
存储系统设计——NVMe SSD性能影响因素一探究竟
目录
1 存储介质的变革
2 NVME SSD成为主流
2.1 NAND FLASH介质发展
2.2 软件层面看SSD——多队列技术
2.3 深入理解SSD硬件
3 影响NVME SSD的性能因素
3.1 GC对性能的影响
3.2 IO PATTERN对性能的影响
3.2.1 顺序写入Pattern对SSD性能优化的奥秘
3.2.2 读写冲突Pattern对性能的影响
4 SSD写性能分析模型
5 小结
NVMe SSD的性能时常捉摸不定,为此我们需要打开SSD的神秘盒子,从各个视角分析SSD性能影响因素,并思考从存储软件的角度如何最优化使用NVMe SSD,推进数据中心闪存化进程。本文从NVMe SSD的性能影响因素进行分析,并给出存储系统设计方面的一些思考。
1 存储介质的变革
近几年存储行业发生了翻天覆地的变化,半导体存储登上了历史的舞台。和传统磁盘存储介质相比,半导体存储介质具有天然的优势。无论在可靠性、性能、功耗等方面都远远超越传统磁盘。目前常用的半导体存储介质是NVMe SSD,采用PCIe接口方式与主机进行交互,大大提升了性能,释放了存储介质本身的性能。通常NVMe SSD内部采用NAND Flash存储介质进行数据存储,该介质本身具有读写不对称性,使用寿命等问题。为此在SSD内部通过FTL(Flash Translation Layer)解决NAND Flash存在的问题,为上层应用软件呈现和普通磁盘相同的应用接口和使用方式。

![]()
如上图所示,随着半导体存储介质的发展,计算机系统的IO性能得到了飞速发展。基于磁介质进行数据存储的磁盘和处理器CPU之间一直存在着棘手的剪刀差性能鸿沟。随着存储介质的演进与革新,这种性能剪刀差将不复存在。从整个系统的角度来看,IO性能瓶颈正从后端磁盘往处理器和网络方向转移。如下图性能数据所示,在4KB访问粒度下,NVMe SSD和15K转速磁盘相比,每秒随机读IO处理能力提升了将近5000倍;每秒随机写IO处理能力提升了1000多倍。随着非易失性存储介质的进一步发展,半导体存储介质的性能将进一步提升,并且会具有更好的IO QoS能力。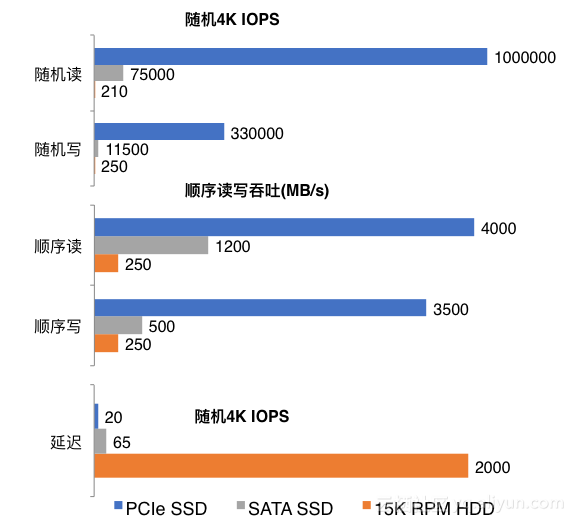
![]()
存储介质的革命一方面给存储系统性能提升带来了福音;另一方面对存储系统的设计带来了诸多挑战。原有面向磁盘设计的存储系统不再适用于新型存储介质,面向新型存储介质需要重新设计更加合理的存储软件堆栈,发挥存储介质的性能,并且可以规避新介质带来的新问题。面向新型存储介质重构存储软件栈、重构存储系统是最近几年存储领域的热门技术话题。
在面向NVMe SSD进行存储系统设计时,首先需要对NVMe SSD本身的特性要非常熟悉,需要了解SSD性能的影响因素。在设计过程中需要针对SSD的特性通过软件的方式进行优化。本文对SSD进行简要介绍,并从性能影响因素角度出发,对NVMe SSD进行深入剖析,在此基础上给出闪存存储设计方面的一些思考。
2 NVMe SSD成为主流
2.1 NAND Flash介质发展
目前NVMe SSD主流采用的存储介质是NAND Flash。最近几年NAND Flash技术快速发展,主要发展的思路有两条:第一,通过3D堆叠的方式增加NAND Flash的存储密度;第二,通过增加单Cell比特数来提升NAND Flash的存储密度。3D NAND Flash已经成为SSD标配,目前主流发布的SSD都会采用3D NAND Flash技术工艺。从cell的角度来看,目前单个cell可以表示3bit,这就是通常所说的TLC NAND Flash。今年单个cell的bit存储密度又提升了33%,可以表示4bit,向前演进至QLC NAND Flash。NAND Flash的不断演进,推动了SSD存储密度不断提升。截止到今天,单个3.5寸SSD盘可以做到128TB的容量,远远超过了磁盘的容量。下图是近几年NAND Flash技术的发展、演进过程。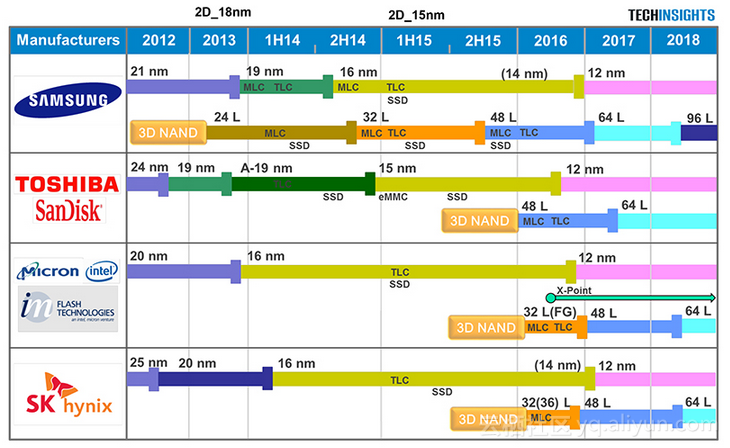
