

云原生第九周--skywalking链路追踪
skywalking
Skywalking介绍
Skywalking是一个国产的开源框架,2015年有吴晟个人开源,2017年加入Apache孵化器,国人开源的产品,主要开发人员来自于华为,2019年4月17日Apache董事会批准SkyWalking成为顶级项目,支持Java、.Net、NodeJs等探针,数据存储支持Mysql、Elasticsearch等,跟Pinpoint一样采用字节码注入的方式实现代码的无侵入,探针采集数据粒度粗,但性能表现优秀,且对云原生支持,目前增长势头强劲,社区活跃。
Skywalking是分布式系统的应用程序性能监视工具,专为微服务,云原生架构和基于容器(Docker,K8S,Mesos)架构而设计,它是一款优秀的APM(Application Performance Management)工具,包括了分布式追踪,性能指标分析和服务依赖分析等。
分布式链路追踪需求分析及功能简介
当前面临的业务环境:
- 业务系统是使用复杂的、大规模的分布式集群实现,并且有服务很多服务组成。
- 每个项目里面的服务可能使用不同的软件模块或开发框架。
- 每个项目里面的服务可能使用不同的编程语言开发。
- 服务可能运行在数千台服务器,并且分布在不同的数据中心运行,对管理和监控产生挑战。
- 因此需要有专门的工具去跟踪请求、理解整体系统的瓶颈和近实时的表现,假如一个请求太慢,那么要通过工具可以快速的找到问题所在。
dapper简介
针对dapper的设计要求:
- 无处不在的部署:任何服务都应该被监控到,任何服务出问题都要做到有据可查。
- 持续的监控:做到7*24小时全天候监控,任何时候出了问题都要基于监控数据追踪问题根源。
针对dapper的设计目标:
- 低消耗:dapper跟踪系统对服务的影响应该做到最小,在一些高并发的场合,即使很小的影响也可能会导致服务出现延迟、负载变高或不可用,从而导致业务团队可能会停止dapper系统。
- 对应用透明:应用程序对dapper系统无感知甚至不知道dapper系统的存在,假如一个跟踪系统必须依赖于应用的开发者配合才能实现跟踪,也即是需要在应用中植入跟踪代码,那么可能会因为代码产生bug或导致应用出问题。
- 可伸缩性:针对未来众多的服务和大规模业务集群,dapper系统应该能满足未来在性能的压力和功能上的需求。
请求链路:
图中展现的是一个有5台服务器相关的一个服务,包括:前端(A),两个中间层(B和C),以及两个后端(D和E),当一个用户(这个用例的发起人)发起一个请求时,首先到达前端(A),然后发送两个RPC到服务器B和C,B收到请求后会马上做出响应,但是C需要和后端的D和E交互之后再返还给A,由A来响应最初的客户请求,对于这样一个请求,简单实用的分布式跟踪的实现,就是为服务器上每一次发送和接收动作来收集跟踪标识符(message identifiers)和时间戳(timestamped events)。
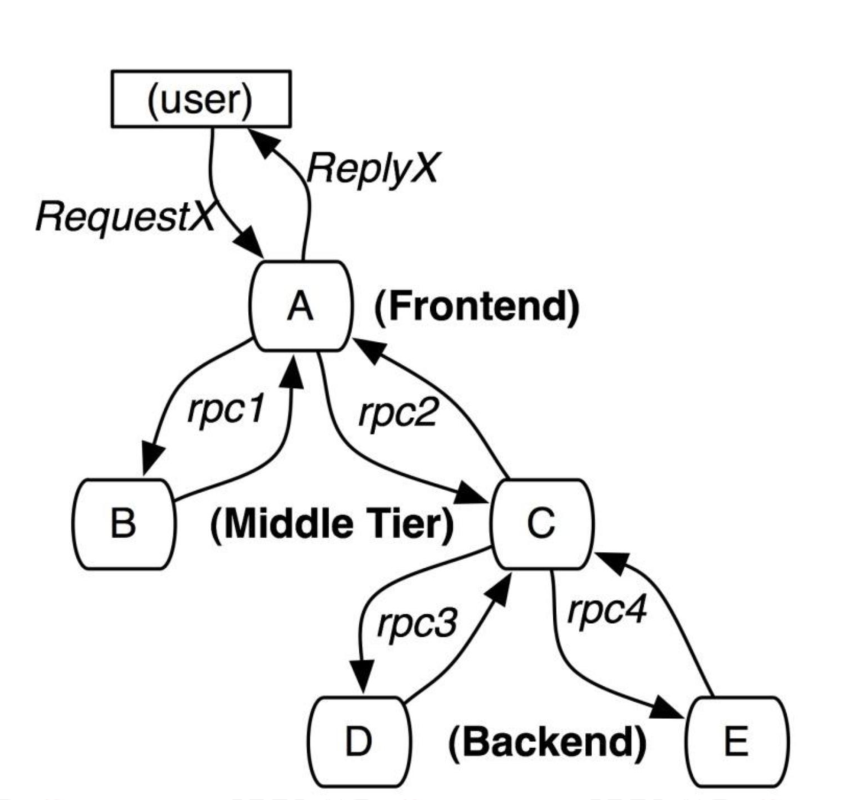
基于dapper或类似的跟踪系统,可以跟随客户的完整请求流程,从前端服务接受客户请求开始到全部后端服务处理完成并经过前端给客户端返回数据,将完整请求链路经过的每一个服务信息的耗时都进行收集并进行统一存储和展示、方便运维人员快速定位问题。
数据采集方法:
黑盒法(black-box):
黑盒法无需任何侵入性代码,它的优势在于无需修改代码,缺点在于记录不是很准确,且需要大量数据才能够推导出服务间的关系。
标记法(annotation-based):
标记法需要为每个请求打标记,并通过一个全局标识符将请求途径的所有服务信息串联,复盘整个链路。标记法记录准确,但它的缺点也很明显,需要将标记代码注入到每个服务中。
跟踪树和span:
Span 代表系统中具有开始时间和执行时长的请求跨度,Span之间通过嵌套或者顺序排列建立逻辑因果关系。s
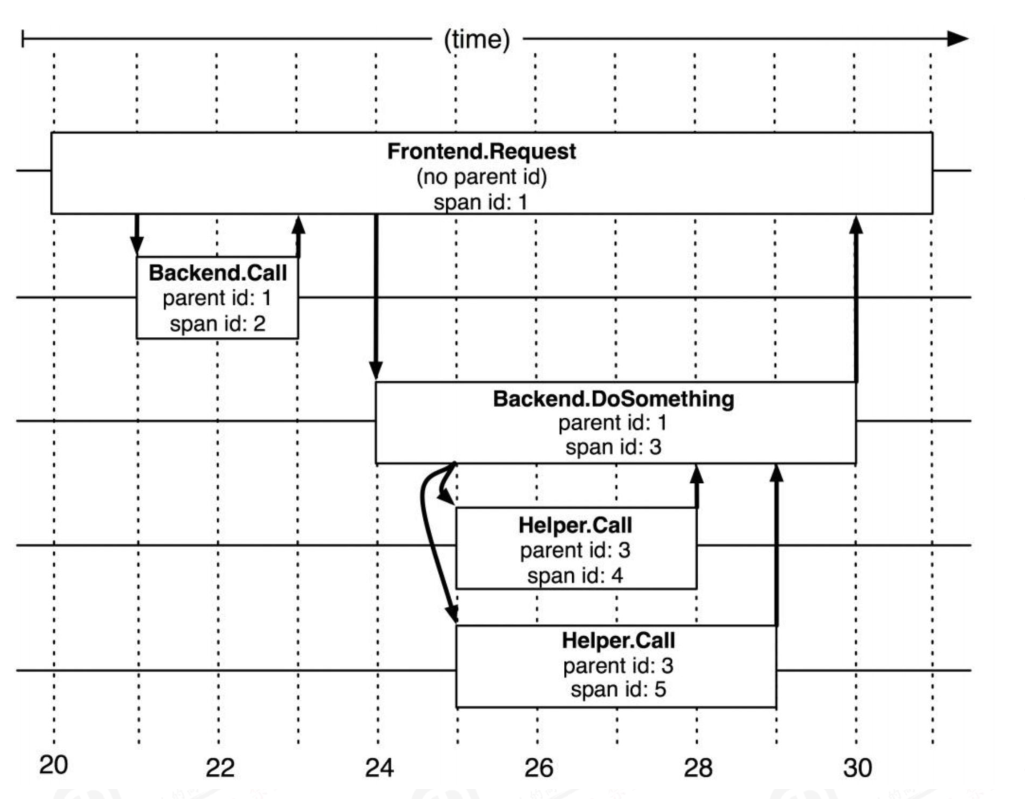
在Dapper跟踪树结构中,树节点是整个架构的基本单元,是请求从前端到后端不同应用之间层级机构,而每一个节点又是对span的引用,节点之间的连线表示的span和它的父span之间的关系。
在图中说明了span在一个大的跟踪过程中是什么样的,Dapper记录了span名称,以及每个span的ID和父ID,以重建在一次追踪过程中不同span之间的关系,如果一个span没有父ID被称为root span,所有span都挂在一个特定的跟踪上,也共用一个跟踪id(traceId在 图中未示出),所有这些ID用全局唯一的64位整数标示,在一个典型的Dapper跟踪中,我们希望为每一个RPC对应到一个单一的span上,而且每一个额外的组件层都对应一个跟踪树型结构的层级。
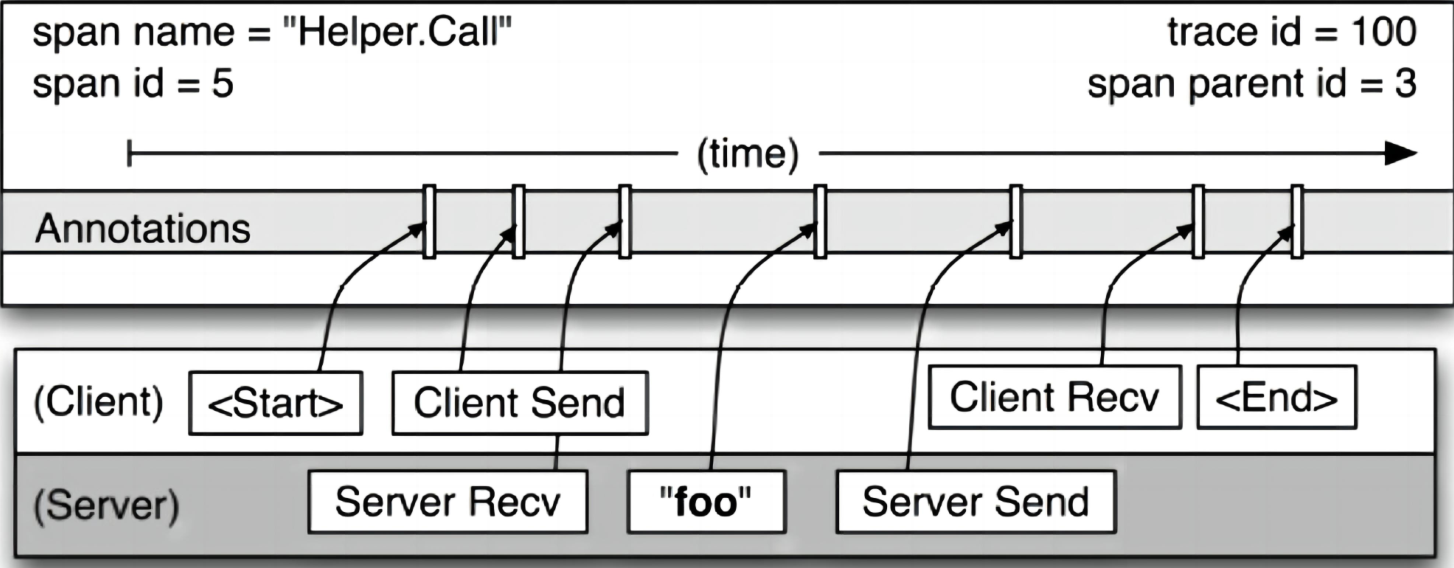
任何一个span可以包含来自不同的主机信息,这些也要记录下来,事实上每一个RPC span可以包含客户端和服务器两个过程的注释,使得链接两个主机的span会成为图中所说的span,由于客户端和服务器上的时间戳来自不同的主机,还必须考虑到时间偏差,在分析工具就利用了时间偏差,即RPC客户端发送一个请求之后,服务器端才能接收到,对于响应也是一样的(服务器先响应,然后客户端才能接收到这个响应),这样一来,服务器端的RPC就有一个时间戳的一个开始和结束,然后就可以计算出时间损耗。
traceid 、spanid、parentid
spanid 跨节点就会变化 可以前后进行排序
parentid 在同一层级是一样的。parentid越小层级越高
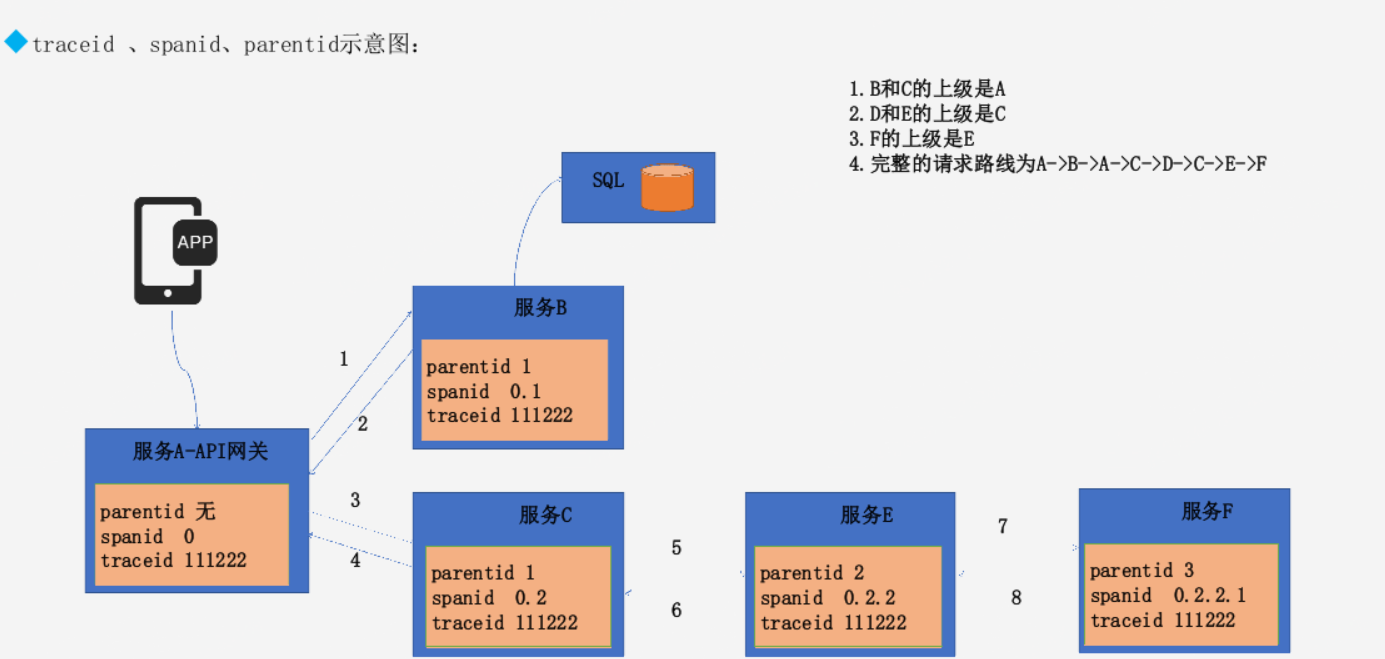
如图可见
第一次请求 没有parnetid spanid为0(新产生)traceid跟踪id新产生且同一请求不会变化;当服务向后转发B时,parentid会加1,表示次请求向后转发过一次,也表示自己是之后转发服务的上游服务,spanid变成0.1;
而服务向后转发c时,由于都是从服务A转发,层级与服务B相同,因此parentid也是1,而spanid为0.2表示与服务B同级切在服务B之后转发;而服务E是由服务C转发,因此parentid加一,spanid为0.2.2表示是服务c的下一层级;
服务F与服务E同理;
