单表操作
表介绍
表相当于文件,表中的一条记录就相当于文件的一行内容,不同的是,表中的一条记录有对应的标题,称为表的字段

id,name,qq,age称为字段,其余的,一行内容称为一条记录
对数据库的表的操作就是数据库内的文件(table)的操作
创建表
#语法: create table 表名( 字段名1 类型[(宽度) 约束条件], 字段名2 类型[(宽度) 约束条件], 字段名3 类型[(宽度) 约束条件] ); #注意: 1. 在同一张表中,字段名是不能相同 2. 宽度和约束条件可选 3. 字段名和类型是必须的
这个是没有加上默认的编码的但是最好加上默认的编码
创建表:
|
1
2
3
4
|
create table 表名( 列名 类型 是否可以为空, 列名 类型 是否可以为空)ENGINE=InnoDB DEFAULT CHARSET=utf8 |
在最后加上指定的编码utf8 或者gbk并且指定的引擎
创建表时加上注释:COMMENT
1、创建带注释的表 CREATE TABLE test.game( nId INT PRIMARY KEY AUTO_INCREMENT COMMENT '设置主键自增', szName VARCHAR(128) COMMENT '游戏名字', szPath VARCHAR(256) COMMENT '下载路径' ) COMMENT='表注释';
eg:
create table TestTwo( id int primary key AUTO_INCREMENT COMMENT '这是一个主键列', name char(20) comment "这是姓名列" ) charset = utf8 comment "这是一个测试表";


是否可空,null表示空,非字符串 not null - 不可空 null - 可空
默认值,创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值 create table tb1( nid int not null defalut 2, num int not null ) 这个是对nid列设置一个默认的值2 如果没有添加值就默认为2
自增,如果为某列设置自增列,插入数据时无需设置此列,默认将自增(表中只能有一个自增列) create table tb1( nid int not null auto_increment primary key, num int null ) 或 create table tb1( nid int not null auto_increment, num int null, index(nid) ) 注意:1、对于自增列,必须是索引(含主键)。 2、对于自增可以设置步长和起始值 show session variables like 'auto_inc%'; set session auto_increment_increment=2; set session auto_increment_offset=10; shwo global variables like 'auto_inc%'; set global auto_increment_increment=2; set global auto_increment_offset=10;
主键,一种特殊的唯一索引,不允许有空值,如果主键使用单个列,则它的值必须唯一,如果是多列,则其组合必须唯一。 create table tb1( nid int not null auto_increment primary key, num int null ) 或 create table tb1( nid int not null, num int not null, primary key(nid,num) )
外键,一个特殊的索引,只能是指定内容 creat table color( nid int not null primary key, name char(16) not null ) create table fruit( nid int not null primary key, smt char(32) null , color_id int not null, constraint fk_cc foreign key (color_id) references color(nid) )
删除表
DROP TABLE +要删除表名 ; drop table test; # 删除test表
表的操作:
修改表
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
添加列:alter table 表名 add 列名 类型删除列:alter table 表名 drop column 列名修改列: alter table 表名 modify column 列名 类型; -- 类型 alter table 表名 change 原列名 新列名 类型; -- 列名,类型 添加主键: alter table 表名 add primary key(列名);删除主键: alter table 表名 drop primary key; alter table 表名 modify 列名 int, drop primary key; 添加外键:alter table 从表 add constraint 外键名称(形如:FK_从表_主表) foreign key 从表(外键字段) references 主表(主键字段);删除外键:alter table 表名 drop foreign key 外键名称 修改默认值:ALTER TABLE testalter_tbl ALTER i SET DEFAULT 1000;删除默认值:ALTER TABLE testalter_tbl ALTER i DROP DEFAULT; |
修改表: ALTER TABLE
语法: 1. 修改表名 ALTER TABLE 表名 RENAME 新表名; 2. 增加字段 ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…], ADD 字段名 数据类型 [完整性约束条件…]; ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…] FIRST; ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…] AFTER 字段名; 3. 删除字段 ALTER TABLE 表名 DROP 字段名; 4. 修改字段 ALTER TABLE 表名 MODIFY 字段名 数据类型 [完整性约束条件…]; ALTER TABLE 表名 CHANGE 旧字段名 新字段名 旧数据类型 [完整性约束条件…]; ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型 [完整性约束条件…];