![]()
从上图可以看出,NAND Flash在不断演进的过程中,一些新的非易失性内存技术也开始发展。Intel已经推出了AEP内存存储介质,可以预计,未来将会是非易失性内存和闪存共存的半导体存储时代。
2.2 软件层面看SSD——多队列技术
从软件接口的角度来看,NVMe SSD和普通的磁盘没有太多的区别,在Linux环境下都是标准块设备。由于NVMe SSD采用了最新的NVMe协议标准,因此从软件堆栈的角度来看,NVMe SSD的软件栈简化了很多。在NVMe标准中,和传统的SATA/SAS相比,一个重大的差别是引入了多队列机制,如下图所示。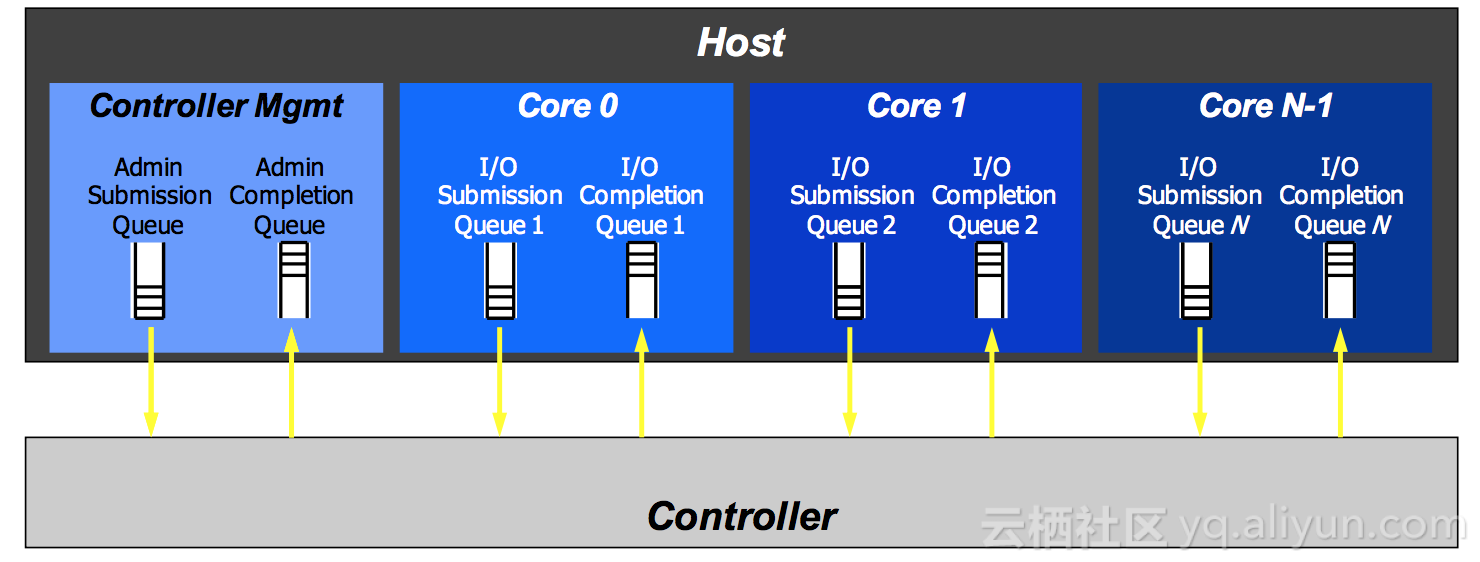
![]()
何为多队列技术?主机(X86 Server)与SSD进行数据交互的模型采用“生产者-消费者”模型,采用生产者-消费者队列进行数据交互。在原有的AHCI规范中,只定义了一个交互队列,那么主机与HDD之间的数据交互只能通过一个队列通信,多核处理器也只能通过一个队列与HDD进行数据交互。在磁盘存储时代,由于磁盘是慢速设备,所以一个队列也就够用了。多个处理器核通过一个共享队列与磁盘进行数据交互,虽然处理器之间会存在资源竞争,但是相比磁盘的性能,处理器之间竞争所引入的开销实在是微乎其微,可以忽略。在磁盘存储时代,单队列有其他的好处,一个队列存在一个IO调度器,可以很好的保证提交请求的IO顺序最优化。
和磁盘相比,半导体存储介质具有很高的性能,AHCI原有的规范不再适用,原有的假设也已经不复存在,在此背景下NVMe规范诞生了。NVMe规范替代了原有的AHCI规范,并且软件层面的处理命令也进行了重新定义,不再采用SCSI/ATA命令规范集。在NVMe时代,外设和处理器之间的距离更近了,不再需要像SAS一样的面向连接的存储通信网络。相比于以前的AHCI、SAS等协议规范,NVMe规范是一种非常简化,面向新型存储介质的协议规范。该规范的推出,将存储外设一下子拉到了处理器局部总线上,性能大为提升。并且主机和SSD处理器之间采用多队列的设计,适应了多核的发展趋势,每个处理器核与SSD之间可以采用独立的硬件Queue Pair进行数据交互。
从软件的角度来看,每个CPU Core都可以创建一对Queue Pair和SSD进行数据交互。Queue Pair由Submission Queue与Completion Queue构成,通过Submission queue发送数据;通过Completion queue接受完成事件。SSD硬件和主机驱动软件控制queue的Head与Tail指针完成双方的数据交互。
2.3 深入理解SSD硬件
和磁盘相比,NVMe SSD最大的变化在于存储介质发生了变化。目前NVMe SSD普遍采用3D NAND Flash作为存储介质。NAND Flash内部有多个存储阵列单元构成,采用floating gate或者charge trap的方式存储电荷,通过存储电荷的多少来保持数据存储状态。由于电容效应的存在、磨损老化、操作电压干扰等问题的影响,NAND Flash天生会存在漏电问题(电荷泄漏),从而导致存储数据发生变化。因此,从本质上讲,NAND Flash是一种不可靠介质,非常容易出现Bit翻转问题。SSD通过控制器和固件程序将这种不可靠的NAND Flash变成了可靠的数据存储介质。
