
字符编码与文件处理
字符编码
只跟文本文件和字符串相关,与视频文件、图片文件、音频文件等无关
1、什么是字符编码
由于计算机内部只识别二进制,但是用户在使用计算机的时候确可以看到各式各样的语言字符。
字符编码:内部记录了人类字符与数字对应关系的数据
2、字符编码的发展史
2.1、阶段一:一家独大
现在计算机起源于美国,所以最先考虑的仅仅是让计算机识别英文字符,,于是诞生了ASCII表
ASCII表里面记录了英文字符于数字的对应关系;一个英文字符对应一个字节,1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有的英文字符
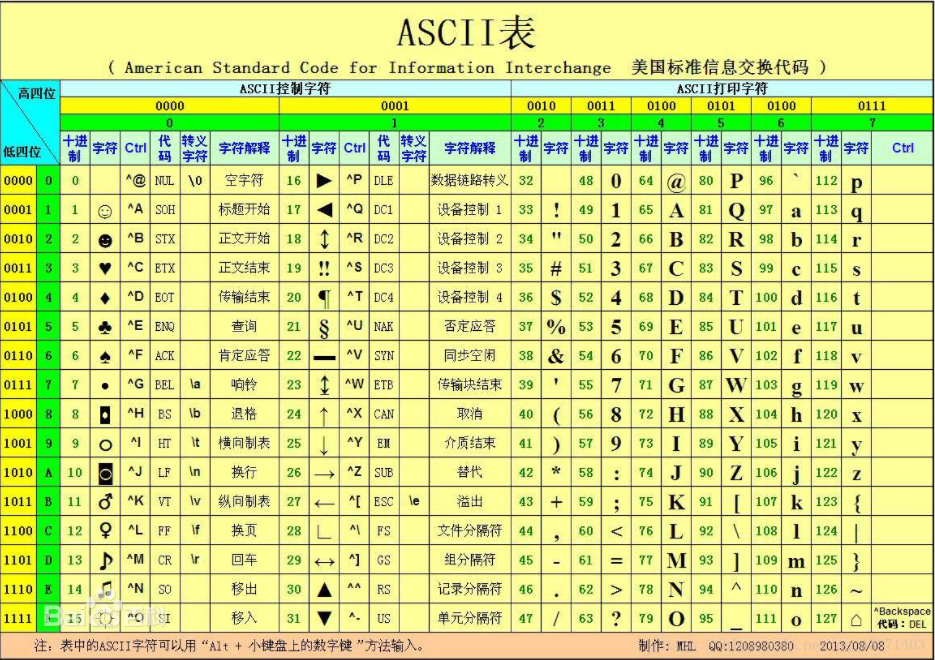
2.2、阶段二:群雄割据
为了让计算机能够识别中文和英文,中国人制定了GBK
# GBK表的特点: 1、只有中文字符、英文字符与数字的一一对应关系 2、一个英文字符对应1Bytes 一个中文字符对应2Bytes 补充说明: 1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字符 2Bytes=16bit,16bit最多包含65536个数字,可以对应65536个字符,足够表示所有中文字符
每个国家为了让计算机能够识别自己国家的字符外加英文字符,各个国家都制定了自己的字符编码表
# Shift_JIS表的特点: 1、只有日文字符、英文字符与数字的一一对应关系 # Euc-kr表的特点: 1、只有韩文字符、英文字符与数字的一一对应关系
2.3、天下一统
为了能够实现不同国家之间的文本数据能够彼此无障碍交流需要对编码统一。
1994年发布了unicode(万国码)。统一使用两个及以上字符记录字符与数字的对应关系
由于unicode固定使用两个字节来存储一个字符,如果多国字符中包含大量的英文字符时,使用unicode格式存放会额外占用一倍空间(英文字符其实只需要用一个字节存放即可),然而空间占用并不是最致命的问题,最致命地是当我们由内存写入硬盘时会额外耗费一倍的时间,所以将内存中的unicode二进制写入硬盘或者基于网络传输时必须将其转换成一种精简的格式,这种格式即UTF-8(全称Unicode Transformation Format,即unicode的转换格式)
内存中使用unicode,硬盘使用UTF-8
# 多国字符—√—》内存(unicode格式的二进制)——√—》硬盘(utf-8格式的二进制)
3、字符编码实操
3.1、如何解决文件乱码的情况
文件当初用什么编码编写的,打开的时候就用什么编码打开
3.2、python解释器版本不同带来的编码差异
在python2.x内部使用的编码默认是ASCII,,使用时需要在文件头加coding:utf8;并且在定义字符串前面加一个小u。
# coding:utf8 name = u'tony'
在python3.x中内部使用utf8
3.3、编码与解码
编码:将人类能够读懂的字符按照指定的编码转换成数字
解码:将数字按照指定的编码转换成人类能够读懂的字符

s = '今天又是充满希望的一天' # 编码 res = s.encode('utf8') print(res, type(res)) # 解码 res1 = res.decode('utf8') print(res1, type(res1)) # 结果 b'\xe4\xbb\x8a\xe5\xa4\xa9\xe5\x8f\x88\xe6\x98\xaf\xe5\x85\x85\xe6\xbb\xa1\xe # 今天又是充满希望的一天 <class 'str'>
文件操作
1、什么是文件
文件其实是操作系统暴漏给用户操作硬盘的快捷方式(接口)
2、代码如何操作文件
关键字:open()
三步走:
1、利用关键字open打开文件
2、利用其他方式操作文件
3、关闭文件
3、路径
相对路径:参考对象是根目录
绝对路径:参考对象是当前目录
路径中出现了字母与斜杠的组合产生了特殊含义时,只需要在路径字符前加一个r就可以了
