运营活动服务端研发总结
用户增长是互联网技术里比较重要的topic,比如大家熟知的支付宝红包、拼多多砍一刀、头条的百万英雄赢百万等。
活动是常见的增长手段,运营活动在产品的拉新、留存、传播及品牌认知方向都占据非常重要的作用
对于服务端技术而言,挑战也非常大。时间短、节奏紧、流量或者涉及金额大,比如春节运营活动,一旦出问题对公司的口碑造成毁灭性打击。
一提到运营活动,大家第一反应是高并发、和库存安全,这些都是很大挑战,但不是全部。
三年前我整理了部分主题,分享给大家,主题主要包含:
1.如何科学的进行流量预估
2.作弊与反作弊
3.常见活动模式与代码编写
4.指标建设(监控与业务指标)
5.压力测试
如何科学的进行流量预估及资源计算
我想不仅仅是活动、平时产品中也存在产品功能上线的流量预估和资源配置问题。
流量预估直接影响了技术整体的实现方案和资源的配给方式。每秒几十和每秒几w的用户访整体实现方案会发生很大的变化,所以只有科学的进行流量计算才能更好的把控你的服务。
流量预估主要包含两个层面的预估:
- 产品侧的页面UV预估(进入活动页面的用户)
- 技术侧的服务及带给依赖存储和服务的流量预估与拆解
产品侧流量预估
产品侧的流量预估主要依据是入口排期及转化率。
拿到入口的排期及转化率信息,大致可以获得一个与时间相关的流量曲线预估图。这是后续技术侧的技术方案、流量及资源预估的重要依据,也是PM对项目进行复盘时的重要数据。
step1: 拿到所有可能流量来源的排期表
按照我的经验,活动入口大致有几类:
- app内部常驻入口:例如首页开屏、活动专区及各种运营位置
- app主动触达:push、短信、微信公众号群发消息等等
- 外部流量:电视口播、电台口播、线下广告等等
所以重大入口排期表是你进行流量评估的第一步,如果产品没有给你这样的表格,技术是没法开始方案制定的。
| 流量来源 | 1号 | 2号 | 3号 | 4号 |
|---|---|---|---|---|
| 开屏弹窗 | 全天 | 全天 | 全天 | 全天 |
| 短信push | 10点 | |||
| app push | 1点 | 1点 | ||
| 检索词命中 | 所有时间 | |||
| 北京卫视的定点口播 | 晚7点 | 晚7点 | 晚7点 | |
