mysql窗口函数
使用MySQL开窗函数之前一定先确定当前数据库版本是否支持,因为只有MySQL8.0以上的版本才支持开窗函数
用navicat如何查看MySQL的版本的方法:
在出现的界面输入命令 select version();
窗口函数(数据分析-SQL高阶(窗口函数) - 哔哩哔哩 (bilibili.com))
窗口函数也称为OLAP(Online Analytical Processing)函数,意思是对数据库数据进行实时分析处理,窗口函数在Oracle和SQL Server 中也被称为分析函数,窗口函数语法如下
<窗口函数> OVER ([PARTITION BY <列清单>] ORDER BY <排序用列清单> [框架])
语法中<>中的内容不可省略,[]中的内容可以省略。即PARTIION BY和框架可以省略,ORDER BY 不可以省略。框架对汇总范围进行限定。
(ROWS | RANGE) BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING) (ROWS | RANGE) BETWEEN CURRENT ROW AND (CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING) (ROWS | RANGE) BETWEEN [num] FOLLOWING AND (UNBOUNDED | [num]) FOLLOWING
窗口函数: 1)可以作为窗口函数的聚合函数。
SUM :求和
MIN :最小值
MAX :最大值
AVG :平均值
COUNT :计数
2)专用窗口函数
RANK :跳跃排序,排序:1,1,3
DENSE_RANK :连续排序,排序:1,1,2
ROW_NUMBER:没有重复值的排序,排序:1,2,3
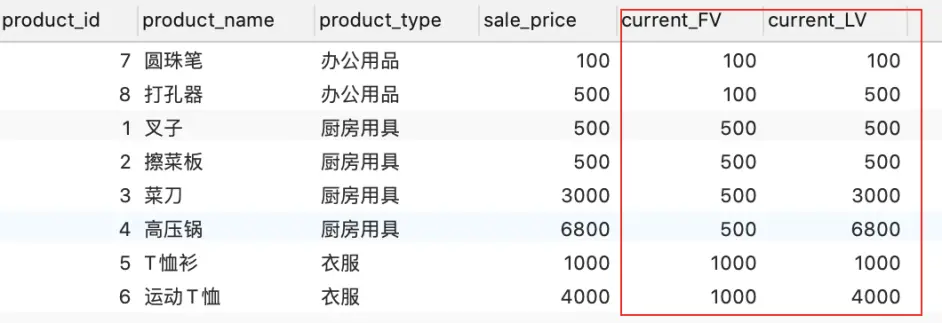
FIRST_VALUE :返回组中数据窗口的第一个值
LAST_VALUE :返回组中数据窗口的最后一个值。
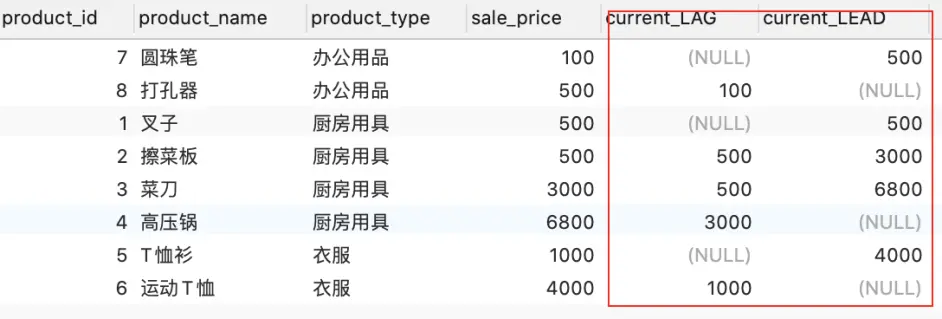
LAG :LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值。
LEAD :LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值。
窗口函数实操
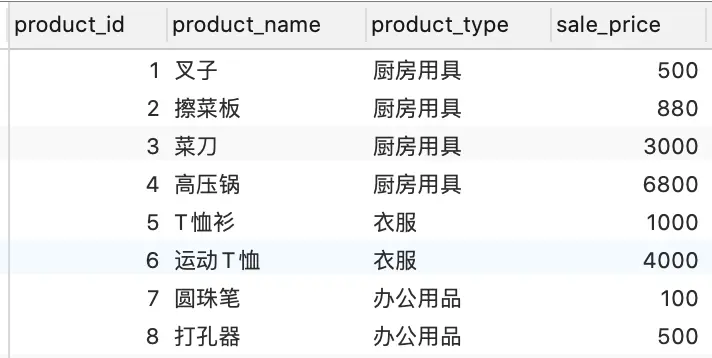
先创建一张产品表
create table product ( product_id int(4) COMMENT 'ID', product_name varchar(10) COMMENT '产品名称', product_type varchar(10) COMMENT '产品类型', sale_price int(4) COMMENT '价格' )ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='产品清单'
插入数据
insert into product(product_id,product_name,product_type,sale_price) values(1,'叉子','厨房用具',500),(2,'擦菜板','厨房用具',880), (3,'菜刀','厨房用具',3000),(4,'高压锅','厨房用具',6800),(5,'T恤衫','衣服',1000),(6,'运动T恤','衣服',4000),(7,'圆珠笔','办公用品',100),(8,'打孔器','办公用品',500);
结果表如图
1)可以作为窗口函数的聚合函数。
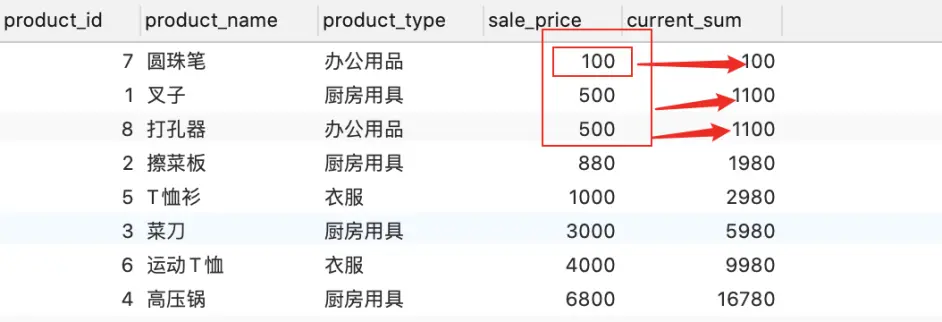
sum求和(累计值)