植入
Dapper可以实现对应用开发者近乎零浸入的成本对分布式请求链路进行跟踪,主要通过通用组件库实现:
当一个线程在处理跟踪请求链路的过程中,Dapper把这次跟踪的上下文在ThreadLocal中进行存储,追踪上下文是一个小而且容易复制的空间,其中记录了span 的属性信息,比如跟踪ID和span ID。
当用户的请求处理过程是延迟调用的或是异步的,大多数Google开发者通过线程池或其他执行器,使用一个通用的控制流库来回调,Dapper确保所有这样的回调可以存储这次跟踪的上下文,而当回调函数被触发时,这次跟踪的上下文会与适当的线程关联上。在这种方式下,Dapper可以使用trace ID和span ID来辅助构建异步调用的路径。
几乎所有的Google的进程间通信是建立在一个用C++和Java开发的RPC框架上。我们把跟踪植入该框架来定义RPC中所有的span,span的ID和跟踪的ID会从客户端发送到服务端,像那样的基于RPC的系统被广泛使用在Google中,这是一个重要的植入点,当那些非RPC通信框架发展成熟并找到了自己的用户群之后,我们会计划对RPC通信框架进行植入。
Annotation:
Dapper还允许应用程序开发人员在Dapper跟踪的过程中添加额外的信息,以监控更高级别的系统行为,或帮助调试问题,Dapper允许用户通过一个简单的API定义带时间戳的Annotation,这些Annotation可以添加任意内容,为了保护Dapper的用户意外的过分热衷于日志的记录,每一个跟踪span有一个可配置的总Annotation量的上限,但是,应用程序级的Annotation是不能替代用于表示span结构的信息和记录着RPC相关的信息
除了简单的文本Annotation,Dapper也支持的key-value映射的 Annotation,提供给开发人员更强的跟踪能力,如持续的计数器,二进制消息记录和在一个进程上跑着的任意的用户数据。键值对的Annotation方式用来在分布式追踪的上下文中定义某个特定应用程序的相关类型。
采样率
低损耗的是Dapper的一个关键的设计目标,因为如果这个工具价值未被证实但又对性能有影响的话,你可以理解服务运营人员为什么不愿意部署它,况且,我们想让开发人员使用Annotation的API,而不用担心额外的开销,另外某些类型的Web服务对植入带来的性能损耗确实非常敏感,因此,除了把Dapper的收集工作对基本组件的性能损耗限制的尽可能小之外,我们还有进一步控制损耗的办法,那就是遇到大量请求时只记录其中的一小部分。
跟踪的代价
在生产环境的跟踪数据处理中,dapper的守护进程从来没有超过0.3%的单核cpu使用率,而且只有很少量的内存使用,另外还限制了Dapper守护进程为内核scheduler最低的优先级,以防在一台高负载的服务器上发生cpu竞争。
Dapper也是一个带宽资源的轻量级的消费者,每一个span在我们的仓库中传输只占用了平均426的byte,作为网络行为中的极小部分,Dapper的数据收集在Google的生产环境中的只占用了0.01%的网络资源。
Dapper应用场景:
- 性能分析:开发人员针对请求延迟的目标进行跟踪,并对容易优化的地方进行定位。
- 正确性分析:发现一些只读请求应该是访问从库但是却访问了主库等类似业务场景。
- 理解系统:全局优化系统,理解每个查询的整体代价。
- 测试新版本:发现新版本的bug和性能问题。
- 解决依赖关系:找到服务之间的依赖关系。
skywalking 功能:
- 实现从请求跟踪、指标收集和日志记录的完整信息记录。
- 多语言自动探针,支持Java、GO、Python、PHP、NodeJS、LUA、Rust等客户端。
- 内置服务网格可观察性,支持从Istio+Envoy Service Mesh收集和分析数据。
- 模块化架构,存储、集群管理、使用插件集合都可以进行自由选择。
- 支持告警。
- 优秀的可视化效果
skywalking 组件:
组件介绍:
- OAP平台(Observability Analysis Platform,可观测性分析平台)或OAP Server,它是一个高度组件化的轻量级分析程序,由兼容各种探针Receiver、流式分析内核和查询内核三部分构成。
- 探针:基于无侵入式的收集,并通过HTTP或者gRPC方式发送数据到OAP Server。
- 存储实现(Storage Implementors),SkyWalking OAP Server支持多种存储实现并且提供了标准接口,可支持不同的存储后端。
- UI模块(SkyWalking),通过标准的GraphQL(Facebook在2012年开源)协议进行统计数据查询和展示 。
设计模式:
- 面向协议设计:面向协议设计是SkyWalking从5.x开始严格遵守的首要设计原则,组件之间使用标准的协议进行数据交互。
- 协议有探针协议和查询协议
探针协议:
- 探针上报协议:协议包括语言探针的注册、Metrics数据上报、Tracing数据据上报等标准,Java、Go等探针都需要严格遵守此协议的标准。
- 探针交互协议:因为分布式追踪环境,探针间需要借助HTTP Header、MQ Header在应用之间进行通信和交互,探针交互协议就定义了交互的数据格式。
- Service Mesh协议:是SkyWalking对Service Mesh抽象的专有协议,任何Mesh类的服务都可以通过此协议直接上传指标数据,用于计算服务的指标数据和绘制拓扑图。
- 第三方协议: 对大型的第三方开源项目 尤其是Service Mesh核心平台Istio和Envoy,提供核心协议适配,支持针对Istio+Envoy Service Mesh进行无缝对接
数据查询协议:
- 元数据查询:查询在SkyWalking注册的服务、服务实例、Endpoint等元数据信息。
- 拓扑关系查询:查询全局、或者单个服务、Endpoint的拓扑图及依赖关系。
- Metrics指标查询: 查询指标数据。
- 聚合指标查询:区间范围均值查询及Top N排名数据查询等。
- Trace查询:追踪数据的明细查询。
- 告警查询:基于表达式,判断指标数据是否超出阈值。
设计与优势
模块化设计:
- 探针收负责集数据
- 前端负责展示数据
- 后端负责从后端存储读写数据
- 后端存储负责持久化数据
轻量化设计:
SkyWalking在设计之初就提出了轻量化的设计理念,SkyWalking使用最轻量级的jar包模式,实现强大的数据处理和分析能力、可扩展能力和模块化能力。
skywalking优势:
兼容性好:支持传统的开发框架dubbo和spring cloud,也支持云原生中的Istio和envoy。
易于部署和后期维护: 组件化,可以自定义部署,后期横向扩容简单
高性能:每天数T的数据无压力
易于二次开发:标准的http和grpc协议,开源的项目,企业可以自主二次开发
skywalking 二进制部署
部署elasticsearch
root@skywalking-es:~# vim /etc/sysctl.conf
net.ipv4.ip_forward = 1
vm.max_map_count=262144
root@skywalking-es:/usr/local/src# dpkg -i elasticsearch-8.5.1-amd64.deb
root@skywalking-es:~# grep -v "#" /etc/elasticsearch/elasticsearch.yml | grep -v "^$"
cluster.name: es1
node.name: node1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.110.208
http.port: 9200
discovery.seed_hosts: ["192.168.110.208"]
cluster.initial_master_nodes: ["192.168.110.208"]
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
xpack.security.http.ssl:
enabled: false
keystore.path: certs/http.p12
xpack.security.transport.ssl:
enabled: false
verification_mode: certificate
keystore.path: certs/transport.p12
truststore.path: certs/transport.p12
http.host: 0.0.0.0
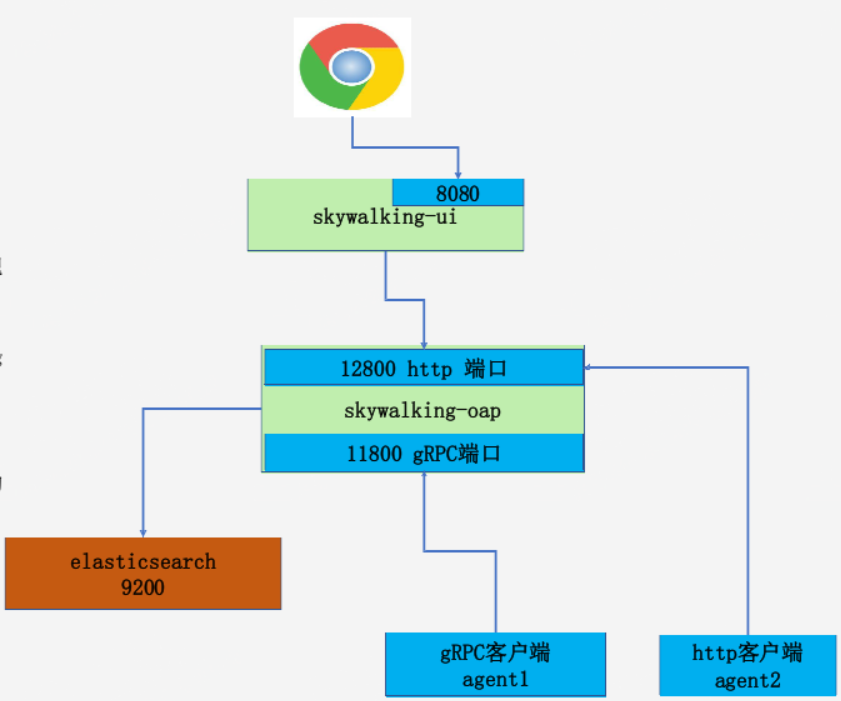
部署skyworking
- skywalking-ui: 前端服务,端口号8080。
- skywalking-oap(Observability Analysis Platform):可观测性分析平台,11800为gRPC数据端口,12800为http数据端口。
- es:9200为elasticsearch的数据读写端口,目前skywalking支持的存储有elasticsearch、h2、mysql、tidb、influxdb、postgresql等。
- agent: app服务器部署skywalking agent,用于收集app中的访问请求。
部署过程
root@skywalking-server:~# apt install openjdk-11-jdk -y
root@skywalking-server:/apps# tar xvf apache-skywalking-apm-9.3.0.tar.gz
root@skywalking-server:/apps# ln -sv /apps/apache-skywalking-apm-bin /apps/skywalking
'/apps/skywalking' -> '/apps/apache-skywalking-apm-bin'
root@skywalking-server:/apps# vim /apps/skywalking/config/application.yml
storage:
selector: ${SW_STORAGE:elasticsearch}
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:192.168.110.208:9200}
root@skywalking-server:/apps# cat /etc/systemd/system/skywalking.service
[Unit]
Description=Apache Skywalking
After=network.target
[Service]
Type=oneshot
User=root
WorkingDirectory=/apps/skywalking/bin/
ExecStart=/bin/bash /apps/skywalking/bin/startup.sh
RemainAfterExit=yes
RestartSec=5
[Install]
WantedBy=multi-user.target
root@skywalking-server:/apps# systemctl daemon-reload && systemctl restart skywalking && systemctl enable skywalking
skywalking web界面介绍:
skywalking仪表盘简介:
普通服务-->服务
Service:服务列表,服务(Service)-表示对请求提供相同行为的一系列或一组工作负载(服务名称),在使用Agent或SDK的时候,可以自定义服务的名字,如果不定义的话,SkyWalking将会使用你在平台(比如 Istio)上定义的名字。
service names:服务名称 Load (calls / min):每分钟访问次数 Success Rate (%):成功率 Latency (ms):验延迟时间 Apdex :应用性能指数
Topology:架构图
Trace:跟踪信息
Log:日志
Apdex简介:
Apdex全称是(Application Performance Index,应用性能指数),是由Apdex联盟开放的用于评估应用性能的标准,Apdex 联盟起源于2004年,Apdex标准从用户的角度出发,提供了一个统一的测量和报告用户体验的方法,将其量化为范围为0-1的满意度评价,把最终用户的体验和应用性能作为一个完整的指标进行统一度量.