| 用户分享传播 | 不定 | 不定 | 不定 | 不定 |
| 黑产作弊 | 不定 | 不定 | 不定 | 不定 |
step2: 分析各入口流量的转化模型,进行各个入口的拆解流量计算
上一步拿到了入口的排期表,真正到达页面的流量是由入口影响人数、转化模型、转化率决定的。
入口影响人数和历史转化率数据很好拿到,在我们拿到排期之后,这两份数据也需要从PM拿拿到。
从上面的时间表,可以大概看出入口主要氛围两个类型:
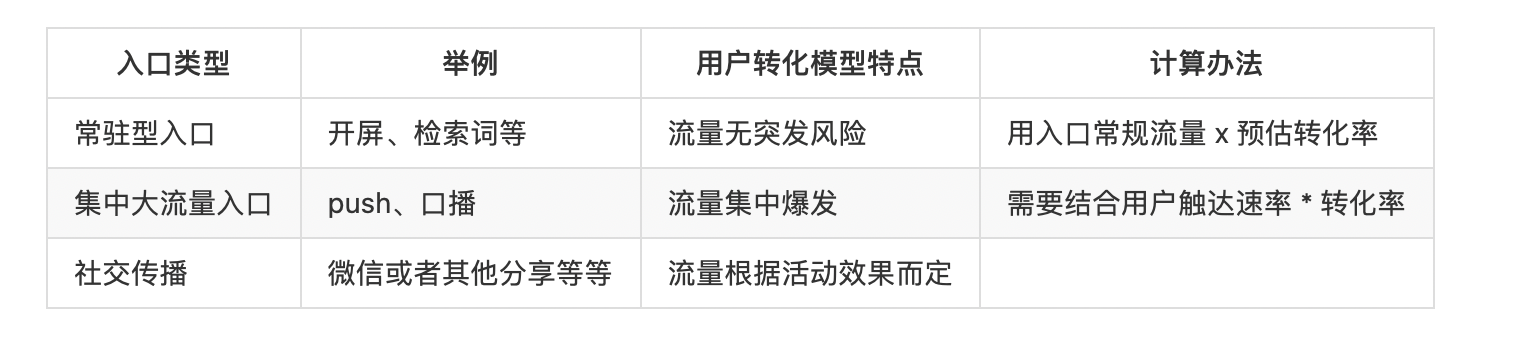
集中入口类
这里我以push这个场景为举例来讲一下集中大流量入口的情形(数据为我捏造、仅做展示使用,具体值请实地考察):
假设你本次需要推送的用户是app全体量用户:3亿用户(1亿ios、2亿android)
推送平台推送的最大速率是:10w/s
android机型限于平台混乱,到达率为5%
ios 机型,到达率为50%
不同类型消息的点击率可能是不同的,比如天气提醒、利益相关等,假设历史同类型消息点击率为2%
下图是push的推送速率曲线图
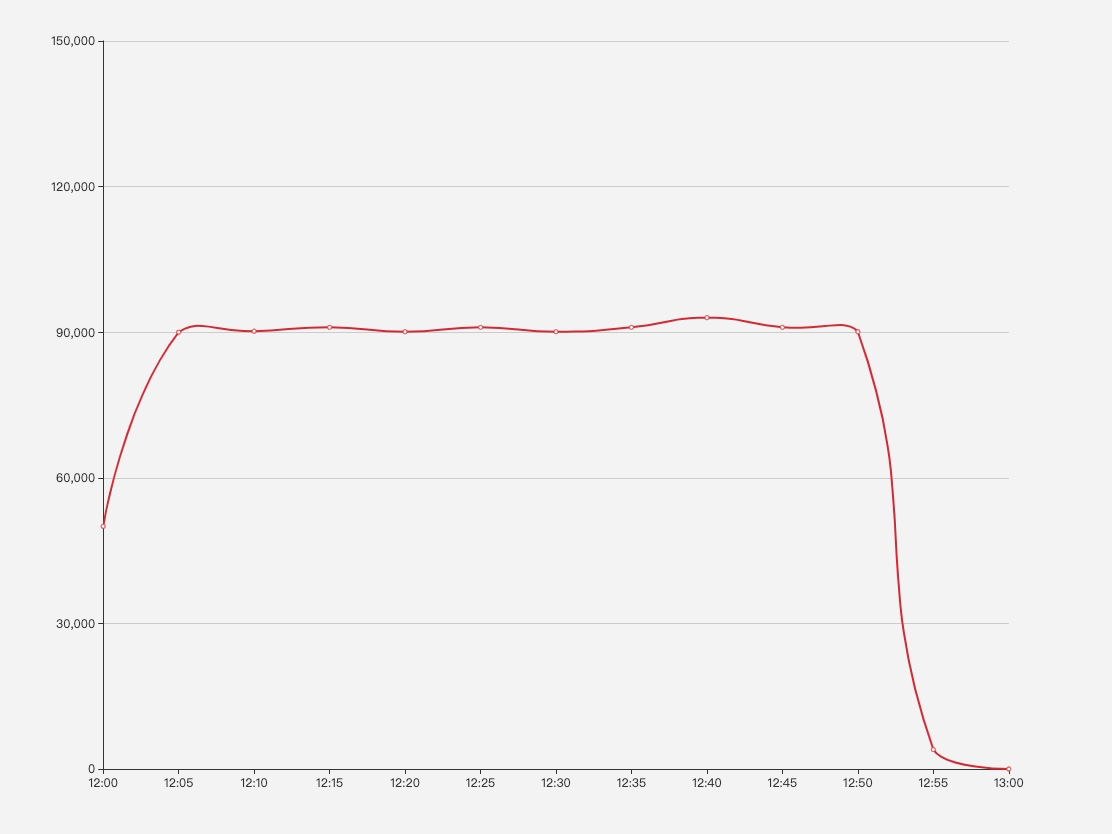
可以大致认为点击的速率与push的速率成正相关的关系
qps_click = qps_push * arrive_rate * common_click_rate
各自分别推算一下ios用户和android用户,按照上面的数据:
qps_click_ios = 10w/s * 50% * 2% = 1k/s
qps_click_android = 10w/s * 5% * 2% = 100/s
如果混合推送,ios:android按照1:2计算:
qps_click_avg = (1k * 1 + 0.1k * 2) / 3 ~ 400/s
常驻型入口类
常驻型入口一般组从日常的流量分布,这个计算方法相对简单。
常驻型入口的qps = 就是打开app的用户速率 x 你的运营被分配的比例 x 常规点击率 qps_click = qps_open_app * show_percent * common_click_rate
社交类型及作弊流量来源