为了在这种不可靠介质上构建可靠存储,SSD内部做了大量工作。在硬件层面,需要通过ECC单元解决经常出现的比特翻转问题。每次数据存储的时候,硬件单元需要为存储的数据计算ECC校验码;在数据读取的时候,硬件单元会根据校验码恢复被破坏的bit数据。ECC硬件单元集成在SSD控制器内部,代表了SSD控制器的能力。在MLC存储时代,BCH编解码技术可以解决问题,4KB数据中存在100bit翻转时可以纠正错误;在TLC存储时代,bit错误率大为提升,需要采用更高纠错能力的LDPC编解码技术,在4KB出现550bit翻转时,LDPC硬解码仍然可以恢复数据。下图对比了LDPC硬解码、BCH以及LDPC软解码之间的能力, 从对比结果可以看出,LDPC软解码具有更强的纠错能力,通常使用在硬解码失效的情况下。LDPC软解码的不足之处在于增加了IO的延迟。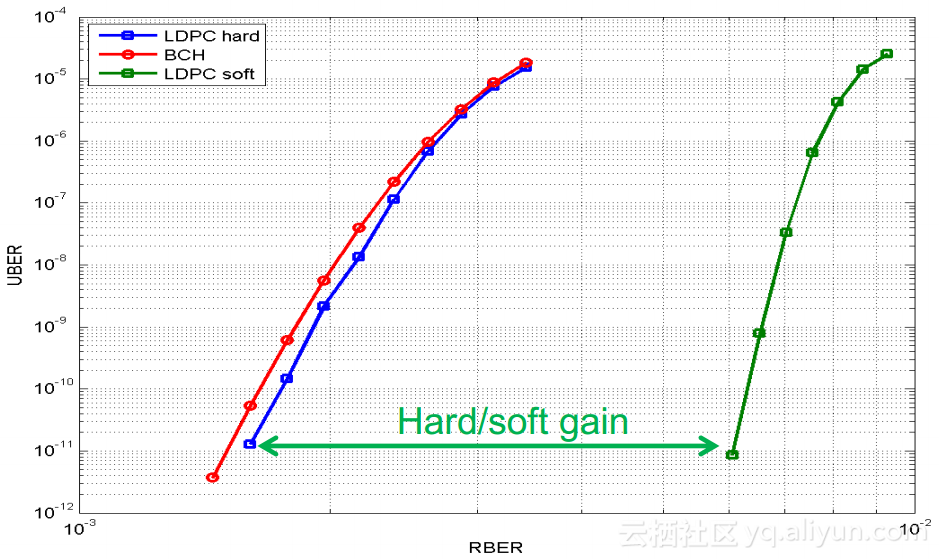
![]()
在软件层面,SSD内部设计了FTL(Flash Translation Layer),该软件层的设计思想和log-structured file system设计思想类似。采用log追加写的方式记录数据,采用LBA至PBA的地址映射表记录数据组织方式。Log-structured系统最大的一个问题就是垃圾回收(GC)。因此,虽然NAND Flash本身具有很高的IO性能,但受限于GC的影响,SSD层面的性能会大受影响,并且存在十分严重的IO QoS问题,这也是目前标准NVMe SSD一个很重要的问题。SSD内部通过FTL解决了NAND Flash不能inplace write的问题;采用wear leveling算法解决了NAND Flash磨损均衡问题;通过data retention算法解决了NAND Flash长时间存放漏电问题;通过data migration方式解决read diatribe问题。FTL是NAND Flash得以大规模使用的核心技术,是SSD的重要组成部分。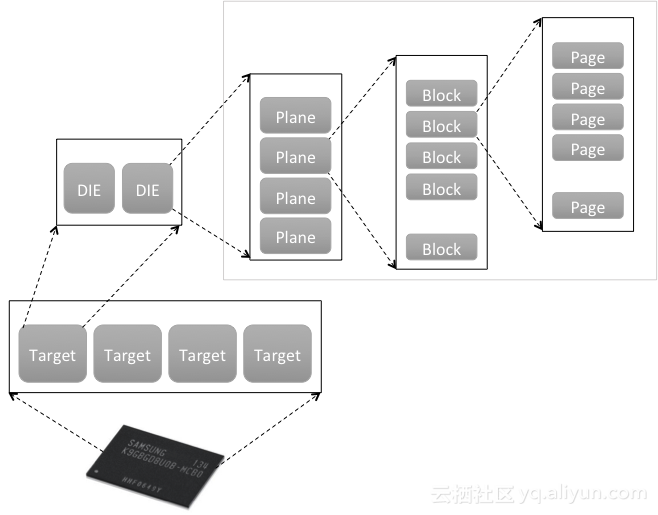
![]()
NAND Flash内部本身具有很多并发单元,如上图所示,一个NAND Flash芯片由多个Target构成,每个Target包含多个Die。每个Die是一个独立的存储单元,一个Die由多个Plane构成,多个Plane之间共享一套操作总线,多个Plane可以组成一个单元并发操作,构建Multi-plane。一个Plane由若干个Block构成,每个Block是一个擦除单元,该单元的大小也决定了SSD软件层面的GC回收粒度。每个Block由多个page页构成,每个Page是最小写入(编程)单元,通常大小为16KB。SSD内部软件(固件)需要充分利用这些并发单元,构建高性能的存储盘。
一块普通NVMe SSD的物理硬件结构简单,由大量的NAND Flash构成,这些NAND Flash通过SOC(SSD控制器)进行控制,FTL软件运行在SOC内部,并通过多队列的PCIe总线与主机进行对接。为了提升性能,企业级SSD需要板载DRAM,DRAM资源一方面可以用来缓存数据,提升写性能;另一方面用来缓存FTL映射表。企业级SSD为了提升性能,通常采用Flat mapping的方式,需要占据较多的内存(0.1%)。内存容量的问题也限制了大容量NVMe SSD的发展,为了解决内存问题,目前一种可行的方法是增大sector size。标准NVMe SSD的sector size为4KB,为了进一步增大NVMe SSD的容量,有些厂商已经开始采用16KB的sector size。16KB Sector size的普及应用,会加速大容量NVMe SSD的推广。
3 影响NVMe SSD的性能因素
NVMe SSD 厂商Spec给出的性能非常完美,前面也给出了NVMe SSD和磁盘之间的性能对比,NVMe SSD的性能的确比磁盘高很多。但在实际应用过程中,NVMe SSD的性能可能没有想象中的那么好,并且看上去不是特别的稳定,找不到完美的规律。和磁盘介质相比,SSD的性能和很多因素相关,分析SSD的性能影响因素,首先需要大体了解SSD构成的主要部分。如下图所示,其主要包括主机CPU、PCIe互连带宽、SSD控制器及FTL软件、后端NAND Flash带宽、NAND Flash介质。影响SSD性能的主要因素可以分成硬件、软件和客观环境三大部分,具体分析如下。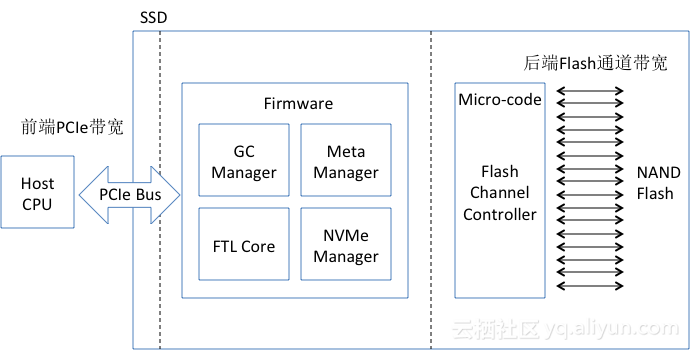
