
Mapreduce实例——WordCount
实验步骤
- 切换目录到/apps/hadoop/sbin下,启动hadoop。
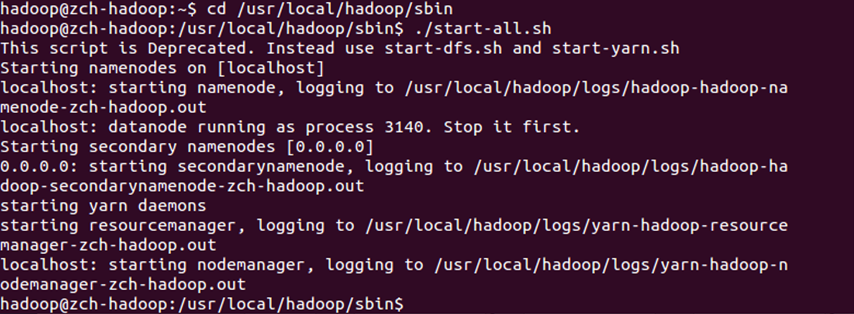
cd /apps/hadoop/sbin
./start-all.sh
2.在linux上,创建一个目录/data/mapreduce1。

mkdir -p /data/mapreduce1
3.切换到/data/mapreduce1目录下,自行建立文本文件buyer_favorite1。
依然在/data/mapreduce1目录下,使用wget命令,从
网络下载hadoop2lib.tar.gz,下载项目用到的依赖包。
将hadoop2lib.tar.gz解压到当前目录下。
tar -xzvf hadoop2lib.tar.gz
4.将linux本地/data/mapreduce1/buyer_favorite1,上传到HDFS上的/mymapreduce1/in目录下。若HDFS目录不存在,需提前创建。
- hadoop fs -mkdir -p /mymapreduce1/in
- hadoop fs -put /data/mapreduce1/buyer_favorite1 /mymapreduce1/in
5.打开Eclipse,新建Java Project项目。并将项目名设置为mapreduce1。
6.在项目名mapreduce1下,新建package包。并将包命名为mapreduce 。
7.在创建的包mapreduce下,新建类。并将类命名为WordCount。
8.添加项目所需依赖的jar包,右键单击项目名,新建一个目录hadoop2lib,用于存放项目所需的jar包。
9.添加代码
10.打开终端或使用hadoop eclipse插件,查看hdfs上,程序输出的实验结果。


hadoop fs -ls /mymapreduce1/out
hadoop fs -cat /mymapreduce1/out/part-r-00000