在网络中运行的任何一个应用(Web服务),它的响应时间决定了用户的满意程度,用户等待所有交互完成时间的长短直接影响了用户对应用的满意程度,这才是对用户有真正意义的“响应时间”,Apdex把完成这样一个任务所用的时间长短称为应用的“响应性”。
Apdex 定义了应用响应时间的最优门槛为T,另外根据应用响应时间结合T定义了三种不同的性能表现:
- Satisfied(满意)-应用响应时间小于或等于Apdex阈值,比如Apdex阈值为1s,则一个耗时0.6s或者1s的响应结果则可以认为是满意的。
- Tolerating(可容忍)-应用响应时间大于Apdex阈值,但同时小于或等于4倍的Apdex阈值,假设应用设定的Apdex阈值为1s,则4*1=4s为应用响应时间的容忍上限。
- Frustrated(烦躁期)-应用响应时间大于4倍的Apdex阈值。
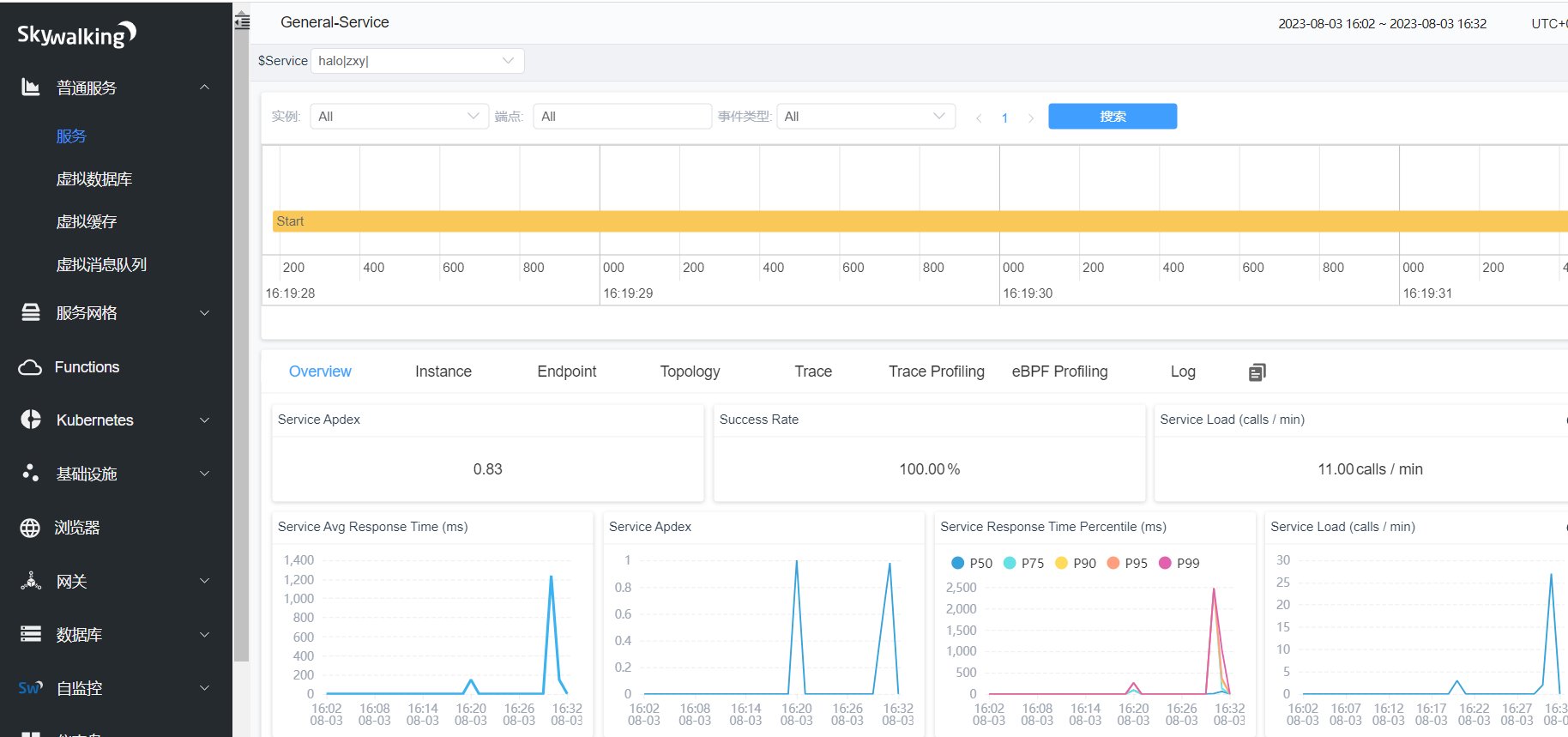
普通服务-->服务--> halo|magedu|-->Overview(服务概览)
Service Apdex(数字):当前服务的评分
Successful Rate(数字):请求成功率
Service Load (calls / min) 数字: 分钟请求数
Service Avg Response Times(ms):平均响应延时,单位ms
Service Apdex(折线图):一段时间内Apdex评分
Service Response Time Percentile (ms)折线图:服务响应时间百分比
Service Load (calls / min) 折线图: 分钟请求数
Success Rate (%)折线图:分钟请求成功百分比
Message Queue Consuming Count(折线图):消息队列消耗计数
Message Queue Avg Consuming Latency (ms)折线图:消息队列平均消耗延迟(毫秒)
Service Instances Load (calls / min):节点请求次数
Slow Service Instance (ms):每个服务实例(物理机、云主机、pod)的最大延时
Service Instance Success Rate (%):每个服务实例的请求成功率
Endpoint Load in Current Service (calls / min):每个端点(URL)的请求次数
Slow Endpoints in Current Service (ms):当前端点(URL)的最慢响应时间
Success Rate in Current Service (%):当前服务成功率(%):
普通服务-->服务--> halo|magedu|-->Instance-->选择实例-->Overview(实例概览信息):
Service Instance Load (calls / min):当前实例的每分钟请求数。
Service Instance Success Rate (%):当前实例的请求成功率。
Service Instance Latency (ms):当前实例的响应延时。
Database Connection Pool:数据库连接池信息
Thread Pool:线程池信息
普通服务-->服务--> halo|magedu|-->Endpoint(端点信息):
Endpoints: URL
Load (calls / min):平均请求次数(默认时间范围半小时),比如半小时内总请求次数6次,6%30=0.20
Success Rate (%):平均成功率(默认时间范围半小时)
Latency (ms):平均延迟时间(默认时间范围半小时)
普通服务-->服务--> halo|magedu|-->Instance-->示例-->Trace(请求跟踪信息):
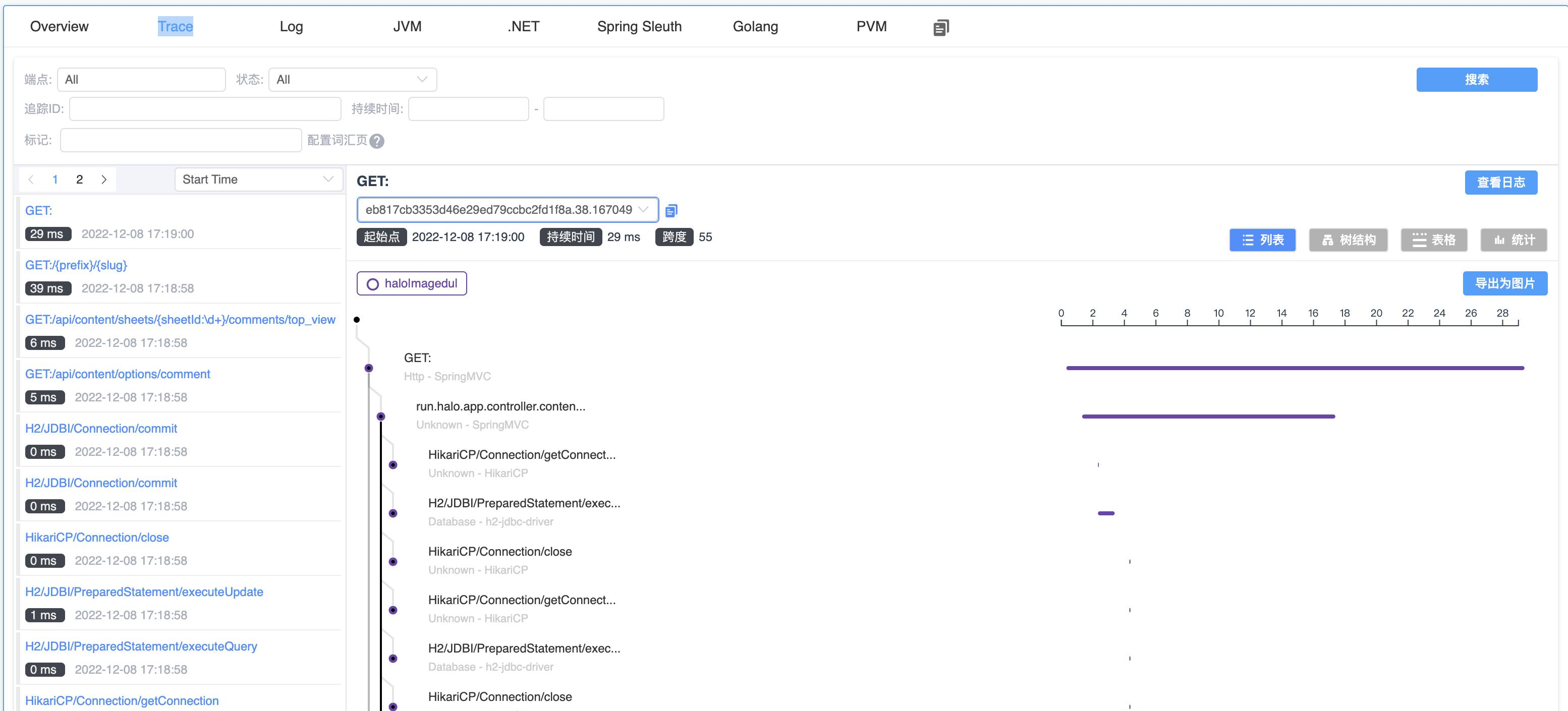
普通服务-->服务--> halo|magedu|-->Instance-->示例-->JVM(实例JVM信息):
JVM CPU (%):jvm占用CPU的百分比。
JVM Memory (MB):JVM内存占用大小,单位m,包括堆内存,与堆外内存(直接内存)。
JVM GC Time (ms):JVM垃圾回收时间,包含YGC和OGC。
JVM GC Count:JVM垃圾回收次数,包含YGC和OGC
JVM Thread Count:JVM线程计数统计
JVM Thread State Count:JVM线程状态计
JVM Class Count:JVM类计数
普通服务-->服务--> halo|magedu|-->Instance-->示例-->.NET(.NET信息):
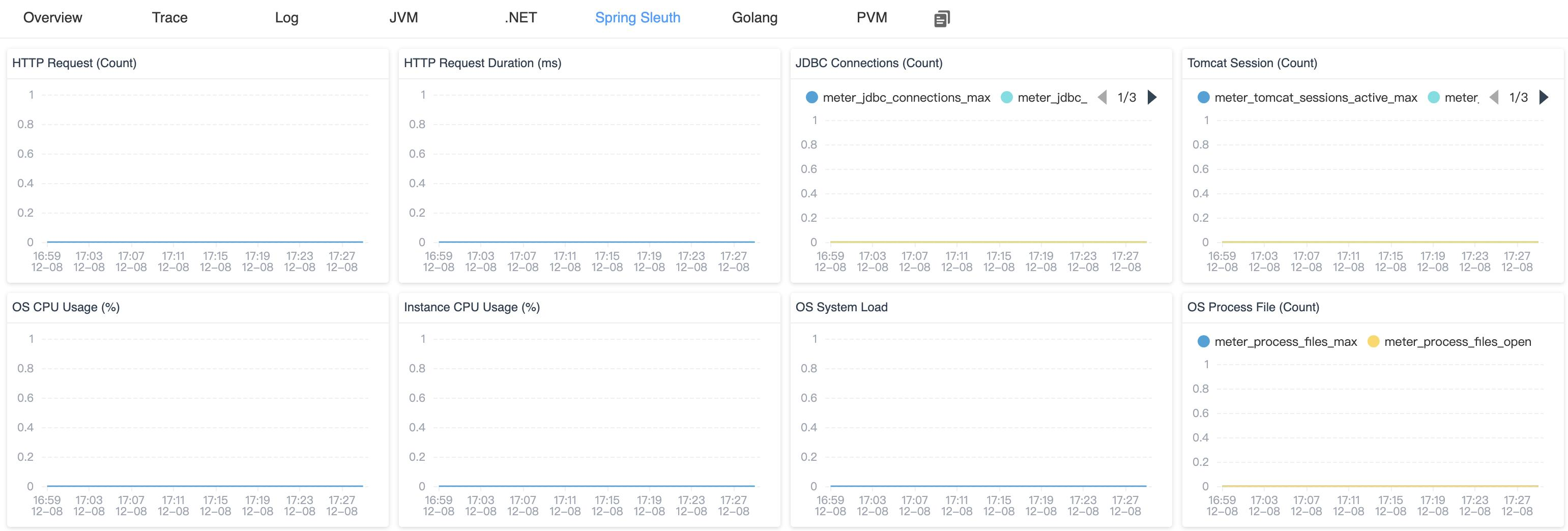
普通服务-->服务--> halo|magedu|-->Instance-->示例-->Spring Sleuth(Spring信息):
普通服务-->服务--> halo|magedu|-->Instance-->示例-->Golang(Golang信息):
普通服务-->服务--> halo|magedu|-->Instance-->示例-->PVM( Python Virtual Machine (PVM) metrics信息):
skywalking-java博客追踪案例
准备 skywalking-java-agent
root@skywalking-agent1:~# mkdir /data && cd /data
