


数据清洗
写到了数据统计,排序。完成了第二步。
第一步的数据清洗代码为:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class QX {
public static class LogParser{
public String[] parse(String line) {
String ip = parseIP(line);
String time = parseTime(line);
String traffic = parseTraffic(line);
String con = parseCon(line);
return new String[] {ip, time, traffic, con};
}
private String parseIP(String line) {
String ip = line.split("- -")[0].trim();
return ip;
}
private String parseTime(String line) {
final int first = line.indexOf("[");
final int last = line.indexOf("+0800]");
String time = line.substring(first+1, last).trim();
return time;
}
private String parseTraffic(String line) {
String s[] = line.split(" ");
return s[9];
}
private String parseCon(String line) {
String s[] = line.split(" ");
return s[11];
}
}
public static class Map extends Mapper<LongWritable, Text, LongWritable, Text> {
LogParser logParser = new LogParser();
Text outputValue = new Text();
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, LongWritable, Text>.Context context) throws IOException, InterruptedException {
if(value.toString().split(" ").length >= 25) {
final String[] parsed = logParser.parse(value.toString());
String type = "";
if(value.toString().split(" ")[11].contains("video")) {
type = "video";
}else if(value.toString().split(" ")[11].contains("article")) {
type = "article";
}else {
return;
}
int a = value.toString().split(" ")[11].lastIndexOf("/");
int b = 0;
if(value.toString().split(" ")[11].contains("?")) {
b = value.toString().split(" ")[11].lastIndexOf("?");
}else if(value.toString().split(" ")[11].contains(".")) {
b = value.toString().split(" ")[11].lastIndexOf(".");
}
String id = "";
if(b > a) {
id = value.toString().split(" ")[11].substring(a+1, b);
}else {
id = value.toString().split(" ")[11].substring(a+1, value.toString().split(" ")[11].length()-1);
}
outputValue.set(parsed[0]+","+parsed[1]+","+parsed[1].substring(0,2)+","+parsed[2]+","+type+","+id);
context.write(key, outputValue);
}
}
}
public static class Reduce extends Reducer<LongWritable, Text, Text, NullWritable> {
protected void reduce(
Text k2,
java.lang.Iterable<Text> v2s,
org.apache.hadoop.mapreduce.Reducer<Text, Text, Text, NullWritable>.Context context)
throws java.io.IOException, InterruptedException {
for (Text v2 : v2s) {
context.write(v2, NullWritable.get());
}
};
}
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new String[2];
otherArgs[0] = "hdfs://localhost:9000/log.log";
otherArgs[1] = "hdfs://localhost:9000/out";
Job job = new Job(conf, "SHQX");
job.setJarByClass(QX.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
然后把运行出来的已经清洗的文件放到hive中
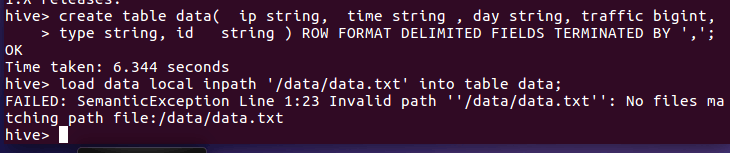
第二步进行数据统计:
步骤为:
然后
2.1
insert overwrite local directory '/data/datass/top10' row format delimited fields terminated by ',' select id, type, count(1) count from data group by id,type order by count desc limit 10;
2.2
insert overwrite local directory '/data/datass/iptop10' row format delimited fields terminated by ',' select ip, id, type, count(1) count from data group by ip,id,type order by count desc limit 10;
2.3
insert overwrite local directory '/data/datass/traffictop10' row format delimited fields terminated by ',' select traffic, id, type, count(1) count from data group by traffic,id,type order by count desc limit 10;