社交型流量来源是最不好估计的一类流量,活动的分享激励不具备相应的吸引力的话,可能带来的流量每天只有几百或者更少。
而如果活动分享激励足够好、内容能够引起共鸣等可以在朋友圈等完成疯传。
作弊流量一样是不可控因素,具体用户采用何种作弊手段、什么时间、会不会来都是不可控因素,这是一个X因素。
step3: 汇总各入口数据,得到一份与时间相关的流量表或者曲线图
所以到现在来看,我们拿到了入口排期、入口流量,也知道了转化率模型及计算方法。
当然我列到可能不是所有情况,更多场景需要你自己计算。
所以你现在基本可以得到一个时间-流量曲线或者表格了,在哪个时间点预计进入页面会有多少。
例如下图,预估在10点、13点会有两个小峰值。
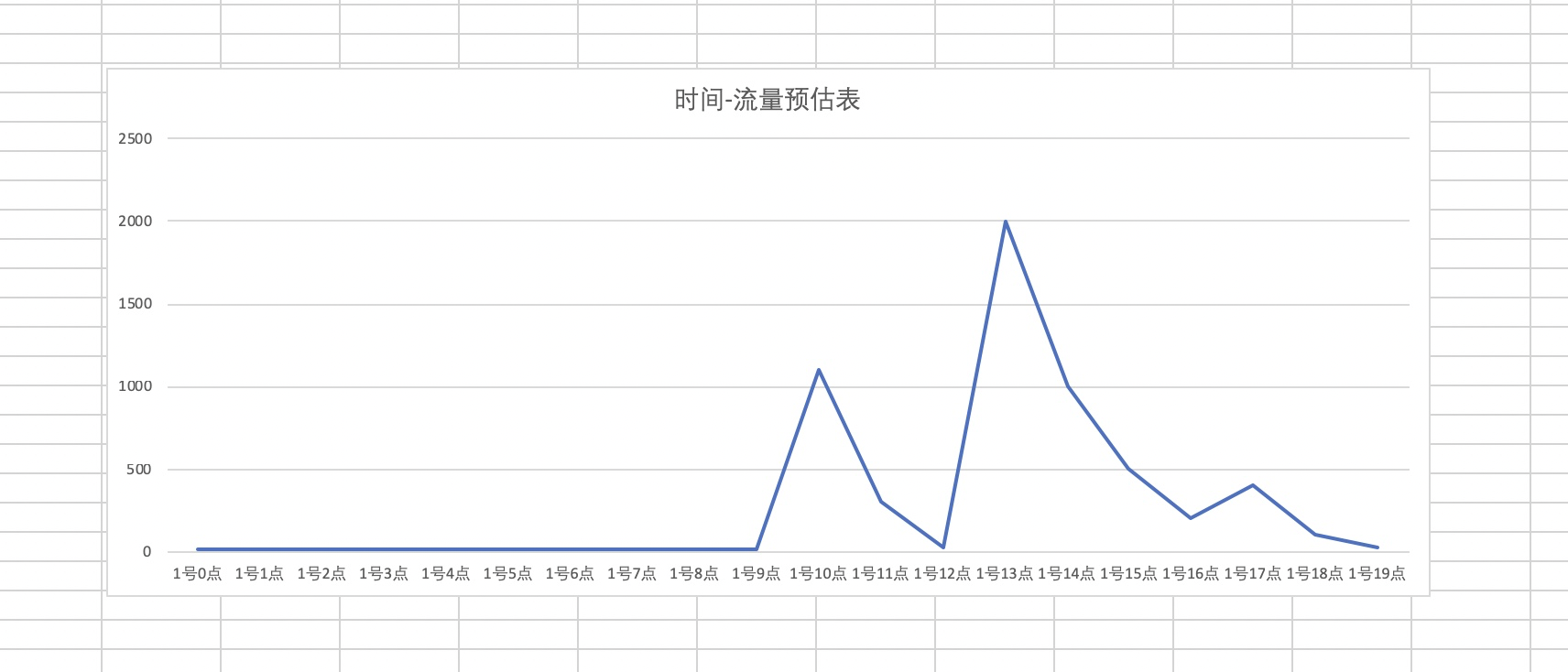
至此产品侧的流量预估思路已经介绍完了,我们已经得到了每天的峰值进入页面的用户预估qps的峰值及出现时间点,后续的方案制定、资源扩容、监控对比发现异常情况等。
我们已经完成了产品侧的正常进入页面的用户流量预估,但是用户流量真正到web资源或API的转化是什么样的,需要结合具体的活动的形式来分析。
技术测流量预估
可以虚构一个这样的活动:年底了,为了冲一下app的DAU,你们把剩余的经费全部拿出来做一个摇一摇抽奖活动。
这个活动形式大致是如下:
- 用户进入主页面之后便可以开始摇一摇,摇一摇便向后端发请求,后端来决定是否中奖,中什么
- 用户可以查看个人已经中的奖品,奖品全部是对接第三方券商进行发券。
所以总结起来,服务端有两个api:
- 抽奖接口
- 获奖记录接口
而且我们拿到的预估转化率数据为
静态流量评估及资源计算
前端资源的瓶颈可能会在于带宽,如果使用了CDN需要评估CDN的带宽。
如果没有使用CDN,则需要评估是静态资源的带宽是否ok。
假设这次活动用户进入首页会请求10个资源:
- 3个js文件,大小在1k
- 1个html文件,大小在1k
- 2个css文件大小在2k
- 2张10k图片,存在CDN上
具体的流量和带宽压力计算完成,你就可以去联系op去了解现有的资源状况,是否需要扩充
服务端流量评估及资源计算
后端流量评估,重点关注全流程的服务流量数值
经过一系列评估大致的系统架构图是这样的:
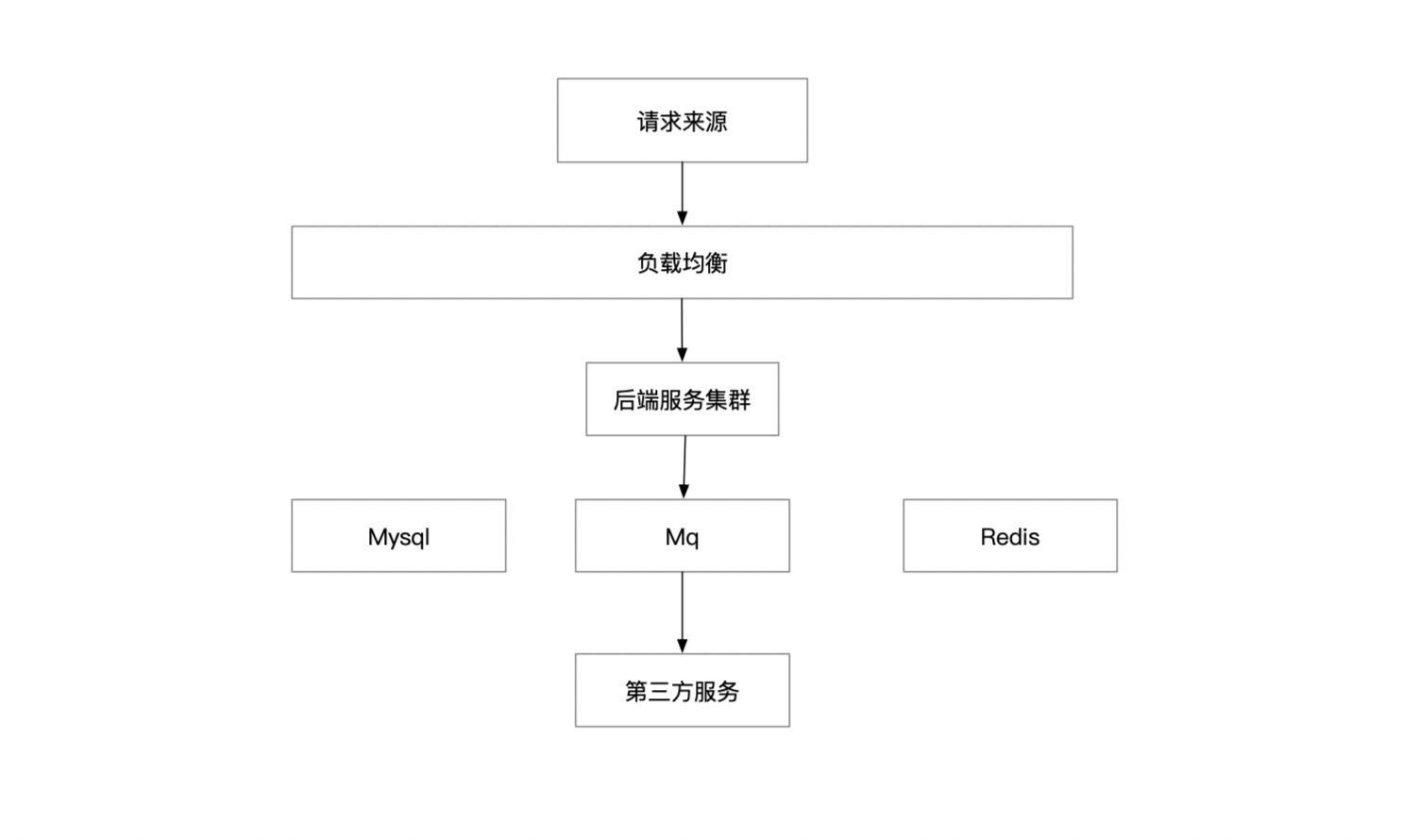