root@skywalking-agent1:/data# tar xvf apache-skywalking-java-agent-8.13.0.tgz
root@skywalking-agent1:/data# vim /data/skywalking-agent/config/agent.config
agent.service_name=${SW_AGENT_NAME:halo}
agent.namespace=${SW_AGENT_NAMESPACE:zxy}
collector.backend_service=${SW_AGENT_COLLECTOR_BACKEND_SERVICES:192.168.110.208:11800}
博客jar包 halo部署
需要java11
root@skywalking-agent:~# java -version
openjdk version "11.0.17" 2022-10-18
OpenJDK Runtime Environment (build 11.0.17+8-post-Ubuntu-1ubuntu222.04)
OpenJDK 64-Bit Server VM (build 11.0.17+8-post-Ubuntu-1ubuntu222.04, mixed mode, sharing)
下载halo博客jar包并启动
wget https://dl.halo.run/release/halo-1.6.1.jar
java -javaagent:./skywalking-agent.jar -jar /apps/halo-1.6.1.jar
halo创建一篇测试博客,之后可在skywalking中看到数据
tomcat运行jenkins实现链路跟踪案例:
部署jdk环境 需要jdk11 同halo
部署skywalking java客户端 同halo
skywalking-agent配置文件
agent.service_name=${SW_AGENT_NAME:zxy}
agent.namespace=${SW_AGENT_NAMESPACE:jenkins}
collector.backend_service=${SW_AGENT_COLLECTOR_BACKEND_SERVICES:172.31.2.161:11800}
部署tomcat
root@skywalking-agent1:/apps# wget https://archive.apache.org/dist/tomcat/tomcat-8/v8.5.84/bin/apache-tomcat-8.5.84.tar.gz
root@skywalking-agent1:/apps# tar xvf apache-tomcat-8.5.84.tar.gz
root@skywalking-agent1:/apps# vim /apps/apache-tomcat-8.5.84/bin/catalina.sh
# -----------------------------------------------------------------------------
CATALINA_OPTS="$CATALINA_OPTS -javaagent:/data/skywalking-agent/skywalking-agent.jar"; export CATALINA_OPTS
下载jenkins.war 放入webapps目录下
更改tomcat端口号为8088 启动tomcat
root@skywalking-agent1:/apps# /apps/apache-tomcat-8.5.84/bin/catalina.sh run
登录Jenkins
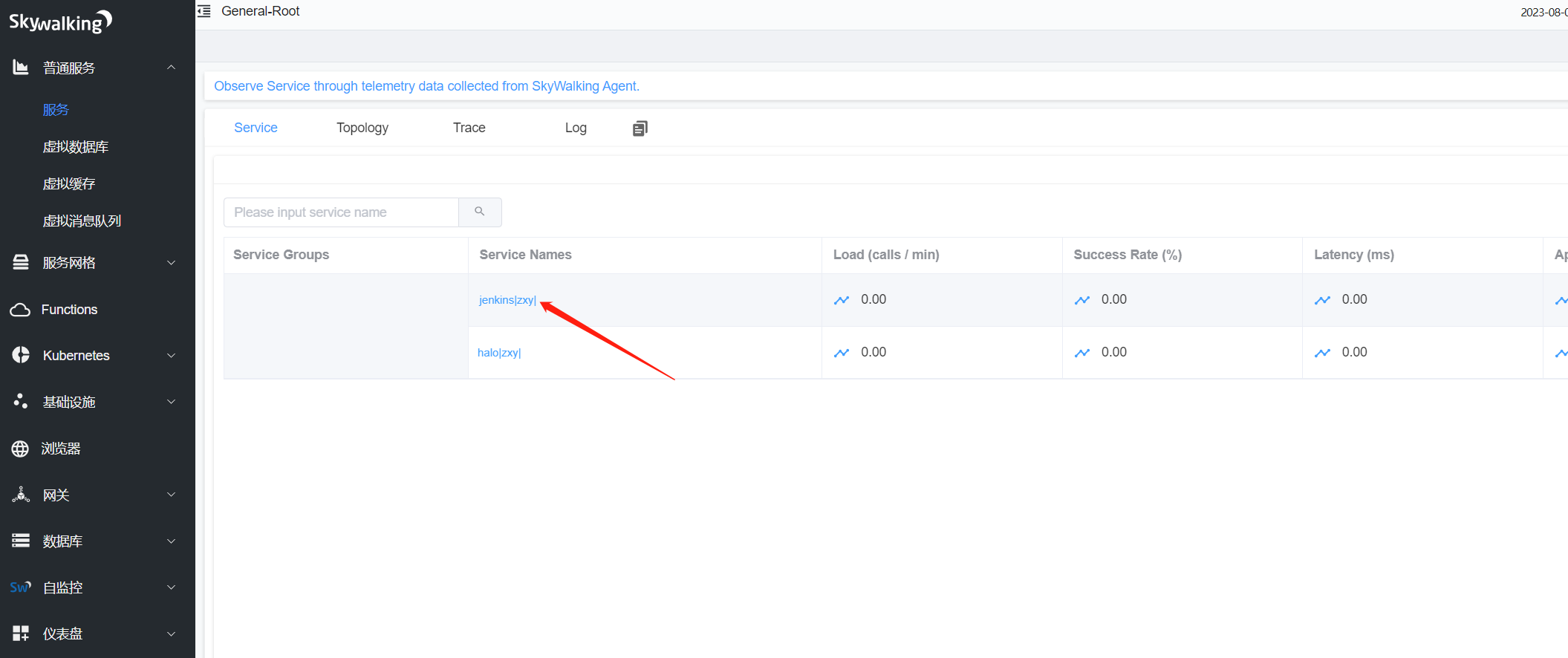
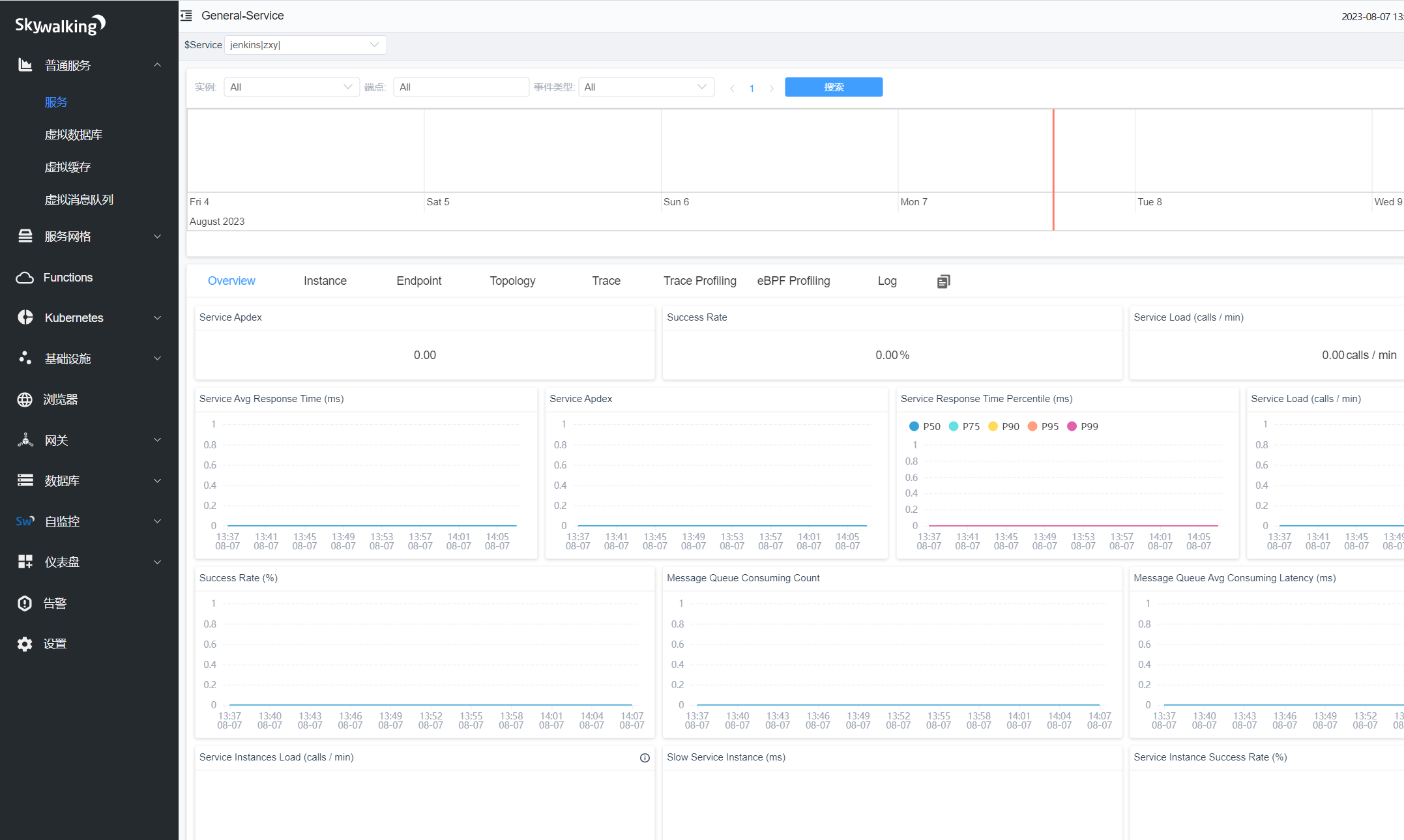
skywalking已经有数据
skywalking-dubbo微服务实现链路跟踪案例:
部署注册中心(192.168.110.208):
root@skywalking-zookeeper:~# apt install openjdk-8-jdk
root@skywalking-zookeeper:~# java -version
openjdk version "1.8.0_352"
OpenJDK Runtime Environment (build 1.8.0_352-8u352-ga-1~22.04-b08)
OpenJDK 64-Bit Server VM (build 25.352-b08, mixed mode)
root@skywalking-zookeeper:# cd /usr/local/src
root@skywalking-zookeeper:/usr/local/src# wget https://dlcdn.apache.org/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz
root@skywalking-zookeeper:/usr/local/src# tar xvf apache-zookeeper-3.7.1-bin.tar.gz
root@skywalking-zookeeper:/usr/local/src# cp /usr/local/src/apache-zookeeper-3.7.1-bin/conf/zoo_sample.cfg /usr/local/src/apache-zookeeper-3.7.1-bin/conf/zoo.cfg