# open('a.txt') # open(r'D:\py\a.txt')
4、open使用
open(文件路径,读写模式,字符编码);其中文件路径与读写模式是必须的,字符编码是可选的,有些模式不需要编码)
res = open('a.txt', 'r', encoding='utf8') print(res.read()) res.close() # 关闭文件释放资源 # 结果 hello world
with上下文件管理(能够自动帮你close())
with open (r'a.txt', 'r', encoding='utf8') as f1: print(f1.read()) # 运行结果 hello world ''' 代码操作文件,推荐使用with语法'''
文件读写模式
r(只读模式,只能看不能改)
# 路径不存在,直接报错 with open (r'b.txt', 'r', encoding='utf8') as f1: pass # pass和...是补全语法,没有实际含义 # 路径存在,读取文件内容 with open(r'a.txt', 'r', encoding='utf8') as f1: # print(f1.read()) # 读取文件内容 # 运行结果 hello world f1.write('123') # 报错 写文件内容
w(只写模式,只能看不能写)
# 路径不存在,直接创建新的文件 with open(r'b.txt', 'w', encoding='utf8') as f1: pass # 路径存在,会先清空文件内容,再执行写入操作 with open(r'a.txt', 'w', encoding='utf8') as f1: pass # (a.txt里面的内容清空) # f1.read() # 报错 读取文件内容 f1.write('hello world\n') # 写文件内容 f1.write('hello world\n') # 结果 hello world # hello world
a(追加模式)
# 路径不存在,创建新文件 with open('b.txt', 'a', encoding='utf8') as f: pass # 路径存在,在原有文件内容之后写入新内容 with open('b.txt', 'a', encoding='utf8') as f1: f1.write('今天也是充满希望的一天')
小总结:r、w、a模式都只能操作文本文件
文件操作的方法
1、读系列(r)
with open ('a.txt', 'r', encoding='utf8') as f: print(f.read()) # 一次性读取文件内所有的内容 print(f.readline()) # 每次只读文件一行内容 print(f.readlines()) # 读取文件的所有内容,组织成列表,列表中的每个元素是文件每行的内容 print(f.readable()) # 判断该文件是否具备读的能力。True和False
2、写系列(w)
with open ('a.txt', 'w', encoding='utf8') as f: f.write(('今天也是美好的一天')) print(f.write()) # 写入内容,需注意写入的内容必须是字符串类型 print(f.writelines(['tony', 'tom', 'jack'])) # 可以将列表中多个字符串元素全部写入 print(f.writable()) # 判断该文件是否具备写的能力。True和False f.flush() # 直接将内存文件数据保存到硬盘中,相当于ctrl+s
文件优化
with open(r'a.txt', 'r', encoding='utf8') as f: # print(f.read()) # 一次性读取文件内所有的内容 # print(f.read()) # 一次性读取文件内所有的内容 # print(f.read()) # 一次性读取文件内所有的内容 """ 1.一次性读完之后 光标停留在了文件末尾 无法再次读取内容 2.该方法在读取大文件的时候 可能会造成内存溢出的情况 解决上述问题的策略就是逐行读取文件内容 """ # for line in f: # 文件变量名f支持for循环 相当于一行行读取文件内容 # line '''以后涉及到多行文件内容的情况一般都是采用for循环读取'''