示例:
alter table t5 rename nihao; 这个是将你的t5列名字修改为nihao alter table t5 add new_id int ; 这是在你的 t5列中增加一个int类型的new_id列; alter table t5 drop new_id; 删除你的 t5列中的new_id 列
alter table t5 modify new_id char(30); 这是把你的t5列中的new_id 列的数据类型改为char alter table t5 change new_id old char; 把你的t5列中的原有的char类型的new_id 列改为old列 alter table t5 CHANGE old new_id int; 把你的t5列中的old列改为 int类型的new_id 列
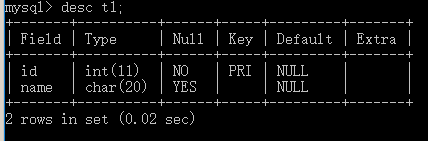
查看表结构: desc+查看的表
MariaDB [db1]> describe t1; #查看表结构,可简写为desc 表名 +-------+-----------------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-----------------------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | | name | varchar(50) | YES | | NULL | | | sex | enum('male','female') | YES | | NULL | | | age | int(3) | YES | | NULL | | +-------+-----------------------+------+-----+---------+-------+ MariaDB [db1]> show create table t1\G; #查看表详细结构,可加\G \G不适用连接工具比如navicat此类工具
desc t1; 查看t1表中的信息
效果:
查看表的详细结构

mysql> show create table a1\G;
*************************** 1. row ***************************
Table: a1
Create Table: CREATE TABLE `a1` (
`id` int(11) DEFAULT NULL,
`name` varchar(50) DEFAULT NULL,
`age` int(3) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
震惊IT界的增删改查:
对表中的内容进行操作 增:INSERT INTO表名(增加内容的列)VALUES(增加的内容); 删:delete 要删除的内容 from 表名 where 条件; 改:update 表名 set 改的内容 where 条件; 查: SELECT 内容 from 列明
我们以后大部分的‘ 搬砖工作者’ 几乎都是和这些增删改查一直打交道的
八 复制表
复制表结构+记录 (key不会复制: 主键、外键和索引) mysql> create table new_service select * from service; 只复制表结构 mysql> select * from service where 1=2; //条件为假,查不到任何记录 Empty set (0.00 sec) mysql> create table new1_service select * from service where 1=2; Query OK, 0 rows affected (0.00 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> create table t4 like employees;
即复制表结构和数据 create table t6 select * from t5 创建t6表并且复制t5表中的所有的结构和信息 只复制表结构 where后面必须是false create table t7 select * from t5 where 1 > 3; 只复制表结构(2) create table t8 like t5; 创建t8表并且把t5表的结构复制到t8中不复制它的值
复制表的信息到另外一个表
Insert into 表名(自己的信息列)+ select +被复制的表的信息列+from+被复制的表名
insert into t2(id,name) select id,name from t1; 把t1中的id和name列复制到t2的id和name列
表内容操作
1、增
增有好几个方式: insert into 表 (列名,列名...) values (值,值,值...) insert into 表 (列名,列名...) values (值,值,值...),(值,值,值...) insert into 表values(值,值,值);这种方法增加的时候需要把每个不为空不自增的值都加上 复制: insert into 表 (列名,列名...) select (列名,列名...) from 表
注意这种查询别的语句来插入自己语句中不需要values
在MySQL管理软件中,可以通过SQL语句中的DML语言来实现数据的操作,包括 1.使用INSERT实现数据的插入 2.UPDATE实现数据的更新 3.使用DELETE实现数据的删除 4.使用SELECT查询数据以及。
1. 插入完整数据(顺序插入) 语法一: INSERT INTO 表名(字段1,字段2,字段3…字段n) VALUES(值1,值2,值3…值n); 语法二: INSERT INTO 表名 VALUES (值1,值2,值3…值n); 2. 指定字段插入数据 语法: INSERT INTO 表名(字段1,字段2,字段3…) VALUES (值1,值2,值3…); 3. 插入多条记录 语法: INSERT INTO 表名 VALUES (值1,值2,值3…值n), (值1,值2,值3…值n), (值1,值2,值3…值n); 4. 插入查询结果 语法: INSERT INTO 表名(字段1,字段2,字段3…字段n) SELECT (字段1,字段2,字段3…字段n) FROM 表2 WHERE …;