root@skywalking-zookeeper:/usr/local/src# /usr/local/src/apache-zookeeper-3.7.1-bin/bin/zkServer.sh start
部署provider(192.168.110.209):
root@skywalking-node1:~# apt install openjdk-8-jdk -y
root@skywalking-node1:~# mkdir /data && cd /data
root@skywalking-node1:/data# tar xvf apache-skywalking-java-agent-8.13.0.tgz
root@skywalking-node1:/data# vim /data/skywalking-agent/config/agent.config
20 agent.service_name=${SW_AGENT_NAME:dubbo-server1}
23 agent.namespace=${SW_AGENT_NAMESPACE:myserver}
101 collector.backend_service=${SW_AGENT_COLLECTOR_BACKEND_SERVICES:192.168.110.208:11800}
添加主机名解析,dubbo里面的zookeeper地址写在了源代码中,域名变量为ZK_SERVER1:
root@skywalking-node1:~# vim /etc/profile
export ZK_SERVER1=172.31.2.163
root@skywalking-node1:~# source /etc/profile
root@skywalking-node1:~# echo $ZK_SERVER1
172.31.2.163
root@skywalking-node1:/data# mkdir -pv /apps/dubbo/provider
下载provider文件dubbo-server.jar
root@skywalking-node1:/data# java -javaagent:/data/skywalking-agent/skywalking-agent.jar -jar /apps/dubbo/provider/dubbo-server.jar


部署consumer(192.168.110.207):
root@skywalking-node3:~# apt install openjdk-8-jdk -y
root@skywalking-node3:~# mkdir /data && cd /data
root@skywalking-node3:/data# tar xvf apache-skywalking-java-agent-8.13.0.tgz
root@skywalking-node3:/data# vim /data/skywalking-agent/config/agent.config
20 agent.service_name=${SW_AGENT_NAME:dubbo-consumer1}
23 agent.namespace=${SW_AGENT_NAMESPACE:myserver}
collector.backend_service=${SW_AGENT_COLLECTOR_BACKEND_SERVICES:${SW_SERVER}:11800}
添加主机名解析,dubbo里面的zookeeper地址写在了源代码中,域名变量为ZK_SERVER1,SW也可以为agent设置环境变量:
root@skywalking-node3:~# vim /etc/profile
export SW_SERVER="192.168.110.208"
export ZK_SERVER1="192.168.110.208"
root@skywalking-node3:/data# source /etc/profile
root@skywalking-node3:/data# mkdir -pv /apps/dubbo/consumer
root@skywalking-node3:/data# java -javaagent:/data/skywalking-agent/skywalking-agent.jar -jar /apps/dubbo/consumer/dubbo-client.jar

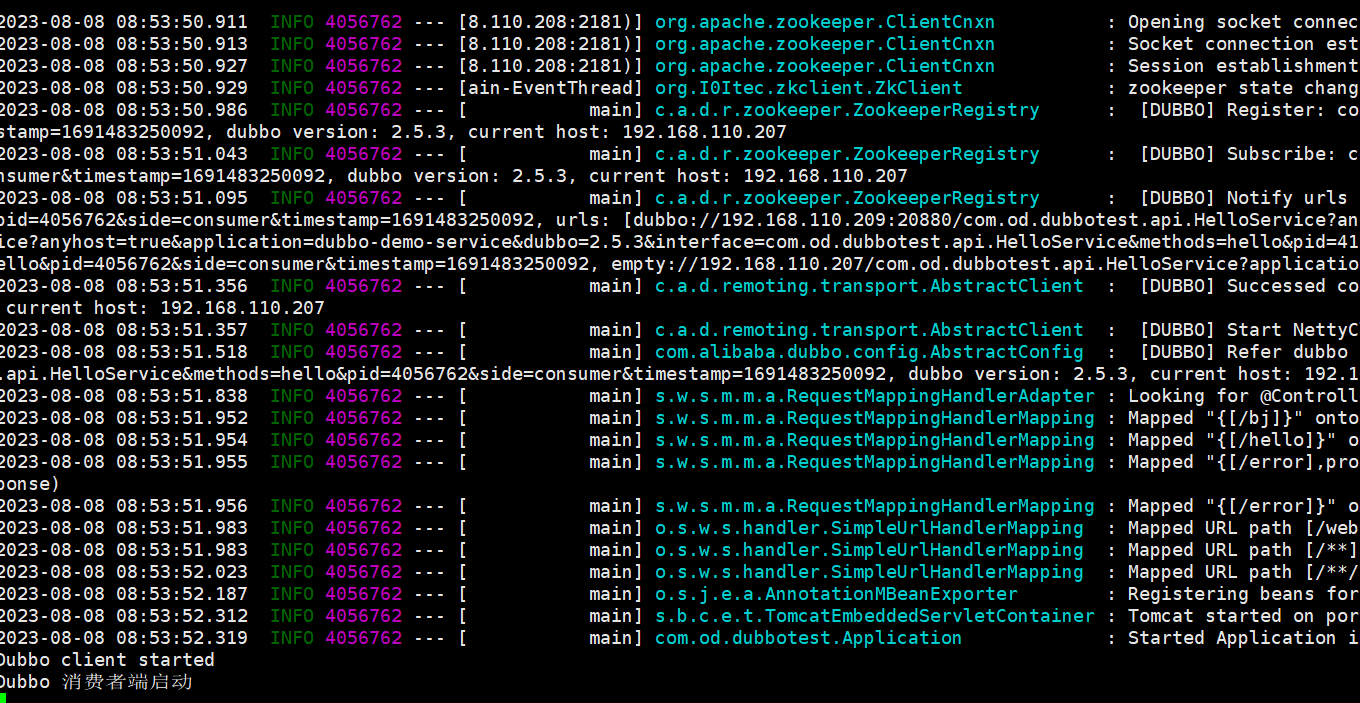
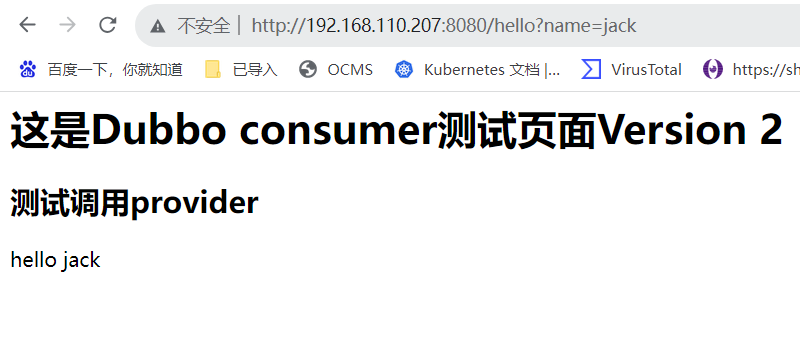
登录测试页面
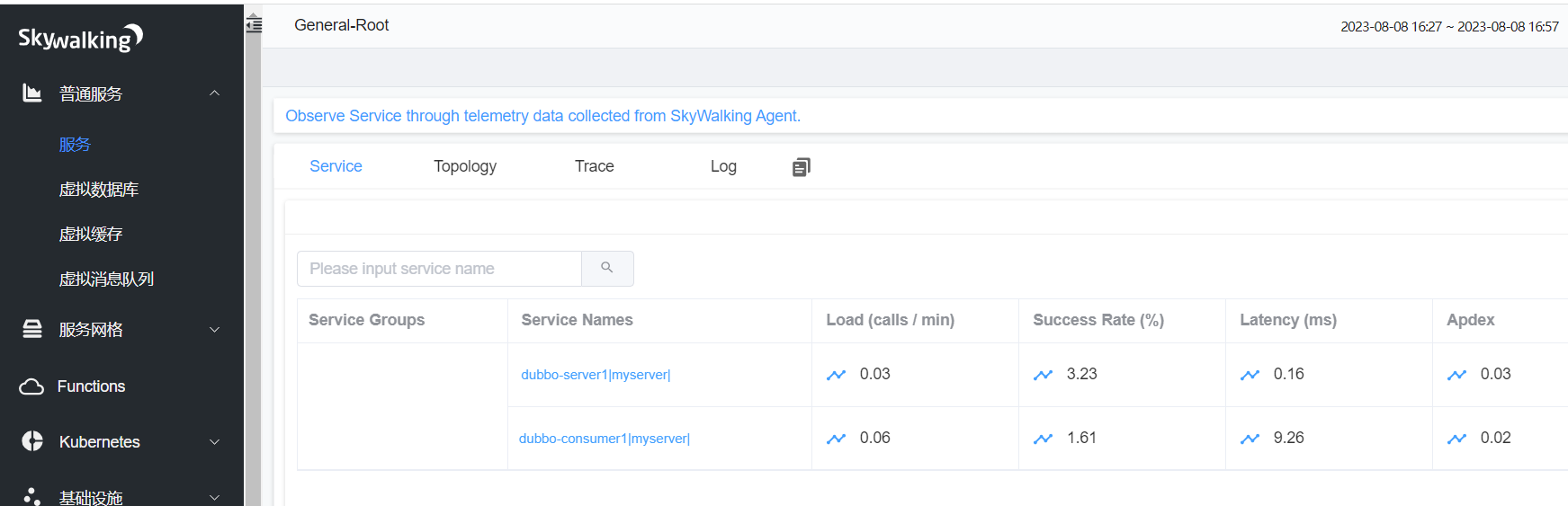
登录skywalking
部署dubboadmin(192.168.110.208-JDK8):
root@skywalking-zookeeper:/apps# java -version
openjdk version "1.8.0_352"
OpenJDK Runtime Environment (build 1.8.0_352-8u352-ga-1~22.04-b08)
OpenJDK 64-Bit Server VM (build 25.352-b08, mixed mode)
root@skywalking-zookeeper:/apps# tar xvf apache-tomcat-8.5.84.tar.gz
root@skywalking-zookeeper:/apps# cd /apps/apache-tomcat-8.5.84/webapps/
