【SQL Server】分区函数 partition by
group by是分组函数,partition by是分区函数,sum()等是聚合函数
函数写法
over(partition by Course order by Score)
说明:先对Course列中相同的数据进行分区,在Course中相同的情况下对Score进行排序
rank()与row_number()与dense_rank()对比
例:查询每名课程的第一名的成绩
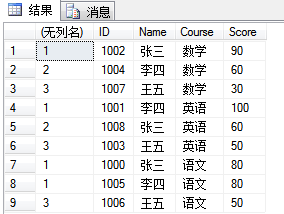
1. rank():如果两个或多个行与一个排名关联,则每个关联行将得到相同的排名。例如,有两位同学具有相同的Score值,则他们将并列排名。由于已有两行排名在前,所以具有下一个最大Score的同学将排名第三。因此,RANK 函数并不总返回连续整数。
select rank() over(partition by Course order by Score desc), * from dbo.UserGrade
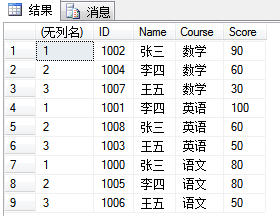
2. row_number():返回结果集分区内行的序列号,每个分区的第一行从 1 开始。ORDER BY 子句可确定在特定分区中为行分配唯一 ROW_NUMBER 的顺序。
select row_number() over(partition by Course order by Score desc), * from dbo.UserGrade
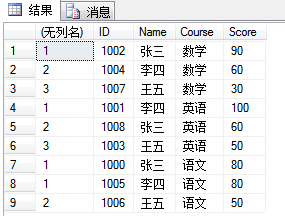
3. dense_rank():如果有两个或多个行受同一个分区中排名的约束,则每个约束行将接收相同的排名。例如,有两位同学具有相同的Score值,则他们将并列排名。接下来 Score最高的同学排名第二。该排名等于该行之前的所有行数加一。因此,DENSE_RANK 函数返回的数字没有间断,并且始终具有连续的排名。整个查询所用的排序顺序确定了各行在结果中的显示顺序。这说明排名第一的行可以不是分区中的第一行。
select dense_rank() over(partition by Course order by Score desc), * from dbo.UserGrade
创建测试数据



create table UserGrade ( ID int, Name varchar(50), Course varchar(50), Score int ) go insert into dbo.UserGrade (ID, Name, Course, Score) values (1000, '张三', '语文', 80),(1001, '李四', '英语', 100),(1002, '张三', '数学', 90),(1003, '王五', '英语', 50),(1004, '李四', '数学', 60),(1005, '李四', '语文', 80),(1006, '王五', '语文', 50),(1007, '王五', '数学', 30),(1008, '张三', '英语', 60)
原文链接:https://blog.csdn.net/weixin_44547599/article/details/88764558



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!