前,只要它们俩没有一点重叠或者重叠部分可忽略,公式 (11) 散度就固定是常数 \(log2\),而这对于梯度下降方法意味着——梯度为0!此时对于最优判别器来说,生成器肯定是得不到一丁点梯度信息的;即使对于接近最优的判别器来说,生成器也有很大机会面临梯度消失的问题。与我们直观上的感觉一致。
那么问题就变成了\(P_{r}\),\(P_{z}\) 没有重叠的部分的概率大吗?答案是非常大。首先,\(P_{r}\) 是一个复杂分布,而 \(P_{z}\) 则是一个简单分布,所以在空间上二者不重叠的概率很大。更重要的一个原因是,输入 \(z \sim P_{r}\) 一般是 100 维,而生成的目标往往是一张图片,比如 \(64 \times 64\) 就是 \(4096\) 维,低维与高维相重合本来就很少,因此更加证明了原始GAN不容易训练。总结下来:
原始GAN存在梯度不稳定的问题,即判别器训练得太好,生成器梯度消失,生成器loss降不下去;判别器训练得不好,生成器梯度不准,四处乱跑。只有判别器训练得不好不坏才行,但是这个火候又很难把握,甚至在同一轮训练的前后不同阶段这个火候都可能不一样,所以GAN才那么难训练。 此外,GAN还存在模式崩塌(collapse mode)的问题,即生成样本多样性不足。
二、WGAN的前世今生
为了解决原始GAN梯度不稳定的问题,一个过渡的解决方案是强行对生成样本和真实样本加噪声,使得原本两个分布弥散到整个高维空间,增加重叠部分。当二者出现重叠部分时,再把噪声拿掉,这样也能够继续收敛。这只是一个折中的方案,并没有从本质上解决问题。
2.1 Wasserstein 距离
Wasserstein 距离又叫 Earth-Mover ( EM ) 距离,定义如下:
其中:\(\prod (P_{r}, P_{g})\) 表示从概率 \(P_{g}\) 到 \(P_{r}\) 的所有可能分布,而 \(W(P_{r},P_{g})\) 代表所有可能的分布中, \(||x-y||\) 的最小期望值距离。举个例子:如下图所示,假如将左侧的方块运送到右侧的位置,那么方案有很多种,其中最小的那一种移动所花的消耗即为Wasserstein距离。
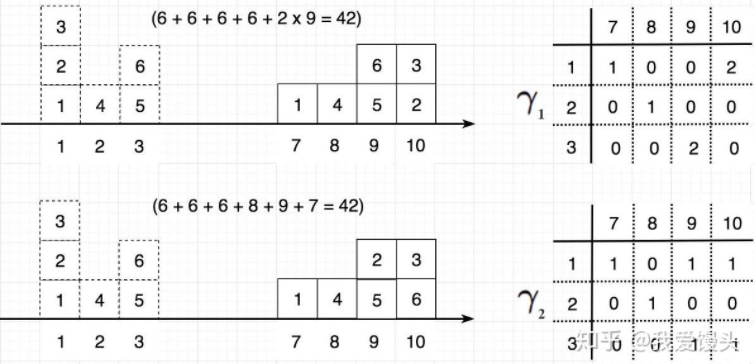
2.2 从EM距离到WGAN
由于在Wasserstein中,\(\mathop{inf}\limits_{\gamma \sim \prod (P_{r}, P_{g})}\) 没办法直接求解,因此WGAN的作者通过已有的定理将其转换成如下形式:
式子的证明过程对我来说确实难以理解,因此这里就不作解释了,有兴趣的可以参考WGAN的原论文。最后,WGAN的loss function变成了下面的形式:
于是,可以把函数 \(f\) 用一个参数为 \(w\) 的神经网络来表示。最后,为了满足 \(||f_{w}||_{L}<K\) 的限制,将神经网络的所有参数 \(w\) 都拉伸到 \([-c,c]\) 中,所以一定满足Lipschitz连续条件。
因此,我们可以构造一个含参数 \(w\)、最后一层不是非线性激活层的判别器网络 \(f_{w}\),在限制! \(w\) 不超过某个范围的条件下,使得:
尽可能取到最大,此时的 \(L\) 就可以近似为真实分布 \(P_{r}\) 与生成分布 \(P_{g}\) 之间的Wasserstein距离。注意:原始GAN的判别器做的时二分类任务,所以最后一层采用 \(sigmoid\) 函数,而WGAN中的判别器做的是拟合 Wasserstein 距离,属于回归任务,因此把最后一层的 \(sigmoid\) 去掉。