root@skywalking-zookeeper:/apps/apache-tomcat-8.5.84/webapps# rm -rf ./*
root@skywalking-zookeeper:/apps/apache-tomcat-8.5.84/webapps# unzip dubboadmin.war
root@skywalking-zookeeper:/apps/apache-tomcat-8.5.84/webapps# vim dubboadmin/WEB-INF/dubbo.properties
dubbo.registry.address=zookeeper://192.168.110.208:2181
dubbo.admin.root.password=root
dubbo.admin.guest.password=guest
登录dubboadmin 用户名密码 root/root
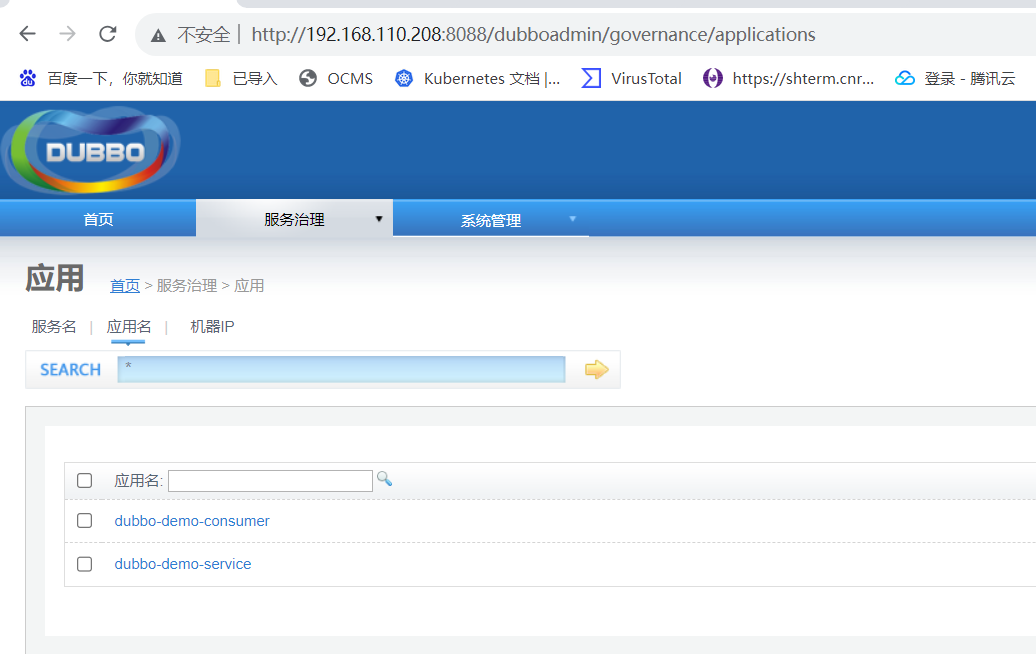
至此dubbo已经搭建完成 可以看到生产者和消费者
skywaling收集openresty请求链路
部署openresty
https://openresty.org/cn/linux-packages.html
配置skywalking nginx agent
https://github.com/apache/skywalking-nginx-lua
配置openresty conf文件
root@192:/usr/local/openresty/nginx/conf# pwd
/usr/local/openresty/nginx/conf
root@192:/usr/local/openresty/nginx/conf# cat conf.d/www.myserver.com.conf
lua_package_path "/data/skywalking-nginx-lua-master/lib/?.lua;;";
# Buffer represents the register inform and the queue of the finished segment
lua_shared_dict tracing_buffer 100m;
# Init is the timer setter and keeper
# Setup an infinite loop timer to do register and trace report.
init_worker_by_lua_block {
local metadata_buffer = ngx.shared.tracing_buffer
metadata_buffer:set('serviceName', 'myserver-nginx') ---#ÔÚskywalking ÏÔʾµÄµ±Ç°server Ãû³Æ£¬ÓÃÓÚÇø·ÖʼþÊÇÓÐÄĸö·þÎñ²úÉúµÄ
-- Instance means the number of Nginx deloyment, does not mean the worker instances
metadata_buffer:set('serviceInstanceName', 'myserver-nginx-node1') ---#µ±Ç°Ê¾ÀýÃû³Æ£¬Óû§Ê¼þÊÇÔÚÄÇ̨·þÎñÆ÷²úÉúµÄ
-- type 'boolean', mark the entrySpan include host/domain
metadata_buffer:set('includeHostInEntrySpan', false) ---#ÔÚspanÐÅÏ¢Öаüº¬Ö÷»úÐÅÏ¢
-- set randomseed
require("skywalking.util").set_randomseed()
require("skywalking.client"):startBackendTimer("http://192.168.110.208:12800")
-- Any time you want to stop reporting metrics, call `destroyBackendTimer`
-- require("skywalking.client"):destroyBackendTimer()
-- If there is a bug of this `tablepool` implementation, we can
-- disable it in this way
-- require("skywalking.util").disable_tablepool()
skywalking_tracer = require("skywalking.tracer")
}
server {
listen 80;
server_name www.myserver.com;
location / {
root html;
index index.html index.htm;
#ÊÖ¶¯ÅäÖõÄÒ»¸öÉÏÓηþÎñÃû³Æ»òDNSÃû³Æ£¬ÔÚskywalking»áÏÔʾ´ËÃû³Æ
rewrite_by_lua_block {
------------------------------------------------------
-- NOTICE, this should be changed manually
-- This variable represents the upstream logic address