抽奖接口逻辑
- step1: 从redis中获取用户的信用评级,一次redis读
- step2: 概率性决定用户中什么奖品、中奖概率为1%
- step3: 记录mysql用户中奖品及发放状态
- step4: 异步消息发出、控制异步队列并发度为500/s
- step5: 定时脚本扫mysql获取超时未同步状态,再次扔到队列
我们按照这个流程来了解一下服务端流量的评估办法。
备注:假设此时进入页面的用户流量为1w/s 1.负载均衡压力计算: 抽奖接口:抽奖:1w/s * 抽奖转化率 * 人均抽奖次数 获奖记录接口: 1w/s * 记录点击转化率 总和: 1w * (0.3 ~ 0.5) * 3 + 1w * 0.01 = 9k ~ 15k 2.服务集群容器承压计算: 同负载均衡计算 3.Mysql压力 抽奖同步记录中奖记录: 1w/s * 中奖概率 = 100/s 写 异步同步第三方查奖品同步状态及记录同步状态:100/s读 + 100/s写 用户查看获奖记录:1w/s * 个人记录点击转化率 = 100/s 定时脚本扫描看未同步成功记录:可忽略不记 总和:200/s写 + 200/s读 4.Redis压力 获取用户的信用评分,提前灌入库中,与抽奖接口一致 5.Mq写压力 1w/s * 中奖概率 + error重试 ~ 100/s 6.第三方发券接口 根据第三方奖品分配的概率计算,假设就1个tp,那么压力等同于Mq写压力。
目前服务端各组件的流量分布都已经有了一个比较清晰的计算,结合前面的时间-页面流量趋势图,你也可以绘制出一个服务各组件压力图,判断你的峰值会出现在哪里,哪个部位会成为压力瓶颈。
小结
这篇文章重点介绍了我进行活动流量预估的办法,总结下来就几点:
- 有全局视角,了解流量将会从哪里来、分布到哪里、哪些部分会成为压力
- 流量预估应该在需求确定之后、设计方案制定阶段得到确定,为资源的到位提供时间保证
- 静态资源重点在于带宽计算、服务端重点在于全流程的梳理
- 上面的一切也都是我的做法,可能也会有很多不准确的地方。相信你应该有自己的计算方法
2.作弊与反作弊主题交流
在互联网的世界中充斥着各种作弊行为,这篇文章主要介绍一下我对于互联网中作弊与反作弊的理解与看法。文章的大致结构如下:
- 文章首先看一下一些常见的作弊场景及动机
- 总结一些技术手段及方法论
- 谈一谈个人对于作弊与反作弊的一些见解
常见的作弊场景
在大多数人看来,作弊是一个贬义词。
本篇文章中我所提到的作弊的概念并没有任何偏向。
所有通过技术手段模拟人操作的行为都称为作弊,无关后果。
实际上在现实社会中,作弊并不一定总是有害的。这个世界并不是非黑即白的,对吧。
下面我举几个作弊的实例:
- 内容抓取就是一种常见的作弊也是最早期的作弊形式,google、baidu这一批搜索引擎都是建立在spider技术的基础之上。
- 刷帖、刷票、刷量、app刷榜是出于营销目的的互联网作弊。流量为王的年代,如果让自己的帖子、店铺、app得到更高的展现,这里也涉及着巨大的利益。之前是贴吧,现在是公众号、抖音。
- 刷单、活动薅羊毛等直接对互联网企业产生巨大的损失的作弊行为。比如拼多多在今年年初的时候,因为配置错误,导致的话费充值被刷,损失在kw以上。
。。。。
场景很多,手段也很多。
有利益的地方就一定有人,黑产市场的规模是百亿级别,而且技术水平、设备、资本非常充裕。
大致分为几类:
- 利用sql注入等漏洞,拖走你的用户库,暗线交易,这部分做的数据生意
- 批量注册账户,流量作弊,增加曝光,这部分做的是流量的生意
- 羊毛党,利用海量真机、虚假用户在各类活动及app拉新期间规模化薅羊毛。这部分是真钱流失
- 通过刷贴、刷评论恶意诋毁对手。
作弊手段及常用工具
下面介绍一些黑产或者民间常用的工具及手法:
1.选择合适的语言准备模拟浏览器行为,例如python系列
python使用urllib + 构造headers + xpath 基本上可以解决所有站点的代码上的需求,包括html解析、json解析、模拟登陆等,这仅仅是语言层次的
2. 手机号池(易码等平台)
下面要解决的是注册和登陆问题,如何快速完成账号注册?易码等短信平台可以帮你解决短信验收码收发流程的自动化,收费标准在1分钱一条左右。
易码平台入口
3.IP代理池解决IP封禁问题(蜻蜓代理等)
很多app在注册时候都有IP频次限制,这时候你需要一个IP代理池来解决被封禁的问题。几十万的ip
蜻蜓代理
4.海量购买真机 + 群控软件
