
大数据-hadoop-环境搭建
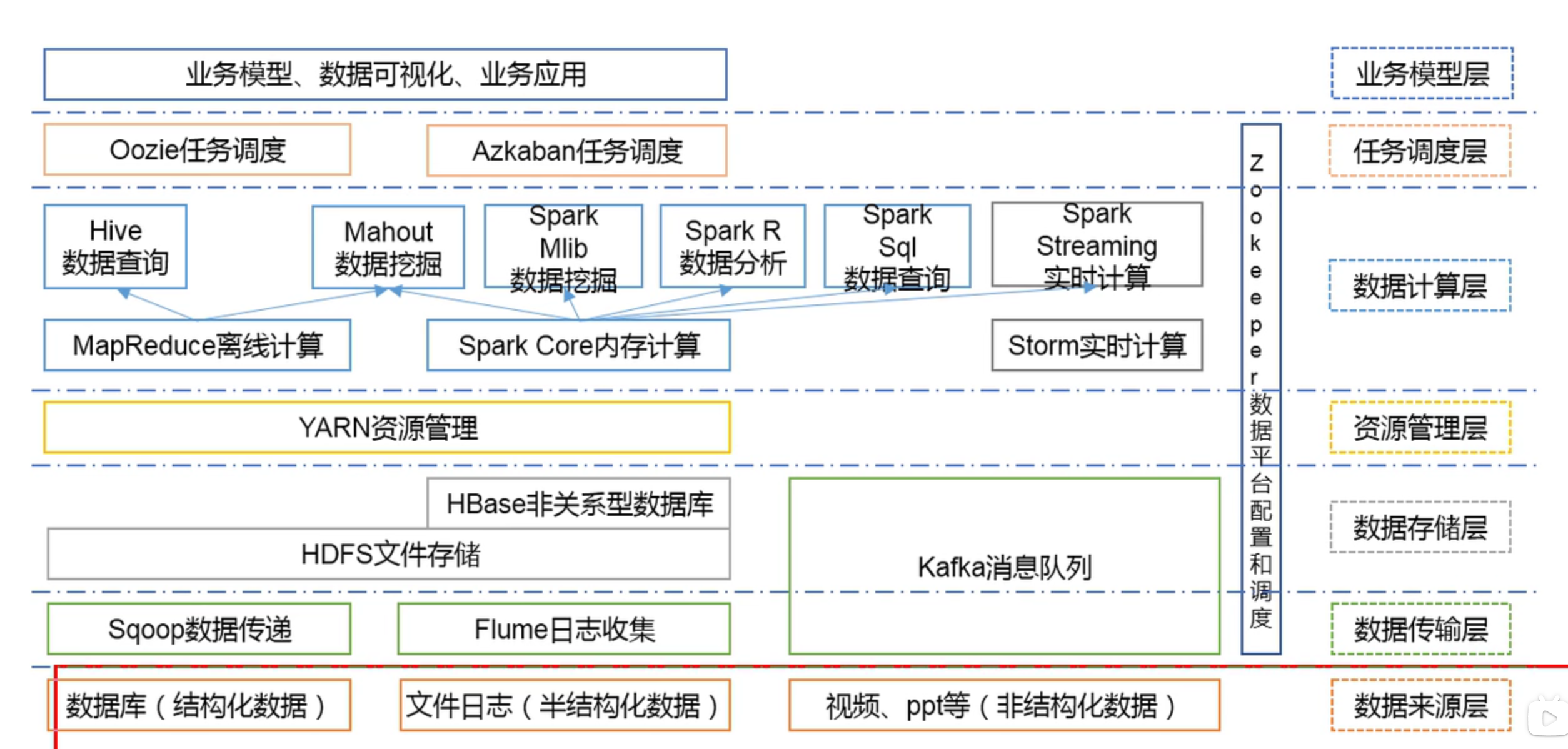
一、大数据技术生态体系
二、虚拟机环境准备
1、克隆虚拟机
在虚拟机上右键-管理-克隆
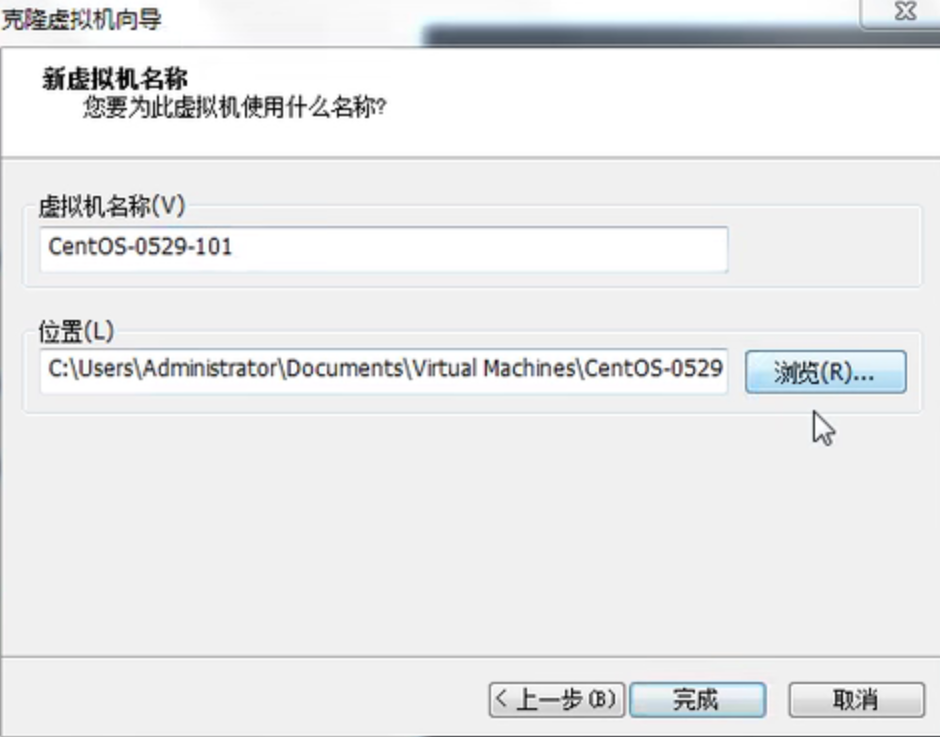
一般的可以把一个虚拟机的环境或者需要的东西都配置好,然后克隆几个,在克隆的虚拟机上进行操作,这样出现了什么问题不至于重新开始配置环境。
2、修改ip地址
尤其对于克隆的虚拟机一定要修改ip地址

