
python的内置模块(二)
python内置模块之random模块

import random
# 1、随机产生一个0-1之间的小数 print(random.random()) # 2、随机产生一个1-6之间的整数 print(random.randint(1, 6)) # 3、随机产生一个1-6之间的小数 print(random.uniform(1,6)) # 4、随机抽取一个 print(random.choice(['特等奖', '一等奖', '二等奖', '谢谢惠顾', '惊喜大奖'])) # 5、随机抽取指定样本量 print(random.sample(['安徽省', '江苏省', '山东省', '海南省', '广东省'], 3)) # 6、随机打乱容器类型中的诸多元素(比如洗牌) l = [2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 'A'] random.shuffle(l) print(l)
练习题
# 随机验证码可以是由 数字 小写字母 大小写字母 任意组合 # 编写能够产生五位数的随机验证码 '''ps:五位 每位都可以是三种情况之一''' def get_code(n): # 提前定义一个存储验证码的变量 code = '' # 由于需要产生五位 每一位的操作都是一样的 所以肯定需要使用循环 for i in range(n): # 随机产生一个数字 random_int = str(random.randint(0, 9)) # 随机产生一个大写字母 random_upper = chr(random.randint(65, 90)) # 随机产生一个小写字母 random_lower = chr(random.randint(97, 122)) # 随机选取一个 temp = random.choice([random_int, random_upper, random_lower]) # 拼接到字符串中 code += temp return code code1 = get_code(5) code2 = get_code(10) code3 = get_code(8) print(code1,code2,code3)
python内置模块之os模块
os模块主要是和操作系统打交道
import os # 1.创建单级目录(文件夹) os.mkdir('文件名') os.mkdir(r'文件名\子文件名') #报错 只能创建一个文件夹 # 2.创建多级目录(文件夹) os.makedirs(r'文件名\子文件名\子文件名') # 3.删除空目录(文件夹) os.rmdir(r'文件名') os.removedirs(r'文件名') # 4.获取当前文件所在的路径(可以嵌套 则为上一层路径) BASE_DIR = os.path.dirname(__file__) # 5.路径拼接, 能够自动识别不同操作系统分隔符问题 movie_dir = os.path.join(BASE_DIR, '文件夹名称') # 6.列举出指定路径下的文件名称(任意类型文件) data_movie_list = os.listdir(文件路径) # 7.删除一个文件 os.remove('a.txt') # 8.修改文件名称 os.rename('老文件名','新文件名') # 9.获取当前工作路径
print(os.getcwd()) # 10.切换路径
os.chdir('D:/')with open(r'a.txt','wb') as f: pass # 11.判断当前路径是否存在
print(os.path.exists('a.txt')) # Falseprint(os.path.exists('b.txt')) # Trueprint(os.path.exists('01 random模块.py')) # True # 12.判断当前路径是否是文件
print(os.path.isfile('01 random模块.py')) # Trueprint(os.path.isfile('b.txt')) # False # 13.判断当前路径是否是文件夹
print(os.path.isdir('01 random模块.py')) # Falseprint(os.path.isdir('b.txt')) # True # 14.获取文件大小(字节数)
print(os.path.getsize(r'a.txt'))
练习题
1 while True: 2 for i, j in enumerate(data_movie_list): 3 print(i + 1, j) 4 choice = input('请选择你想要看的文件编号>>>:').strip() 5 if choice.isdigit(): 6 choice = int(choice) 7 if choice in range(len(data_movie_list) + 1): 8 # 获取编号对应的文件名称 9 file_name = data_movie_list[choice - 1] 10 # 拼接文件的完整路径(******) 11 file_path = os.path.join(movie_dir, file_name) # 专门用于路径拼接 并且能够自动识别当前操作系统的路径分隔符 12 # 利用文件操作读写文件 13 with open(file_path, 'r', encoding='utf8') as f: 14 print(f.read())