SELECT product_id, product_name, product_type, sale_price, SUM(sale_price) OVER (PARTITION BY product_type ORDER BY sale_price range BETWEEN UNBOUNDED PRECEDING and current row ) AS current_sum FROM Product;
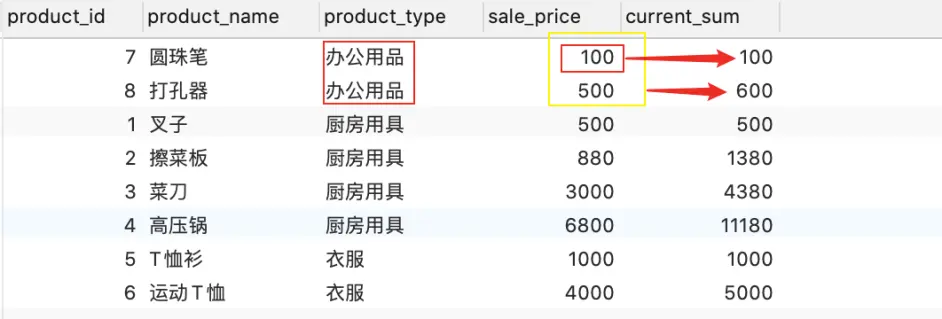
SELECT product_id, product_name, product_type, sale_price, SUM(sale_price) OVER ( ORDER BY sale_price ) AS current_sum FROM Product; # 上边语句和下边语句结果相同 SELECT product_id, product_name, product_type, sale_price, SUM(sale_price) OVER ( ORDER BY sale_price range BETWEEN UNBOUNDED PRECEDING and current row ) AS current_sum FROM Product;
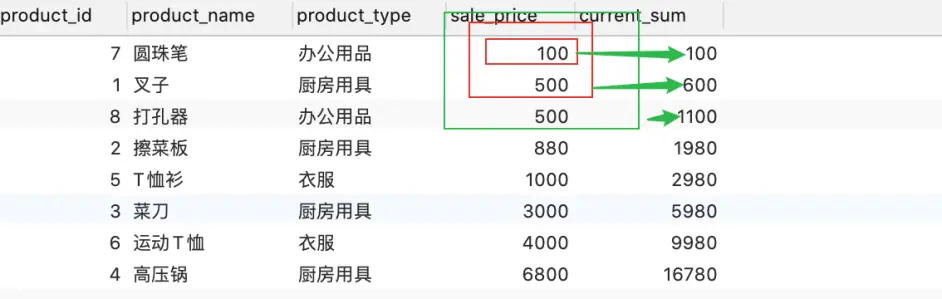
注:默认框架为 range BETWEEN UNBOUNDED PRECEDING and current row,row和range的区别是rows按照行进行计算,如当求第一行的时候,求和为第一行-第一行,当求第二行的时候,求和为第一行-第二行;而range是按照值进行计算,如sale_price, 当sale_price=100,求和范围为100-100,当sale_price=500,求和范围为100-500。
SELECT product_id, product_name, product_type, sale_price, SUM(sale_price) OVER ( ORDER BY sale_price rows BETWEEN UNBOUNDED PRECEDING and current row ) AS current_sum FROM Product;
MIN、MAX、AVG、COUNT
SELECT product_id, product_name, product_type, sale_price, MIN(sale_price) OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_min, MAX(sale_price) OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_max, AVG(sale_price) OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_avg, COUNT(sale_price) OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_count FROM Product;

注:默认框架为range BETWEEN UNBOUNDED PRECEDING and current row*,range是按照值进行计算的,以count来进行讲述,第一组第一行count计算的范围为sale_price值,就是100-100的就一个值,计数1;第一组第二行count计算的范围为100-500,计数2;第二组第一行count计算的范围为500-500,计数2。后续类似。
2)专用窗口函数
RANK、DENSE_RANK、ROW_NUMBER
SELECT product_id, product_name, product_type, sale_price, rank() OVER ( PARTITION BY product_type ORDER BY sale_price rows BETWEEN 2 PRECEDING and current row ) AS current_rk, dense_rank() OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_drk, row_number() OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_rn FROM Product;