因此判别器的loss function为:
生成器的loss function为:
所以,不管理论再复杂, WGAN在原始的GAN上只做了三点改进:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
最后,作者通过经验发现,不要使用Adam优化算法,推荐RMSProp或者SGD。
2.3 模型崩塌(collapse mode)问题的解决方法
上述解决了GAN在训练过程中梯度不稳定的问题,那么模型崩塌(collapse mode)问题的解决方法如下:
2.3.1 在loss function 层面
通常先更新几轮生成器,之后再更新一轮鉴别器。因为GAN的训练是 \(min max\) 的策略,即先更新鉴别器,然后再更新生成器。往往在迭代的过程中,生成器和鉴别器交替优化,容易将问题变成 \(maxmin\) 的问题,这样一来就变成了:生成器先生成一个输出,然后鉴别器对这个输出进行判断,那么生成器最后学习到的往往是最保险的,导致模型崩塌(collapse mode),生成样本多样性不足。
2.3.2 在网络结构方面
1、采用多个生成器和一个鉴别器,类似于旷视“先发散再收敛”的学习策略,通过正则化约束生成器之间的比重,生成多样性的样本。
2、将真实样本通过一个编码器 (Encoder) 后再使用生成器进行重构,如下图所示:
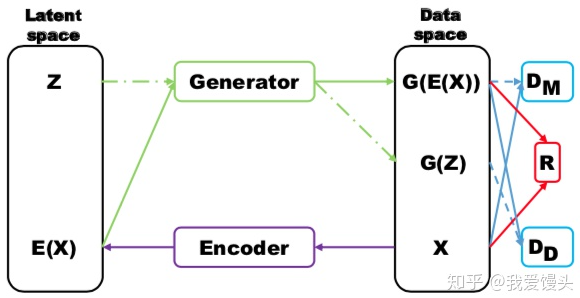
那么 \(D_{M}\) 和 \(R\) 用来指导生成对应的样本,而 \(D_{D}\) 则对 \(G(z)\) 和 \(G(E(x))\) 进行判别,显然二者都是生成的样本,差别越大那么表明生成样本的多样性越高。
3、Mini-batch discrimination在判别器的中间层建立一个mini-batch layer用于计算基于 \(L_{1}\) 距离的样本统计量,通过建立该统计量去判别一个batch内某个样本与其他样本有多接近。这个信息可以被判别器利用到,从而甄别出哪些缺乏多样性的样本。对生成器而言,则要试图生成具有多样性的样本。
2.4 WGAN 部分代码分析
self.G_sample = self.generator(self.z)
self.D_real, _ = self.discriminator(self.X)
self.D_fake, _ = self.discriminator(self.G_sample, reuse = True)
# loss
self.D_loss = - tf.reduce_mean(self.D_real) + tf.reduce_mean(self.D_fake)
self.G_loss = - tf.reduce_mean(self.D_fake)
self.D_solver = tf.train.RMSPropOptimizer(learning_rate=1e-4).minimize(self.D_loss, var_list=self.discriminator.vars)
self.G_solver = tf.train.RMSPropOptimizer(learning_rate=1e-4).minimize(self.G_loss, var_list=self.generator.vars)
# clip
self.clip_D = [var.assign(tf.clip_by_value(var, -0.01, 0.01)) for var in self.discriminator.vars]
然后按照正常的GAN训练即可。