python内置模块之sys模块
主要与python解释器打交道
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1) sys.version 获取Python解释程序的版本信息 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称
用途
import sys try: username = sys.argv[1] password = sys.argv[2] if username == 'jason' and password == '123': print('正常执行文件内容') else: print('用户名或密码错误') except Exception: print('请输入用户名和密码') print('目前只能让你体验一下(游客模式)')
python内置模块之序列化模块
1、什么叫序列化
将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化
2、序列化的目的
1、以某种存储形式使自定义对象持久化
2、将对象从一个地方传递到另一个地方
3、使程序更具维护性
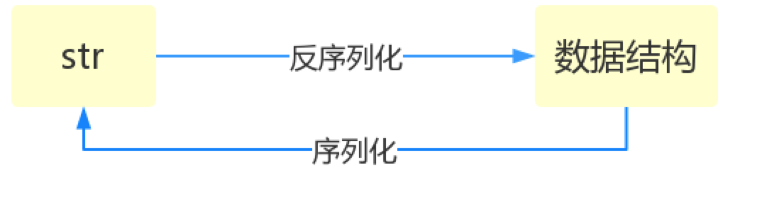
3、json模式提供了四个功能:dumps、dump、loads、load
具体使用如下(以将字典写入文件为例)
#1、字典写入文件普通版 # 将字典d写入文件 with open(r'a.txt','w',encoding='utf8') as f: f.write(str(d)) # 将字典d取出来 with open(r'a.txt','r',encoding='utf8') as f: data = f.read() print(dict(data)) # 2、字典写入文件序列化版 # 将字典d写入文件 with open(r'a.txt','w',encoding='utf8') as f: res = json.dumps(d) # 序列化成json格式字符串 f.write(res) # 将字典d取出来 with open(r'a.txt','r',encoding='utf8') as f: data = f.read() res1 = json.loads(data) print(res1,type(res1)) # 3、字典写入文件序列化简易版 d1 = {'username': 'tony', 'pwd': 123,'hobby':[11,22,33]} with open(r'a.txt', 'w', encoding='utf8') as f: json.dump(d1, f) with open(r'a.txt','r',encoding='utf8') as f: res = json.load(f) print(res,type(res))
4、中英文结合的字符串打印出来的结果不变
d1 = {'username': 'tony好帅哦 我好喜欢', 'pwd': 123,'hobby':[11,22,33]}
print(json.dumps(d1,ensure_ascii=False))
# {"username": "tony好帅哦 我好喜欢", "pwd": 123, "hobby": [11, 22, 33]}
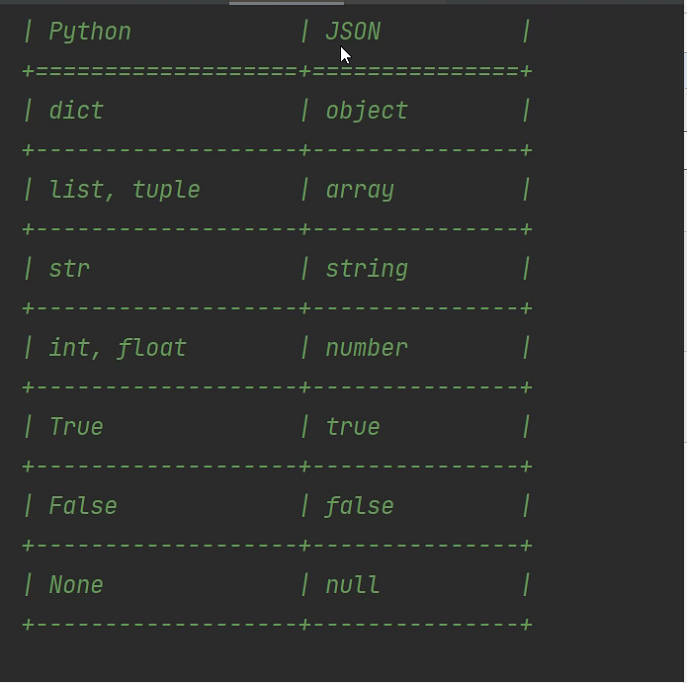
5、并不是所有的数据类型都支持序列化,可以通过json.JSONEncoder 查看支持的数据类型
python内置模块之subprocess模块
1、做什么的?
1、可以基于网络连接上一台计算机(socket模块)
2、让连接上的计算机执行我们需要执行的命令
3、将命令的结果返回
res = subprocess.Popen('tasklist', shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE ) print('stdout',res.stdout.read().decode('gbk')) # 获取正确命令执行之后的结果 print('stderr',res.stderr.read().decode('gbk')) # 获取错误命令执行之后的结果
注:windows电脑内部编码默认为GBK



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构