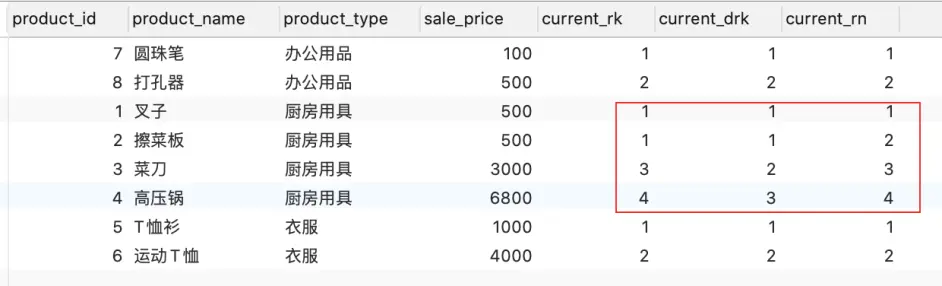
注:rank函数排序是可以跳跃的,dense_rank函数排序是顺序的,row_number函数排序是按照行数。
FIRST_VALUE、LAST_VALUE
SELECT product_id, product_name, product_type, sale_price, FIRST_VALUE(sale_price) OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_FV, LAST_VALUE(sale_price) OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_LV FROM Product;
LAG 、LEAD。
SELECT product_id, product_name, product_type, sale_price, LAG(sale_price,1) OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_LAG, LEAD(sale_price,1) OVER ( PARTITION BY product_type ORDER BY sale_price ) AS current_LEAD FROM Product;
总结
窗口函数兼具GROUP BY 子句的分组功能和ORDER BY子句的排序功能,但是PARTITION BY子句跟GROUP BY 不具备汇总功能,也就说PARTITION BY子句不会减少行数。
通过PARTITION BY 分组后的记录集合称为窗口。此处的窗口并非“窗户”的意思,而是代表范围。这也是“窗口函数”名称的由来。
一、hive窗口函数语法
在前言中我们已经说了avg()、sum()、max()、min()是分析函数,而over()才是窗口函数,下面我们来看看over()窗口函数的语法结构、及常与over()一起使用的分析函数
1、over()窗口函数的语法结构
2、常与over()一起使用的分析函数
3、窗口函数总结
1、over()窗口函数的语法结构
分析函数 over(partition by 列名 order by 列名 rows between 开始位置 and 结束位置)over()函数中包括三个函数:包括分区partition by 列名、排序order by 列名、指定窗口范围rows between 开始位置 and 结束位置。我们在使用over()窗口函数时,over()函数中的这三个函数可组合使用也可以不使用。
over()函数中如果不使用这三个函数,窗口大小是针对查询产生的所有数据,如果指定了分区,窗口大小是针对每个分区的数据。
1.1、over()函数中的三个函数讲解
order by
order by是排序的意思,是该窗口中的
A、partition by
partition by可理解为group by 分组。over(partition by 列名)搭配分析函数时,分析函数按照每一组每一组的数据进行计算的。
B、rows between 开始位置 and 结束位置
是指定窗口范围,比如第一行到当前行。而这个范围是随着数据变化的。over(rows between 开始位置 and 结束位置)搭配分析函数时,分析函数按照这个范围进行计算的。
窗口范围说明:
我们常使用的窗口范围是ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(表示从起点到当前行),常用该窗口来计算累加。
