

字符串
字符串总结
题目描述:
class Solution {
public:
string reverseStr(string s, int k) {
int len = s.length();
//string res;
if (len < k) {
reverse(s.begin(), s.end());
}
if (len >= k) {
int i;
for ( i = 0; i < len; i += (2*k)) {
if ((len - i) >= 2*k) {
reverse(s.begin() + i, s.begin() + i + k);
}
if ((len - i) < k) {
reverse(s.begin() + i, s.end());
}
if ((len - i) >= k && ((len - i) < 2*k)) {
reverse(s.begin() + i, s.begin() + i + k);
}
}
cout << i << endl;
}
return s;
}
};
reverse函数实现方式写一下
替换空格
题目描述:
库函数
class Solution {
public:
string replaceSpace(string s) {
string replace_str = "%20";
int i = 0;
while ((i = s.find(" ")) != -1) {
s.erase(i,1);
s.insert(i,replace_str);
}
return s;
}
};
新的数组接收
class Solution {
public:
string replaceSpace(string s) {
string replace_str = "%20";
string new_str;
int space_num = 0;
for (int i = 0; i < s.length(); i++) {
if (s[i] == ' ') {
new_str += "%20";
}
else {
new_str += s[i];
}
}
return new_str;
}
};
不需要新的空间的方法
class Solution {
public:
string replaceSpace(string s) {
int space_num = 0;
int left = s.length() - 1;
for (int i = 0; i < s.length(); i++) {
if (s[i] == ' ') {
space_num++;
}
}
s.resize(s.length() + space_num * 2);
for (int right = s.length() - 1; left >= 0; left--, right--) {
if (s[left] == ' ') {
s[right--] = '0';
s[right--] = '2';
s[right] = '%';
}
else {
s[right] = s[left];
}
}
cout << space_num << endl;
for (int i = 0; i < s.length(); i++) {
cout << s[i];
}
return s;
}
};
反转字符里面的单词
题目描述:
class Solution {
public:
string reverseWords(string s) {
remove_space(s);
//cout<<s<<endl;
reverse(s, 0, s.size() - 1);
int j = 0;
int i;
for (i = 0; i <= s.size(); i++) {
if (i == s.size() || s[i] == ' ') {
reverse(s, j, i-1);
j = i + 1;
}
}
//cout << i << j << endl;
return s;
}
void reverse(string& s,int start, int end) {
for (int i = start, j = end; i < j; i++, j--) {
swap(s[i], s[j]);
}
//return s;
}
/* void remove_space(string &s) {
for (int i = 0; i < s.size(); i++) {
if (s[i] == s[i + 1] && s[i] == ' ') {
s.erase(s.begin() + i);
}
}//正来
for (int i = s.size() - 1; i > 0; i--) {
if (s[i] == s[i - 1] && s[i] == ' ') {
s.erase(s.begin() + i);
}
}
//倒来
if (s.size() > 0 && s[0] == ' ') {
s.erase(s.begin());
}
if (s.size() > 0 && s[s.size() - 1] == ' ') {
s.erase(s.begin() + s.size() - 1);
}
} */
void remove_space(string &s) {
int slow = 0;
for (int i = 0; i < s.size(); i++) {
if (s[i] != ' ') {
if (slow != 0 ) {
s[slow++] = ' ';
}
while (i < s.size() && s[i] != ' ') {
s[slow++] = s[i++];
}
}
}
s.resize(slow);
}//快慢指针法简版
};
找出字符串中第一个匹配的下标
题目描述:
主要看KMP算法的实现,具体看这篇文章KMP总结
class Solution {
public:
void getNext(vector<int> &next, string needle) {
int j = 0;
next[0] = j;
for (int i = 1; i < needle.size(); i++) {
while (j > 0 && needle[j] != needle[i]) {
j = next[j - 1];
}
if (needle[j] == needle[i]) {
j++;
}
next[i] = j;//继承已经匹配的模式串字串
}
}
int strStr(string haystack, string needle) {
vector<int> next(needle.size());
getNext(next, needle);
int i ;//指向字符串
int j = 0;//指向模式串
for (i = 0; i < haystack.size(); i++) {
while (j > 0 && haystack[i] != needle[j]) {
j = next[j - 1];
}
if (haystack[i] == needle[j]) {
j++;
}
if (j == needle.size() ) {
return (i - needle.size() + 1);
}
//cout << i << " "<< j << endl;
}
return -1;
}
};
代码的主要实现过程:

重复的子字符串
题目描述:
这题的解法有两种:
我先介绍KMP算法:我在解决这个问题的时候,曾踩过一个坑,我想用KMP算法中的next数组发现规律解决这个问题,天真的以为next数组为0的就是其组成整个字符串的子字符串,其实不然。如下图①,这种只要组成的子字符串中有重复的字母,那判断结果一定不成立。
我们可以看看几个一定的字符串,看其next的数组有什么规律可言:
1:"abaccg/abaccg/abaccg" true
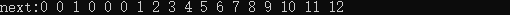
2:"dhjshjdhi/dhjshjdhi/dhjshjdhi" true
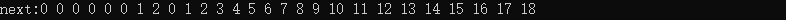
3:"dfadasjkdklsajojfhas" false
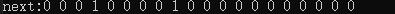
4:"dhjshjdhidhjshjdhiis" false

我想从中发现规律,比如next序列递增?其实也是不对的,我们可以将关注点放在true字符串的末尾和false字符串的末尾。我这是片面的思考方式,系统的证明是这样的:next数组中存储的是各个位置为终点字符串的最长相同前后缀的长度。如果 next[len - 1] != 0(或-1),则说明字符串有最长相同的前后缀(就是字符串里的前缀子串和后缀子串相同的最长长度)。
- 最长相同前后缀和重复子串的关系有什么关系呢?
正是因为最长相等前后缀的规则,当一个字符串由重复子串组成的,最长相等前后缀不包含的子串就是最小重复子串。
证明如下图②

数学推导:
假设字符串s使用多个重复子串构成(这个子串是最小重复单位),重复出现的子字符串长度是x,所以s是由n * x组成。
因为字符串s的最长相同前后缀的长度一定是不包含s本身,所以 最长相同前后缀长度必然是m * x,而且 n - m = 1,(这里如果不懂,看上面的推理)
所以如果 nx % (n - m)x = 0,就可以判定有重复出现的子字符串。
而nx=len,x=len-mx。即最小字串长度。
具体代码如下:
class Solution {
public:
void getNext(vector<int> &next, string needle) {
int j = 0;
next[0] = j;
for (int i = 1; i < needle.size(); i++) {
while (j > 0 && needle[j] != needle[i]) {
j = next[j - 1];
}
if (needle[j] == needle[i]) {
j++;
}
next[i] = j;//继承已经匹配的模式串字串
}
}
bool repeatedSubstringPattern(string s) {
vector<int> next(s.size());
getNext(next, s);
int len = s.size();
cout << next[len - 1];
if (next[len - 1] != 0 && len % (len - (next[len - 1])) == 0) return true;
return false;
}
};
第二种是移动匹配算法:
具体可看代码随想录移动匹配解释,代码如下:
class Solution {
public:
bool repeatedSubstringPattern(string s) {
string sumstr = s + s;
sumstr.erase(sumstr.begin());
sumstr.erase(sumstr.end() -1);
if (sumstr.find(s) != std::string::npos) return true;
return false;
}
};
- 小知识点:字符串和数组的区别
字符串是若干字符组成的有限序列,也可以理解为是一个字符数组,但是很多语言对字符串做了特殊的规定,C/C++中的字符串用string类储存的时候,string类会提供size接口,不需要像C语言一样运用'\0'去判断,另外string中提供的size()函数与length()函数功能一样,只不过为了照顾c的使用习惯。
那么vector< char > 和 string 的区别
在基本操作上没有区别,但是string提供更多的字符串处理的相关接口,例如string 重载了+,而vector却没有,string用起来方便一些。
参考:代码随想录