![]()
1, 硬件因素
a) NAND Flash本身。不同类型的NAND Flash本身具有不同的性能,例如SLC的性能高于MLC,MLC的性能优于TLC。选择不同的工艺、不同类别的NAND Flash,都会具有不同的性能。
b) 后端通道数(CE数量)及总线频率。后端通道数决定了并发NAND Flash的数量,决定了并发能力。不同的SSD控制器支持不同数量的通道数,也决定了SSD的后端吞吐带宽能力。NAND Flash Channel的总线频率也决定了访问Flash的性能。
c) SSD控制器的处理能力。SSD控制器中会运行复杂的FTL(Flash Translation Layer)处理逻辑,将逻辑块读写映射转换成NAND Flash 读写请求。在大数据块读写时,对处理器能力要求不是很高;在小数据块读写时,对处理器能力要求极高,处理器能力很容易成为整个IO系统的性能瓶颈点。
d) SSD控制器架构。通常SSD控制器采用SMP或者MPP两种架构,早期的控制器通常采用MPP架构,多个小处理器通过内部高速总线进行互连,通过硬件消息队列进行通信。内存资源作为独立的外设供所有的处理器进行共享。这种架构和基于消息通信的分布式系统类似。MPP架构的很大优势在于性能,但是编程复杂度较高;SMP架构的性能可扩展性取决于软件,编程简单,和在x86平台上编程相似。不同的控制器架构会影响到SSD的总体性能,在SSD设计时,会根据设计目标,选择不同类型的SSD控制器。
e) 内存支持容量。为了追求高性能,SSD内部的映射资源表会常驻内存,映射表的内存占用大小是盘容量的0.1%,当内存容量不够大时,会出现映射表换入换出的问题,影响到性能。
f) PCIe的吞吐带宽能力。PCIe前端带宽体现了SSD的前端吞吐能力,目前NVMe SSD采用x4 lane的接入方式,上限带宽为3GB/s,当后端NAND Flash带宽和处理器能力足够时,前端PCIe往往会成为性能瓶颈点。NAND Flash具有很高的读性能,目前来看,SSD的读性能在很大程度上受限于PCIe总线,因此需要快速推进PCIe4.0标准。
g) 温度对性能造成影响。在NAND Flash全速运行的情况下,会产生较大的散热功耗,当温度高到一定程度时,系统将会处于不正常的工作状态,为此,SSD内部做了控温系统,通过温度检测系统来调整SSD性能,从而保证系统温度维持在阈值之内。调整温度会牺牲性能,本质上就是通过降低SSD性能来降温。因此,当环境温度过高时,会影响到SSD的性能,触发SSD内部的温度控制系统,调节SSD的性能。
h) 使用寿命对性能造成影响。NAND Flash在不断擦除使用时,Flash的bit error会不断上升,错误率的提升会影响到SSD的IO性能。
2, 软件因素
a) 数据布局方式。数据布局方法需要充分考虑NAND Flash中的并发单元,如何将IO操作转换成NAND Flash的并发操作,这是数据布局需要考虑的问题。例如,采用数据交错的方式在多通道page上进行数据布局,通过这种方式可以优化顺序带宽。
b) 垃圾回收/wear leveling调度方法。数据回收、wear leveling、data retention等操作会产生大量的NAND Flash后端流量,后端流量直接反应了SSD的写放大系数,也直接体现在后端带宽的占用。垃圾回收等产生的流量也可以称之为背景流量,背景流量会直接影响到前端用户性能。因此需要对背景流量和用户流量之间进行合理调度,使得用户IO性能达到最佳。