这一方面也体现了黑产的技术成熟度和资本雄厚,群控软件可以完成一台电脑到上千部手机的控制。手机价格基本是200块左右。
这个技术使用
群控软件
5. 直接上真人
作弊也需要考虑产出-收益比,只要能够有收益,直接上真人也是一种解决办法。
比如,直接雇佣一些廉价劳动力,每下载一个app给5毛钱,现实生活中这也是存在的。
6. 验证码破解
早期的文字验证码形式早已经无法挡住现代人的聪明智慧,OCR识别可以迅速完成破解。
滑块验证码是最近出现的一种新型验证码,生成算法一般是抠图+模糊或者填充其他颜色,使用TensorFlow也可以完成破解了,滑块验证码破解
7. 模拟浏览器操作行为
基于html的服务,本质上是在操作dom,selenium等工具也可以完成此类问题的破解。
还记得以前使用的an jian
以上是我所了解一些常见的作弊的方法和手段,当然肯定还有很多其他更高深的技术手法我每了解到。
现在信息技术传播非常迅速,作弊与反作弊相关的技术也都是彼此透明,黑产一定程度上对于产业也是有促进作用。
反作弊手段及方法
反作弊手段我在我的公众号里简单的写过,https://mp.weixin.qq.com/s/Z-Au4PEFFMjA7yIkFVPLzg 感兴趣可以私信我
3.常见运营后端解决方案
对于开发而言,大部分的精力其实在于代码怎么写。
一个人的代码写成什么样?取决于他的思路、他的价值观、他的自律程度及他的代码见识
web技术发展到现在,在开发过程中你几乎不需要关心tcp的细节(我也不是非常懂)你就可以完成你的工作,交付你的价值
1.抢购类解决方案
抢购类问题是网上讨论比较热烈的部分,比如小米的饥饿营销,这类文章也常常被冠以高并发类问题的名号。
当然,以现在的技术发展来看,这类问题似乎已经没那么难以解决,当然同样充满挑战(我其实没做过)
- 首先,bat等公司或者外部云设施在负载均衡或者叫做接入层的地方有足够的抗压和限流能力(基于总流量拒绝和ip级别流量限制)
- 其次,抢购类问题一般是99.9%的流量都是无效流量,产品流程上的涉及可以帮助过滤到很多无效的流量
- 最后,mysql和redis的分布式发展使得读扩展能力非常强劲。
下面举个简单的栗子:
你们公司有100部手机,在4点钟准点开抢,你来完成这项工作,预估黑产+正常用户将有1w/s的抢购流量。
如何操作?