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:起点(一般结合PRECEDING,FOLLOWING使用)
UNBOUNDED PRECEDING 表示该窗口最前面的行(起点)
UNBOUNDED FOLLOWING:表示该窗口最后面的行(终点)
比如说:
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(表示从起点到当前行)
ROWS BETWEEN 2 PRECEDING AND 1 FOLLOWING(表示往前2行到往后1行)
ROWS BETWEEN 2 PRECEDING AND 1 CURRENT ROW(表示往前2行到当前行)
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING(表示当前行到终点)2、常与over()一起使用的分析函数:
2.1、聚合类
avg()、sum()、max()、min()
2.1、排名类
row_number()按照值排序时产生一个自增编号,不会重复(如:1、2、3、4、5、6)
rank() 按照值排序时产生一个自增编号,值相等时会重复,会产生空位(如:1、2、3、3、3、6)
dense_rank() 按照值排序时产生一个自增编号,值相等时会重复,不会产生空位(如:1、2、3、3、3、4)
2.1、其他类
lag(列名,往前的行数,[行数为null时的默认值,不指定为null]),可以计算用户上次购买时间,或者用户下次购买时间。
lead(列名,往后的行数,[行数为null时的默认值,不指定为null])
ntile(n) 把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,ntile返回此行所属的组的编号
3、窗口函数总结:
其实窗口函数逻辑比较绕,我们可以把窗口理解为对表中的数据进行分组,排序等计算。
含义:窗口函数也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据进行实时分析处理。
作用:
- 解决排名问题,e.g.每个班级按成绩排名
- 解决TOPN问题,e.g.每个班级前两名的学生
语法:
select 窗口函数 over (partition by 用于分组的列名, order by 用于排序的列名
分类:
- 专用窗口函数:rank(),dense_rank(),row_number()
- 汇总函数:max(),min(),count(),sum(),avg()
注意:窗口函数是对where后者group by子句处理后的结果进行操作,因此按照SQL语句的运行顺序,窗口函数一般放在select子句中。
窗口函数的用法
- 专用窗口函数
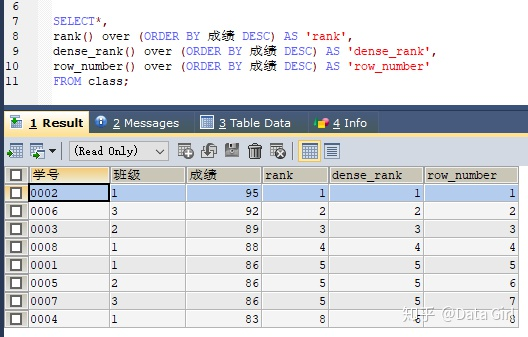
rank()函数

说明
- rank()是排序函数,括号中不需要有参数;
- 通过partition by将班级分类,相当于之前用过的group by子句功能,但是group by子句分类汇总会改变原数据的行数,而用窗口函数自救保持原行数;
- 通过order by将成绩降序排列,与之前学的order by子句用法一样,后边可以升序asc或者降序desc;
总结:
- 窗口函数这里的“窗口”表示范围,可以理解为将原数据划分范围,即分组,然后用函数实现某些目的
- 窗口函数有分组和排序的功能
- 不减少原表的行数
2. 其他专用窗口函数:dense_rank/row_number
- 用法与rank()函数相同

- 当成绩相同时,会存在并列的情况,主要区别是三个函数如何处理并列情况:
在rank()函数,如果有并列情况,会占用下一个名次的位置,比如,成绩为100的学生有三个并列第一,那么99分的学生是第二名,通过rank()函数,名次是:1,1,1,4;
在dense()函数中,如果有并列的情况,不会占用下一个名词,同用上个例子,名次是:1,1,1,2;
在row_number()函数中,会忽略并列的情况,同用上述例子,名次是:1,2,3,4;