c) OP预留。为了解决坏块、垃圾回收等问题,在SSD内部预留了一部分空闲资源,这些资源被称之为OP(Overprovisioning)。OP越大,GC过程中平均搬移的数据会越少,背景流量会越小,因此,写放大降低,用户IO性能提升。反之,OP越小,性能会越低,写放大会越大。在SSD容量较小的时代,为了提升SSD的使用寿命,往往OP都设置的比较大。
d) Bit error处理影响性能。在SSD内部采用多种机制来处理NAND Flash所产生的Bit error。ECC纠错、read retry、soft LDPC以及RAIN都是用来纠正bit翻转导致的错误。当Bit错误率增加时,软件处理的开销越大,在bit控制在一定范围之内,完全可以通过硬件进行纠正。一旦软件参与到bit纠正的时候,会引入较大的性能开销。
e) FTL算法。FTL算法会影响到SSD性能,对于不同用途的SSD,FTL的设计与实现是完全不同的,企业级SSD为了追求高性能,通常采用Flat mapping的方式,采用大内存缓存映射表;消费级SSD为了追求低成本,通常采用元数据换入换出的方式,并且采用pSLC+TLC的组合方式进行分层存储,也可以采用主机端内存缓存元数据信息,但是这些方式都会影响到性能。
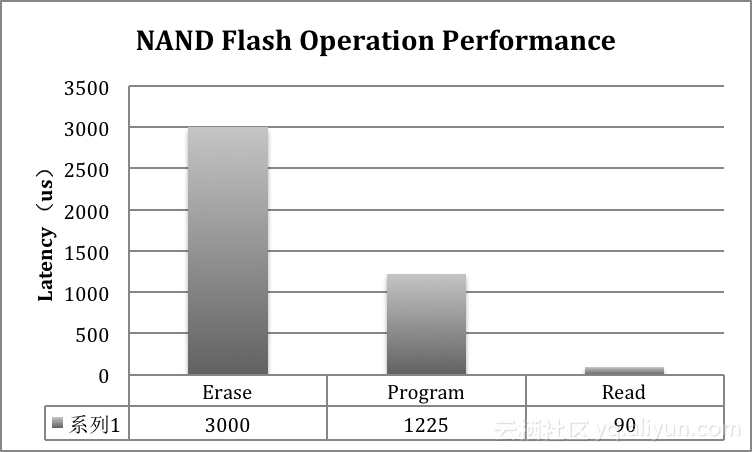
f) IO调度算法。NAND Flash具有严重的性能不对称性,Flash Erase和Program具有ms级延迟,Flash read的延迟在us级。因此,如何调度Erase、Program以及read是SSD后端设计需要考虑的问题。另外,前端IO以及背景IO之间的调度也是需要权衡考虑,通过IO调度可以达到最佳性能表现。在IO调度过程中,还需要利用NAND Flash的特性,例如Program Suspension,通过这些特性的利用,最优化SSD前端IO性能。
g) 驱动软件。驱动软件运行在主机端,通常分为内核态和用户态两大类,内核态驱动会消耗较多的CPU资源,存在频繁上下文切换、中断处理,因此性能较低;用户态驱动通常采用Polling IO处理模式,去除了上下文切换,可以充分提升CPU效率,提升整体IO性能。
h) IO Pattern对性能产生影响。IO Pattern影响了SSD内部的GC数据布局,间接影响了GC过程中的数据搬移量,决定了后端流量。当IO Pattern为全顺序时,这种Pattern对SSD内部GC是最为友好的,写放大接近于1,因此具有最好的性能;当IO Pattern为小块随机时,会产生较多的GC搬移数据量,因此性能大为下降。在实际应用中,需要通过本地文件系统最优化IO Pattern,获取最佳性能。
3, 客观因素
a) 使用时间越长会导致SSD性能变差。使用时间变长之后,SSD内部NAND Flash的磨损会加重,NAND Flash磨损变大之后会导致bit错误率提升。在SSD内部存在一套完整的bit错误恢复机制,由硬件和软件两大部分构成。当bit错误率达到一定程度之后,硬件机制将会失效。硬件机制失效之后,需要通过软件(Firmware)的方式恢复翻转的bit,软件恢复将会带来较大的延迟开销,因此会影响到SSD对外表现的性能。在有些情况下,如果一块SSD在掉电情况下放置一段时间之后,也可能会导致性能变差,原因在于SSD内部NAND Flash中存储电荷的漏电,放置一段时间之后导致bit错误率增加,从而影响性能。SSD的性能和时间相关,本质上还是与NAND Flash的比特错误率相关。
b) 环境温度也会对性能造成影响。为了控制SSD温度不能超过上限值,在SSD内部设计有一套温度负反馈机制,该机制通过检测的温度对NAND Flash后端带宽进行控制,达到降低温度的效果。如果一旦温度负反馈机制开始工作,那么NAND Flash后端带宽将会受到限制,从而影响前端应用IO的性能。
下面从软件的角度出发,重点阐述GC以及IO Pattern对SSD性能的影响。
3.1 GC对性能的影响