- 静态资源上CDN,前端页面尽可能小,解决带宽问题
- 99.9的流量是无效流量,负载均衡做好限流,限流速度按照你的server服务能力放行
- 假设放行1000/s的流量到后端,很可能有900/s是黑产流量,采用提到的反作弊手段进行过滤 + 前置任务进行过滤
- 验证后的流量寥寥无几,使用后面提到的mysql库存如何安全扣减解决。
所以整体核心思想是:
静态资源上CDN + 端配合减少无效流量 + 负载均衡做好限流 + 反作弊验证 + mysql库存安全扣减
2.抽奖类解决方案
待完善
3.积分兑换类解决方案
积分兑换类问题是我们目前见到的形式最多的、也是最常用的活动模式。
其变种可以是:
完成xxx任务,赠送xxx金币,每个xx金币可以完成xxx的兑换
完成几次xx任务,即可兑换xxx
问题最终抽象为:商品 + 账户两个子模块。
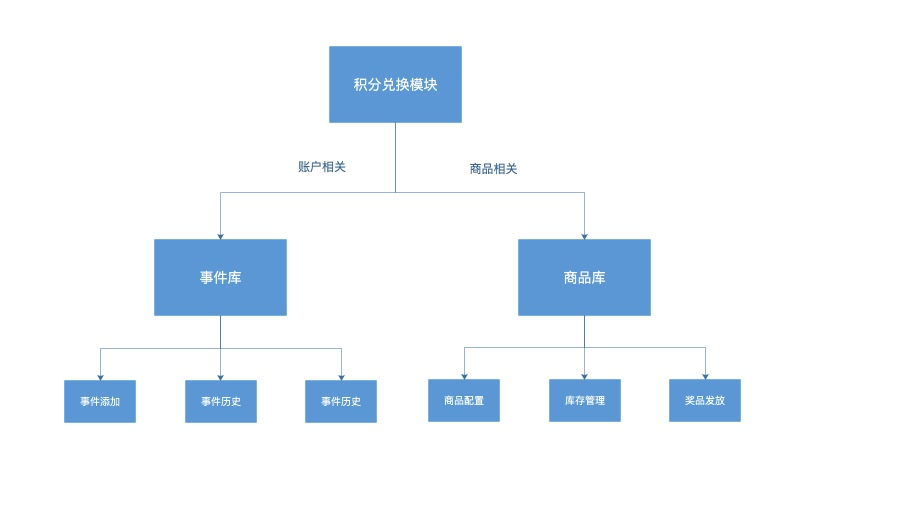
商品模块负责接入商品、
账户模块负责积分、扣分、记录变更。
4.多第三方卡券发放类问题解决方案
我们的活动形式中也有很多是调用第三方服务进行卡券发放
比如春节活动,摇一摇红包,摇到的券非常多样
但是每个第三方的服务能力是不一定的,所以一般的解决方案是:
同步记录中奖记录 + 消息队列发放 + 定时脚本失败重试
常见子问题
1.库存类问题
我之前写过一个关于mysql库存安全的问题的文章见 https://www.cnblogs.com/zhaoyixing/p/12650619.html
监控报警及关键指标统计
代码写完并不代表项目的完结,你的活动写完之后放到线上如何知道活动运行是ok的?如何实时获取运营状态、发现运行问题、如何在服务出现问题的第一瞬间你比用户反馈要早一步?
同时,产品设计的按钮位置的转化是否ok?首日的参与活动数据是否有异常?调整的策略是否生效?
