python爬虫(十七) 电影天堂爬虫1
电影天堂里面的
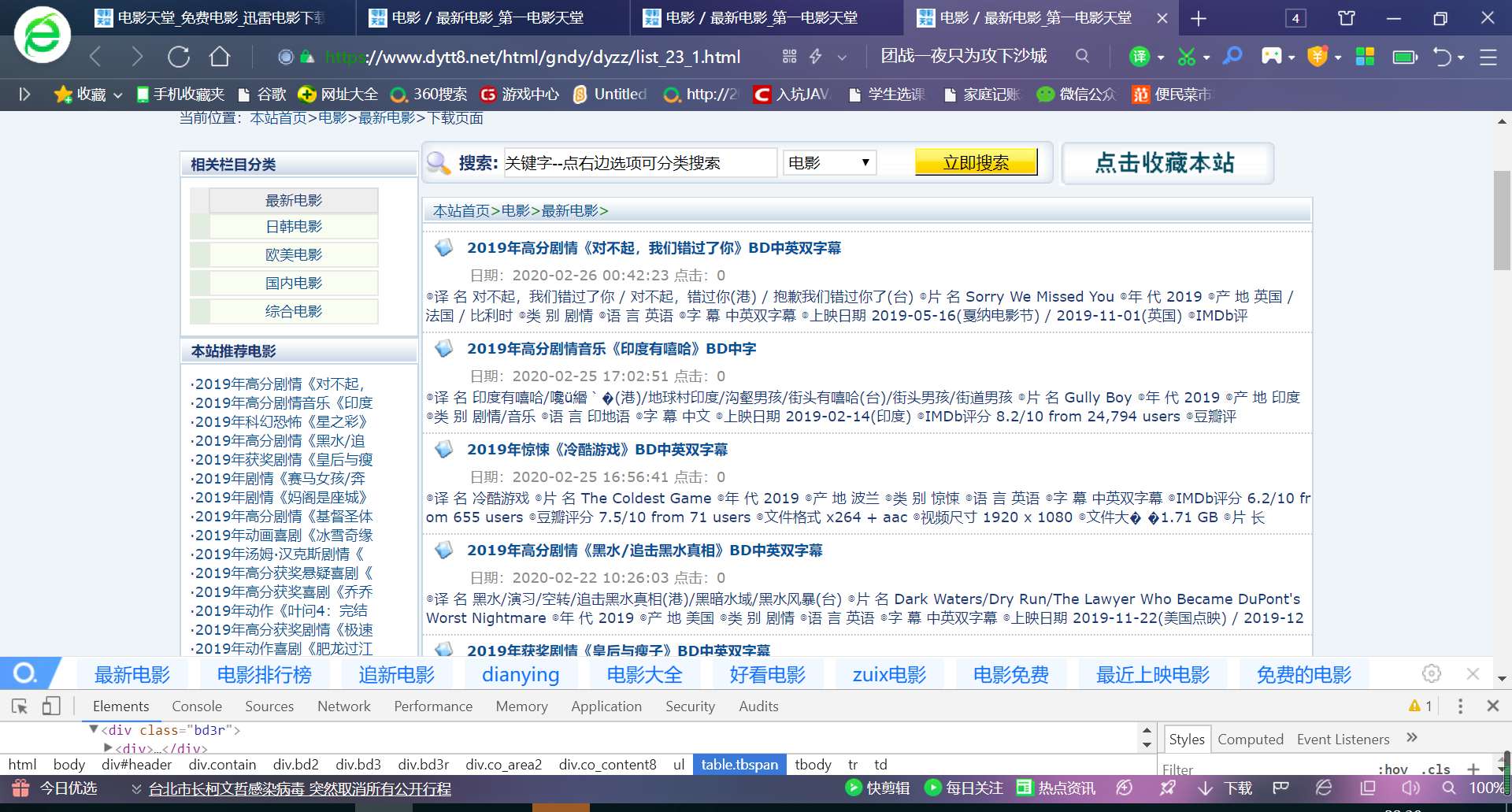
要爬取这个页面里所有的电影信息,每个电影信息都在另一个html里,先在这里页面里把这些电影的url爬取出来
# 电影天堂爬虫 from lxml import etree import requests # 一个网址头 BASE_DOMAIN="https://www.dytt8.net" url="https://www.dytt8.net/html/gndy/dyzz/list_23_1.html" headers={ 'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36" } response=requests.get(url,headers=headers)
text=response.text
html=etree.HTML(text) detail_urls=html.xpath("//table[@class='tbspan']//a/@href") for detail_url in detail_urls: print(BASE_DOMAIN+detail_url)
结果:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号