插入查询结果:
INSERT INTO t1 ( NAME ) ( SELECT NAME FROM userinfo WHERE id = 1 ); 这是找到你userinfo表中的id等于1的name的值 然后插入t1表中的name中
如果要加入values 的话必须要在结果的外面再加入一个括号() 也就是两个括号()
INSERT INTO t1 ( NAME ) VALUES (( SELECT NAME FROM userinfo WHERE id = 1 ));
这个就是在values的后面加上两个括号
改:
update
语法: UPDATE 表名 SET 字段1=值1, 字段2=值2, WHERE CONDITION; 示例: UPDATE mysql.user SET password=password(‘123’) where user=’root’ and host=’localhost’;
update tb12 set name='laoliu' where id>12 and name='xx' 把id大于12 和姓名是xx的 name改为老刘 update tb12 set name='laoliu',age=19 where id>12 and name='xx' 把id 大于12 和name是xx的name 改为laoliu age 改为19
删:delete
delete 一般都是和where判读条件一起使用的
语法: DELETE FROM 表名 WHERE CONITION; 示例: DELETE FROM mysql.user WHERE password=’’; 练习: 更新MySQL root用户密码为mysql123 删除除从本地登录的root用户以外的所有用户
示例:
删除可以根据很多判读条件来删除
delete from tb12; delete from tb12 where id !=2 删除id不等于2的 delete from tb12 where id =2 删除id等于2的 delete from tb12 where id > 2 删除大于2的 delete from tb12 where id >=2 删除大于等于2的 delete from tb12 where id >=2 or name='zhaoyun' 删除大于等于2 或者name是zhaoyun的
查:
查可谓是重中之重 此乃以后孩儿们的操作重心,细细品味
单表查询的语法:
单表查询的语法 SELECT 字段1,字段2... FROM 表名 WHERE 条件 GROUP BY field HAVING 筛选 ORDER BY field LIMIT 限制条数
查
|
1
2
3
|
select * from 表select * from 表 where id > 1select nid,name,gender as gg from 表 where id > 1 |
关键字的执行优先级(重点)
重点中的重点:关键字的执行优先级 from where group by having select distinct order by limit
单条件查询 SELECT name FROM employee WHERE post='sale'; 这个是对employee表中的name查找 当你的post等于sale的时候
多条件查询
SELECT name,salary FROM employee
WHERE post='teacher' AND salary>10000;
关键字BETWEEN AND
区间查询:between要和and连用
SELECT * FROM T2 WHERE ID BETWEEN 1 AND 6;
查找你的t2表中的id从1到6的name的值
关键字IS NULL(判断某个字段是否为NULL不能用等号,需要用IS)
select * from t2 where id is not null;
查找你的t2表内的所有的id不为空的name的值
关键字IN集合查询
select name from t2 where id in(3,5,7);
这个是查找id是3,5,7的name的值
NOT IN 查找:
select name from t2 where id not in (3,5);
查找你的t2表中的id不是3和5的name的值
关键字LIKE模糊查询
模糊匹配有两个% 和_
%是可以匹配任意字符
_只能匹配一个字符
他们两个都要和like一起使用
%可以放在后面就是以什么什么开头,放在信息前面面含有什么什么
select * from t2 where name like '饭%';
这个就是寻找 t2表中的name 是以饭开头的信息
SELECT NAME FROM T2 WHERE NAME LIKE '%井';
查找你t2表中的 name是的信息中后面含有井的
select * from t2 where name like '%云%';
查找你的name的信息中只要含有云的信息
下划线_ 只能匹配英文 不能匹配汉字 并且只能匹配到一位 不能多匹配
select * from t2 where name like 'z_';
查找你的t2表中的name中以z开头的仅有两个英文字母的信息
避免重复DISTINCT
不能有重复的
select distinct name from t2;
茶查找t2中不重复的name信息
嵌套查找:
select name from t2 where id = (select id from t1 where name like'%刘') ;
这个
判断条件是当你的id等于他表中的naem的后面是刘的id然后求出这个id对应的t2的name
分页操作:limit:
当你的limit后面只有一个数字的时候就代表你要显示多少 如果后面是两个数字第一个是代表你要从第几位开始查找第二代代表你查找的数量
select * from t2 where id limit 3;
这个是指定只查找前3页
select * from t2 where id limit 3,3;
从id等于3开始查找 往后查找3页
排序:order by
排序的desc 是从大到小 asc是从小到大
select * from t2 order by id desc ;
查询id从大到小的t2表中的信息 一般这个是倒序查找
select * from t2 order by id asc;
根据id从小到大查找t2表中的信息 正序查找
select * from t2 order by id desc limit 3;
求这个是取后3条数据
分组操作:group by
什么是分组?为什么要分组?