等等上述问题都需要监控报警&数据统计来完成。
下面几项工作需要研发跟进完成的。
1.日志埋点
服务端的日志埋点更多是为了发现服务运营状态、用户投诉问题追查。
之前在讲logid这篇文章的时候有提到过我们需要监控的日志类型:
- access_log 请求来源日志及状态
- error_log nginx errorlog中的具体错误,比如超时,file not find
- php-error php运行过程是否有问题
- ral日志 下游资源请求方的监控,包含mysql状态、redis状态等等
2.添加监控及报警
这部分不展开了
3.数据报表及用户信息查询MIS
数据报表工作的应该排期在你的工作量范畴之内,这是方便PM去发现问题&回归收益的重要依据。
例如:
1.参与活动有多少人,与前端埋点是否对得上,是否有直接的黑产刷量?
2.每个用户参与几次?
3.成单多少人?
。。。
监控、数据、报警可以帮助你发现你写代码中未知的问题及测试未测试到的问题。是对活动质量有把控的重要一环,也是我每次活动必须要完成的工作。
4.压测方案
这篇文章来看一下压力测试的方案,实际上在现实生活中我只使用过ab进行单接口的压力测试。
后面整体的目录围绕几个方面进行:
- 单接口压测方式
- 切流量压测方式
- 业界全链路压测方式
单接口压测方式
现在网上压测的工具也非常多,我们经常使用的是apache ab工具。
使用也非常简单,指定请求数和并发度及url,你会得到一份报表:
ab -n 1000 -c 10 "http://xxxx/_book/cheating-vs-anticheating.html" Server Software: Apache Server Hostname: Server Port: 8080 Document Path: /_book/cheating-vs-anticheating.html Document Length: 37505 bytes Concurrency Level: 10 Time taken for tests: 17.861870 seconds Complete requests: 1000 Failed requests: 0 Write errors: 0 Total transferred: 38033440 bytes HTML transferred: 37546985 bytes Requests per second: 55.99 [#/sec] (mean) Time per request: 178.619 [ms] (mean) Time per request: 17.862 [ms] (mean, across all concurrent requests) Transfer rate: 2079.40 [Kbytes/sec] received
几个ab常见问题及解决方案
1.如何测试post请求
ab默认是不支持post的,但是对于我们后端来说get和post是合并的,所以只需要把post的参数构造到get参数中
2.如何构造不同的账户
目前我们的pass账户是通过账户cookie反解的,线上你可能没有这么多的cookie,我们的做法是。在测试环境把账户随机改为一个uid数值
ab一定程度上可以帮助你发现你单接口的问题,及性能上限,但是局限于测试环境,线上无法使用
切流量方式压测
线上公司常用的一种方式,或者说外部公司也有很多采用这种办法进行测试。
具体办法: 通过在负载均衡处调整权重,让一台机器或者一个地域去承载更大流量,测试单机性能
适用场景及局限: 适用于读接口或者单机测试,流量调度的方式不会带来新的更多的流量
比如传统的检索,倒排数据都以文件方式配送到bs服务在的机器上,不会直接依赖mysql、redis或者其他第三方
但是电商可能不太一样,有订单、有支付等等环境
其他公司的全链路压测
全链路压测总结
全链路压测技术上核心解决两个问题:
- 如何构造足够的流量、足够的用户、足够真实模拟场景?
- 进入到真实线上服务的数据如何着色或者如何打标签
第一个问题:足够的流量
采用的也是多worker的分布式压测进程模式,看资料提到他们是把压测工具部署到了CDN集群,具体怎么操作我不清楚。
当然也有很多公司,是在内网部署的,但是这种模式,你的网卡会有一半消耗在出请求上
第二个问题:足够的用户
分布式压测工具支持配置词表和每个url的发压qps
一个活动,你可以大概知道进入的qps、N个接口的分布qps,构造好词表。
词表是什么?词表是你的case集合,比如用户id集合等等
第二个问题:如何区分无效数据
请求带标签,全链路的配合。压测数据入影子表、影子库,后续处理。
----
三年前,我信誓旦旦要把这部分自己的感悟整理成册,因为各种原因,没有完整的执行下去,只有部分的草稿片段,脱敏后分享给大家。可能会有部分片段空缺了,那是脱敏后的结果、格式也有点乱,请见谅。
希望能对你有所帮助,还有更多的技术细节和方法论是藏于心中的,如果感兴趣,可以扫我公众号关注我,我们私聊。