文件操作模式
1、t(文本模式)
默认的模式 r w a == rt wt at 该模式所有操作都是以字符串基本单位(文本) 该模式必须要指定encoding参数 该模式只能操作文本文件
2、b(二进制模式)
该模式可以操作任意类型的文件
该模式所有操作都是以bytes类型(二进制)基本单位
该模式不需要指定encoding参数
rb wb ab
二进制模式读写操作
# b模式下 # with open(r'a.txt', 'rb') as f: # print(f.read(1)) # b'\xe4' # print(f.read()) # 二进制字符 b'\xe4\xbb\x8a\xe5\xa4\xa9\xe4\xb9\(一部分)\ # print(f.read(1).decode('utf8')) # 报错 # print(f.read(3).decode('utf8')) # 今 # t模式下 # with open(r'a.txt', 'r', encoding='utf8') as f: # print(f.read()) # 今天也是希望的一天 # print(f.read(2)) # 今天
总结:read()中 括号内可以放数字;在 t 模式下表示字符个数;在b模式下表示字节个数。英文字符统一使用一个bytes来表示;中文字符统一使用三个bytes来表示。
文件内光标的移动
with open(r'a.txt', 'r', encoding='utf8') as f: print(f.read(4)) # 今天也是 f.seek(6, 0) print(f.read()) # 也是希望的一天 with open(r'a.txt', 'rb') as f: print(f.read().decode('utf8')) # 今天也是希望的一天 f.seek(3, 1) print(f.read().decode('utf8')) # 天也是希望的一天 f.seek(3, 2) print(f.read().decode('utf8')) # 没有显示
控制文件内光标的移动:f.seek(offset,whence)
offset表示位移量:特点为始终是以字节为最小单位;正数是从左往右移动;负数时从右往左移动。
whence表示模式(0,1,2)
0:以文件开头为参考系(支持t,b两种模式)
1:只支持b模式,以当前位置为参考系
2:只支持b模式,以文件末尾为参考系
文件的内容修改
# 方式1 覆盖 # with open(r'c.txt','r',encoding='utf8') as f: # data = f.read() # # print(type(data)) # with open(r'c.txt','w',encoding='utf8') as f1: # new_data = data.replace('tony','jason') # f1.write(new_data) # 方式2 新建 import os with open('c.txt', mode='rt', encoding='utf-8') as read_f, \ open('c.txt.swap', mode='wt', encoding='utf-8') as write_f: for line in read_f: write_f.write(line.replace('SB', 'kevin')) os.remove('c.txt') # 删除原文件 os.rename('c.txt.swap', 'c.txt') # 重命名文件



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构