#1、首先明确一点:分组发生在where之后,即分组是基于where之后得到的记录而进行的
#2、分组指的是:将所有记录按照某个相同字段进行归类,比如针对员工信息表的职位分组,或者按照性别进行分组等
#3、为何要分组呢?
取每个部门的最高工资
取每个部门的员工数
取男人数和女人数
小窍门:‘每’这个字后面的字段,就是我们分组的依据
#4、大前提:
可以按照任意字段分组,但是分组完毕后,比如group by post,只能查看post字段,如果想查看组内信息,需要借助于聚合函数
分组的管理函数:
max()求最大值 min()求最小值 avg()求平均值 sum() 求和 count() 求总个数
**** 如果对于聚合函数结果进行二次筛选时?必须使用having ****
select count(id),name from t2 where id > 1 group by name having count(id) > 1; 这个就是二次筛选需要使用having第一个是求出id大于1 第二次是求出总数大于1的再显示
group by
根据什么什么来分组
select count(id),name from t2 group by name; 这个是根据name来分组运用count来求出id的和
HAVING过滤
HAVING与WHERE不一样的地方在于 #!!!执行优先级从高到低:where > group by > having #1. Where 发生在分组group by之前,因而Where中可以有任意字段,但是绝对不能使用聚合函数。 #2. Having发生在分组group by之后,因而Having中可以使用分组的字段,无法直接取到其他字段,可以使用聚合函数
汇总:
a、条件 select * from 表 where id > 1 and name != 'alex' and num = 12; select * from 表 where id between 5 and 16; select * from 表 where id in (11,22,33) select * from 表 where id not in (11,22,33) select * from 表 where id in (select nid from 表) b、通配符 select * from 表 where name like 'ale%' - ale开头的所有(多个字符串) select * from 表 where name like 'ale_' - ale开头的所有(一个字符) c、限制 select * from 表 limit 5; - 前5行 select * from 表 limit 4,5; - 从第4行开始的5行 select * from 表 limit 5 offset 4 - 从第4行开始的5行 d、排序 select * from 表 order by 列 asc - 根据 “列” 从小到大排列 select * from 表 order by 列 desc - 根据 “列” 从大到小排列 select * from 表 order by 列1 desc,列2 asc - 根据 “列1” 从大到小排列,如果相同则按列2从小到大排序 e、分组 select num from 表 group by num select num,nid from 表 group by num,nid select num,nid from 表 where nid > 10 group by num,nid order nid desc select num,nid,count(*),sum(score),max(score),min(score) from 表 group by num,nid select num from 表 group by num having max(id) > 10 特别的:group by 必须在where之后,order by之前 f、连表 无对应关系则不显示 select A.num, A.name, B.name from A,B Where A.nid = B.nid 无对应关系则不显示 select A.num, A.name, B.name from A inner join B on A.nid = B.nid A表所有显示,如果B中无对应关系,则值为null select A.num, A.name, B.name from A left join B on A.nid = B.nid B表所有显示,如果B中无对应关系,则值为null select A.num, A.name, B.name from A right join B on A.nid = B.nid g、组合 组合,自动处理重合 select nickname from A union select name from B 组合,不处理重合 select nickname from A union all select name from B