-- Please set them as service logic name or DNS name
--
-- Currently, we can not have the upstream real network address
------------------------------------------------------
skywalking_tracer:start("www.myserver.com")
-- If you want correlation custom data to the downstream service
-- skywalking_tracer:start("upstream service", {custom = "custom_value"})
}
#ÓÃÓÚÐÞ¸ÄÏìÓ¦ÄÚÈÝ(×¢ÈëJS)
body_filter_by_lua_block {
if ngx.arg[2] then
skywalking_tracer:finish()
end
}
#¼Ç¼ÈÕÖ¾
log_by_lua_block {
skywalking_tracer:prepareForReport()
}
}
location /myserver {
default_type text/html;
rewrite_by_lua_block {
------------------------------------------------------
-- NOTICE, this should be changed manually
-- This variable represents the upstream logic address
-- Please set them as service logic name or DNS name
--
-- Currently, we can not have the upstream real network address
------------------------------------------------------
skywalking_tracer:start("www.myserver.com")
-- If you want correlation custom data to the downstream service
-- skywalking_tracer:start("upstream service", {custom = "custom_value"})
}
proxy_pass http://192.168.110.208:8088;
body_filter_by_lua_block {
if ngx.arg[2] then
skywalking_tracer:finish()
end
}
log_by_lua_block {
skywalking_tracer:prepareForReport()
}
}
location /hello {
default_type text/html;
rewrite_by_lua_block {
------------------------------------------------------
-- NOTICE, this should be changed manually
-- This variable represents the upstream logic address
-- Please set them as service logic name or DNS name
--
-- Currently, we can not have the upstream real network address
------------------------------------------------------
skywalking_tracer:start("www.myserver.com")
-- If you want correlation custom data to the downstream service
-- skywalking_tracer:start("upstream service", {custom = "custom_value"})
}
proxy_pass http://192.168.110.207:8070;
body_filter_by_lua_block {
if ngx.arg[2] then
skywalking_tracer:finish()
end
}
log_by_lua_block {
skywalking_tracer:prepareForReport()
}
}
}
查看nginx.conf文件
root@192:/usr/local/openresty/nginx/conf# cat nginx.conf |grep -v "#" |grep -v "^$"
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 80;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
include /usr/local/openresty/nginx/conf/conf.d/*.conf;
}
宿主机添加代理

测试openresty页面 查看域名是否生效


进入skywalking可以看到openresty数据已经被抓取



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?