对于centos8 :


修改这几个内容,ip可以写成要修改的ip,然后网关和掩码可以通过 nmcli device show来查看,IP4.GATEWAY是网关,IP4.DNS是掩码,有时候网关没有显示,就保持网关和掩码一致即可。
修改完成后,使用
nmcli c reload ens33 来重启网络服务。
这个ens33就是通过ifgonfig查看ip后,ip那一行最开始的东西。

接下来修改主机名称:


通过 检查是否已经配置好了。
检查是否已经配置好了。
在cmd里ping Linux ip,

这就表示已经连上了,
在 linux中 ping windows ip,

就表示windows和linux已经畅通了。
以上就是虚拟机的整个准备流程。
三、jdk的安装
可以直接在Linux中使用命令的方式下载安装,也可以通过xftp将windows里的jdk传过来,然后进行配置安装

使用整个命令,出现下面的内容就表示已经配置安装好了。
四、hadoop的安装
在网上找到了一个很详细的教程:
(14条消息) Centos8安装 Hadoop3 详细操作(含图文)_haoweixl的博客-CSDN博客
(14条消息) 怎么在CentOS Linux 8上安装Hadoop?安装配置Hadoop的详细步骤_Tristone的博客-CSDN博客_centos8安装hadoop
使用这两个教程进行安装配置就足够了

最后显示这样的信息就表示配置完成了!