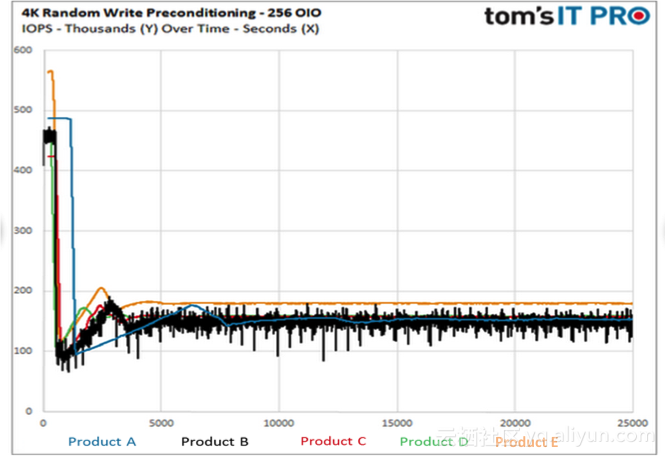
SSD内部有一个非常厚重的软件层,该软件层用来解决NAND Flash的问题,采用log-structured的方式记录数据。Log-structured方式引入了GC的问题,对于前端业务来讲,GC流量就是背景噪声。GC流量不是时时刻刻存在的,因此,SSD对外体现性能大幅度波动。当SSD为空盘时,性能会非常好,为最佳性能;当SSD被用过一段时间之后,性能会大幅降低。其中GC起到了很重要的作用。企业级SSD在发布Spec的时候,都会发布SSD盘的稳态性能。在性能测试的时候,需要对盘进行老化预处理。通常预处理的方法是顺序写满盘,然后再随机两遍写盘,预处理完成之后,再对盘进行随机读写测试,得到Spec中定义的值。稳态值基本可以认为是盘的下限性能。
![]()
上图所示是多个厂商的盘在空盘和稳态情况下的性能对比,由此可见稳态情况和空盘情况下的性能差距很大。在稳态情况下,SSD内部的GC会全速运行,会占用较多的NAND Flash后端带宽。背景流量和前端数据流的比例也就体现了SSD盘的写放大系数,写放大系数越大,背景流量占用带宽越多,SSD对外体现的前端性能也就越差。写放大系数很多因素相关,例如OP、应用IO Pattern等。如果应用IO Pattern比较好,那么可以降低写放大系数,背景噪声流就会减少,前端业务的性能会提升。例如,在SSD完全顺序写入的情况下,写放大系数可以接近于1,此时GC产生的数据流很少,背景流量基本没有,后端带宽基本被业务数据流占用,因此对外体现的性能会很好。
GC是影响性能的重要因素,除了影响性能之外,GC会增大写放大,对SSD的使用寿命产生影响。从软件层面的角度考虑,可以通过优化应用IO Pattern的方式优化SSD内部GC,从而进一步提升SSD的性能,优化使用寿命。对于下一代更为廉价的QLC SSD介质,就需要采用这种优化思路,否则无法很好的满足实际业务的应用需求。
3.2 IO Pattern对性能的影响
IO Pattern会对SSD的性能产生严重影响,主要表现在如下几个方面:
1, 不同的IO Pattern会产生不同的写放大系数,不同的写放大系数占用后端NAND Flash带宽不同。当前端应用对SSD采用完全顺序的方式进行写入时,此时是最佳的IO Pattern,对于SSD而言写放大系数接近1,SSD内部的背景流量基本可以忽略,前端性能达到最佳。在实际应用中,很难采用这种完全顺序的数据写模型,但可以通过优化逼近顺序写入。
2, 不同请求大小的IO之间会产生干扰;读写请求之间会产生干扰。小请求会受到大请求的干扰,从而导致小请求的延迟增加,这个比较容易理解,在HDD上同样会存在这种情况。由于NAND Flash介质存在严重的读写不对称性,因此读写请求之间也会互相干扰,尤其是写请求对读请求产生严重的性能影响。
3.2.1 顺序写入Pattern对SSD性能优化的奥秘
在针对闪存系统的设计中,需要考虑IO Pattern对性能产生的影响,通过软件的优化来最优化SSD的使用。在实际应用中完全顺序写入的IO Pattern基本上是不存在的,除非用作顺序写入的日志设备。对于顺序写入优化性能这个结论,需要从SSD内部实现来深入理解,知道根源之后,可以采用合理的方式来逼近顺序写入的模式,从而最优化SSD的性能。
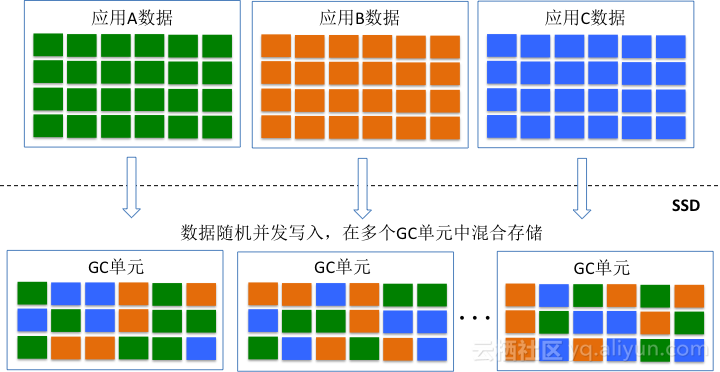
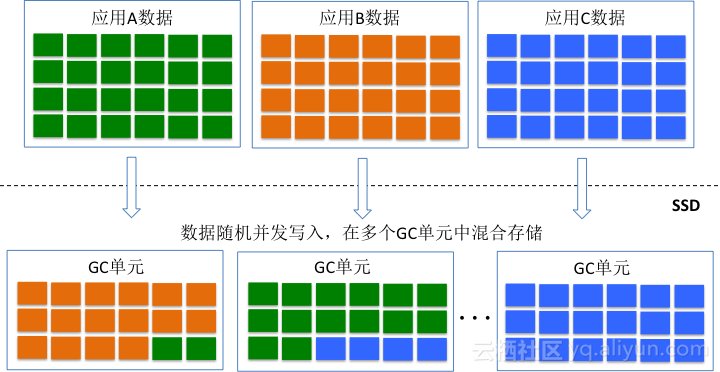
SSD内部采用log-structured的数据记录模式,并发写入的IO数据按照时间顺序汇聚成大数据块,合并形成的大数据块以Page stripe的方式写入NAND Flash。多个Page stripe会被写入同一个GC单元(Chunk or Superblock),当一个GC单元被写完成之后,该GC单元进入sealed模式(只读),分配新的GC单元写新的数据。在这种模式下,如果多个业务的数据流并发随机的往SSD中写入数据,那么多个应用的数据就会交错在一起被存储到同一个GC单元中。如下图所示,不同应用的数据生命周期不同,当需要回收一个GC单元的时候,会存在大量数据的迁移,这些迁移的数据就会形成写放大,影响性能和使用寿命。
![]()
不同应用的数据交错存储在同一个GC单元,本质上就是不同冷热程度的数据交错存储的问题。从GC的角度来讲,相同冷热程度的数据存储在同一个GC单元上是最佳的,为此三星推出了Multi-stream SSD,该SSD就允许不同应用的数据存储到不同的Stream单元(GC单元),从而提升GC效率,降低写放大。Multi-stream是一种显式的设计方式,需要更改SSD接口以及应用程序。从IO Pattern的角度考虑,可以通过顺序大块的方式也可以逼近类似的效果。假设操作SSD只存在一个线程,不同的应用都采用大数据块的方式写入数据,那么在一个时间片段内只存在一个应用的数据往SSD中写入数据,那么在一个GC单元内存储的数据会变得有序和规则。如下图所示,采用上述方法之后,一个GC单元内存储的数据将会变得冷热均匀。在GC过程中会大大减少数据的搬移,从而减少背景流量。
![]()
在实际应用中,上述IO Pattern很难产生,主要是应用很难产生非常大粒度的请求。为此在存储系统设计过程中,可以引入Optane高性能存储介质作为SSD的写缓存。前端不同业务的写请求首先写到Optane持久化介质中,在Optane持久化介质中聚合形成大数据块。一旦聚合形成大数据块之后,再写入SSD,通过这种方式可以最大程度的逼近SSD顺序写入过程,提升SSD的性能和使用寿命。
3.2.2 读写冲突Pattern对性能的影响
如下图所示,NAND Flash介质具有很强的读写不对称性。Block Erase和Page Program的延迟会远远高于Page Read所耗费的时间。那么在这种情况下,如果read请求在同一个Flash Channel上和Erase、Program操作冲突,那么read操作将会被Erase/program操作影响。这是在读写混合情况下,读性能会受到影响的重要因素。
![]()
在实际应用过程中,经常会发现应用的测试结果和SSD Spec对不上,会比Spec给出的值要来的低。Spec给出的值通常为纯读或者纯写情况下的性能指标,在读写混合的场景下,性能表现和Spec给出的值就会存在非常大的出入。
对于不同的SSD,通过测试可以发现在读写混合情况下的性能表现差距会比较大。在SSD处于稳态条件下,应用随机读的情况下,如果引入一个压力不是很大的顺序写,那么会发现不同SSD的抗干扰能力是不同的。有些SSD在写干扰的情况下,读性能会急剧下降,延迟快速上升,QoS性能得不到保证。下图是两个SSD在相同情况下的测试结果,从结果来看,有些SSD的抗写干扰能力比较强,读性能不会急剧下降。
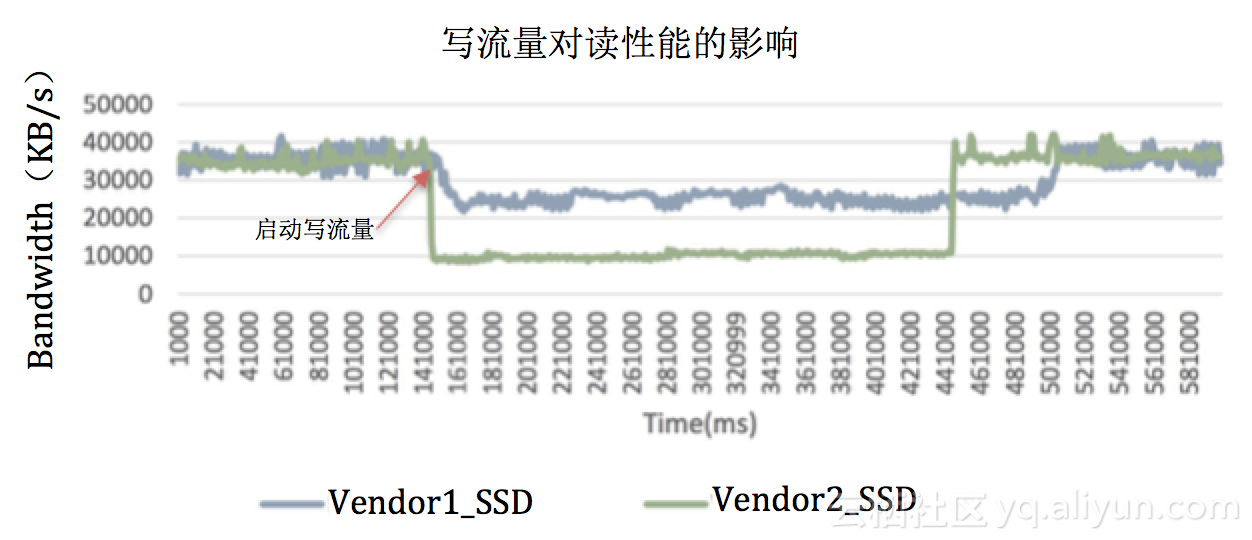
![]()
为什么有些SSD会具备比较强的抗写干扰能力呢?其中的奥秘就在于SSD内部的IO调度器。IO调度器会对write、read 和Erase请求进行调度处理,该调度器算法的不同就会表现出不同的抗干扰能力。目前很多NAND Flash可以支持Program/Erase Suspension的功能,在IO调度处理的过程中,为了提升读性能,降低读请求延迟,可以采用Suspension命令对Program/Erase命令暂停,对read请求优先调度处理。
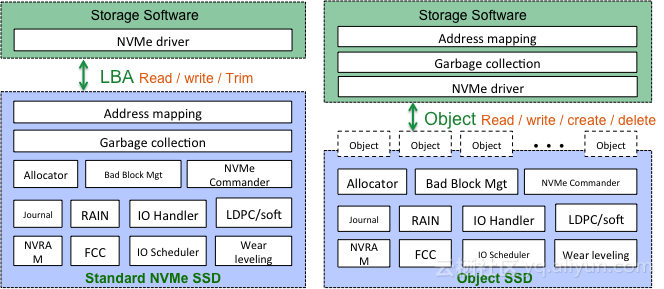
读写冲突是SSD内部影响IO QoS的重要因素。在SSD内部通过IO调度器的优化可以提升SSD性能的QoS能力,但是还是无法与存储软件结合来协同优化QoS。为了达到最佳的SSD性能QoS,需要关注Openchannel技术。Openchannel其实只是一种软硬件层次划分的方法,通常来讲,SSD内部的逻辑可以划分为面向NAND资源的物理资源管理层以及面向数据布局的资源映射层。物理资源管理由于和NAND Flash密切相关,因此可以放到SSD内部。传统的NVMe SSD需要对外暴露标准的块设备接口,因此需要在SSD内部实现资源映射层。从端至端的角度来看,资源映射层可以与存储软件层结合起来,为此将资源映射层从SSD内部剥离出来,集成至存储软件层。一旦资源映射层从SSD内部剥离之后,需要定义一个新的SSD接口,其中的一种接口方式就是Openchannel。
盘古分布式存储针对SSD QoS问题进行了大量研究,提出了Object SSD的概念,Object SSD也是一种新的SSD接口方式,其采用对象方式对SSD进行读写删操作,每个对象采用Append write操作方式。这种接口方式可以很好的与分布式存储无缝结合。采用Object SSD之后,SSD内部的大量工作被简化,IO的调度会更加灵活,存储软件与SSD协同配合,达到IO性能的最优化,以及QoS的最大化。
![]()
4 SSD写性能分析模型
SSD内部的数据流分成两大类,一类为前端用户数据流;另一类为内部背景数据流。前端用户数据流和背景数据流会汇聚成NAND Flash后端流量。当背景数据流不存在时,NAND Flash带宽会被用户数据流全部占据,此时SSD对外表现的性能达到最佳。当SSD具有较大写放大时,会产生很大的背景数据流,背景流会抢占NAND Flash带宽,导致前端用户IO性能降低。为了稳定前端IO性能,在SSD内部的调度器会均衡前端和背景流量,保证前端性能的一致性。背景流量的占比反应了SSD的写放大系数,因此,站在NAND Flash带宽占用的角度可以分析SSD在稳态情况下的性能。
在此,假设写放大系数为WA,顺序写情况下的总带宽数为B,用户写入流量(随机写入流量)为U。那么,由于GC写放大造成的背景流量为:(WA - 1)* U
写放大流量为一读一写,都会占用带宽,因此,总带宽可以描述为:
2 (WA - 1) U + U = B
因此,可以得到:
U = B / (2(WA - 1) + 1) = B / (2 WA - 1)
上述公式表述了前端用户流量和NAND Flash总带宽、写放大系数之间的关系。
根据Spec,Intel P4500的顺序写带宽为1.9GB/s,按照上述公式,在随机访问模式下的带宽为: 1900 / (2 * 4 - 1) = 270MB/s,IOPS为67K,根据该公式推导的结果和Spec给出的结果相同。
下图是Intel P4500和Samsung PM963随机写延迟和推导公式之间的对比。结果非常吻合。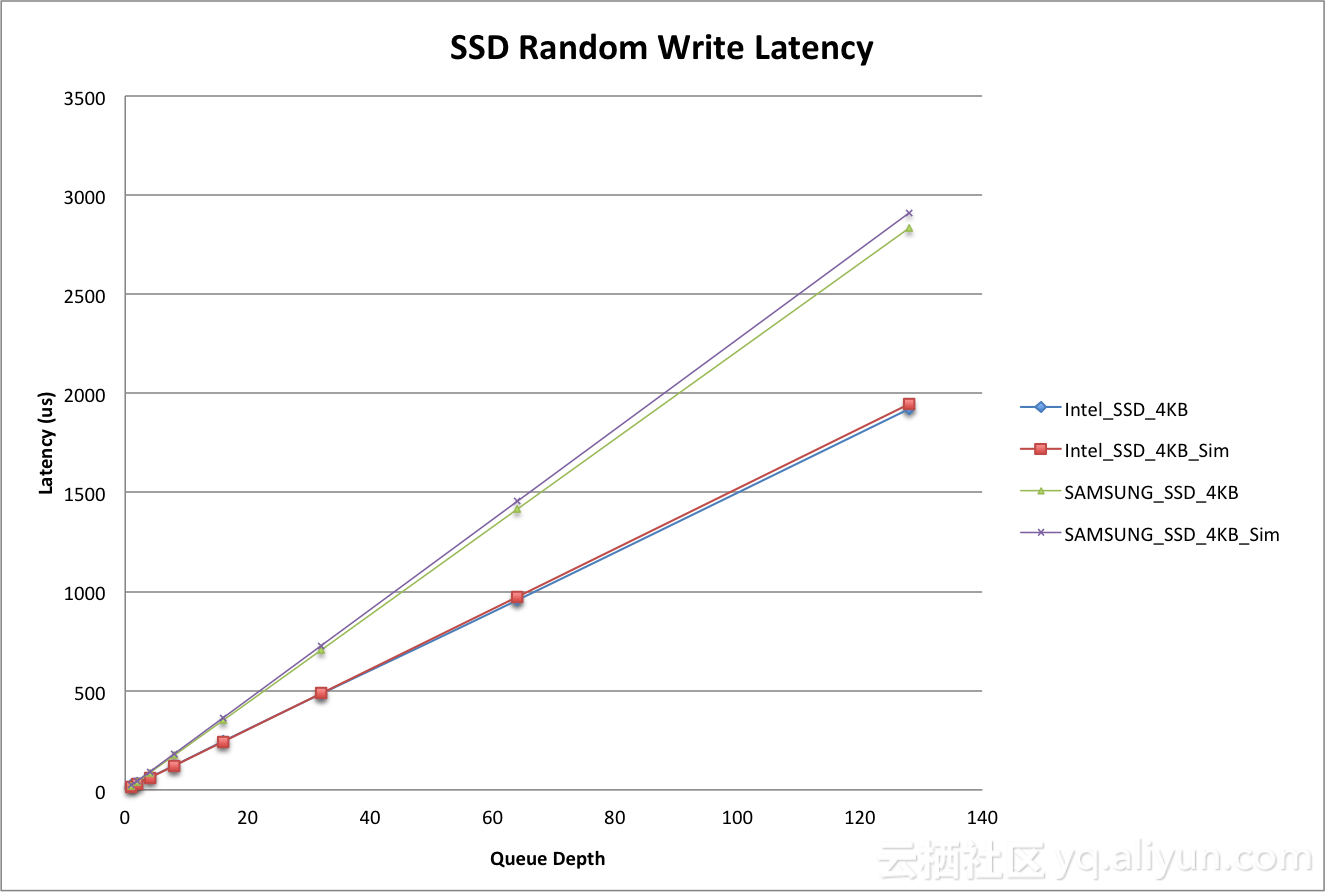
![]()
由此可以推出,随机写性能由SSD内部后端带宽以及写放大系数来决定。因此,从存储软件的角度出发,我们可以通过优化IO Pattern的方式减小写放大系数,从而可以提升SSD的随机写性能。
5 小结
闪存存储技术正在飞速发展,闪存介质、SSD控制器、存储系统软件、存储硬件平台都在围绕闪存日新月异的发展。闪存给数据存储带来的价值显而易见,数据中心闪存化是重要发展趋势。NVMe SSD性能受到很多因素的影响,在软件层面可以通过IO Pattern优化SSD的性能,使得整体存储系统的性能达到最佳。
阿里云双十一1折拼团活动:已满6人,都是最低折扣了
【满6人】1核2G云服务器99.5元一年298.5元三年 2核4G云服务器545元一年 1227元三年
【满6人】1核1G MySQL数据库 119.5元一年
【满6人】3000条国内短信包 60元每6月
参团地址:http://click.aliyun.com/m/1000020293/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号