
大数据上云第一课:(1)MaxCompute授权和外表操作躲坑指南
一、子账号创建、AK信息绑定
如果您是第一次使用子账号登录数加平台和使用DataWorks,需要确认以下信息:
- 该子账号所属主账号的企业别名。
- 该子账号的用户名和密码。
- 该子账号的AccessKey ID和AccessKey Secret。
- 确认主账号已经允许子账号启用控制台登录。
- 确认主账号已经允许子账号自主管理AccessKey。
1、子账号创建
(1)创建子账号
(2)绑定AK信息
(3)DataWorks给定角色
(1)使用阿里云账号(主账号)登录RAM控制台。
(2)在左侧导航栏的人员管理菜单下,单击用户。
(3)单击新建用户。
(4)输入登录名称和显示名称。
(5)在访问方式区域下,选择控制台密码登录。
(6)单击确认。

2、创建RAM子账号的访问密钥
访问密钥对开发人员在DataWorks中创建的任务顺利运行非常重要,该密钥区别于登录时填写的账号和密码,主要用于在阿里云各产品间互相认证使用权限。因此主账号需要为子账号创建AccessKey。创建成功后,请尽可能保证AccessKey ID和AccessKey Secret的安全,切勿让他人知晓,一旦有泄漏的风险,请及时禁用和更新。运行密钥AK包括AccessKey ID和AccessKey Secret两部分。如果云账号允许RAM用户自主管理AccessKey,RAM用户也可以自行创建AccessKey。
为子账号创建AccessKey的操作如下所示。
(1)在左侧导航栏的人员管理菜单下,单击用户。
(2)在用户登录名称/显示名称列表下,单击目标RAM用户名称。
(3)在用户AccessKey 区域下,单击创建新的AccessKey。
(4)单击确认。

3、给RAM子账号授权
如果您需要让子账号能够创建DataWorks工作空间,需要给子账号授予AliyunDataWorksFullAccess权限。
(1)在左侧导航栏的人员管理菜单下,单击用户。
(2)在用户登录名称/显示名称列表下,找到目标RAM用户。
(3)单击添加权限,被授权主体会自动填入。
(4)在左侧权限策略名称列表下,单击需要授予RAM用户的权限策略。
(5)单击确定。
(6)单击完成。

二、子账号生产环境创建函数、访问资源授权,OSS外部表授权
1、账号生产环境创建函数、访问资源授权
子账号登录DataWorks控制台之后,单击工作空间管理,成员管理给该子账号一个相应的角色。各角色对应的权限可以在工作空间管理界面的权限列表查看。此处添加的成员角色对生产环境是隔离的。下面介绍一下生产环境创建函数、访问资源授权。
(1)创建一个新的角色,给角色授权。

(2)创建UDF函数。

前提条件是已经上传1818.jar包。资源上传结合搬站第一课视频。
2、OSS访问授权
MaxCompute需要直接访问OSS的数据,前提是需要您将OSS的数据相关权限赋给MaxCompute的访问账号。如果没有进行相应授权创,创建外部表会发现报错如下:
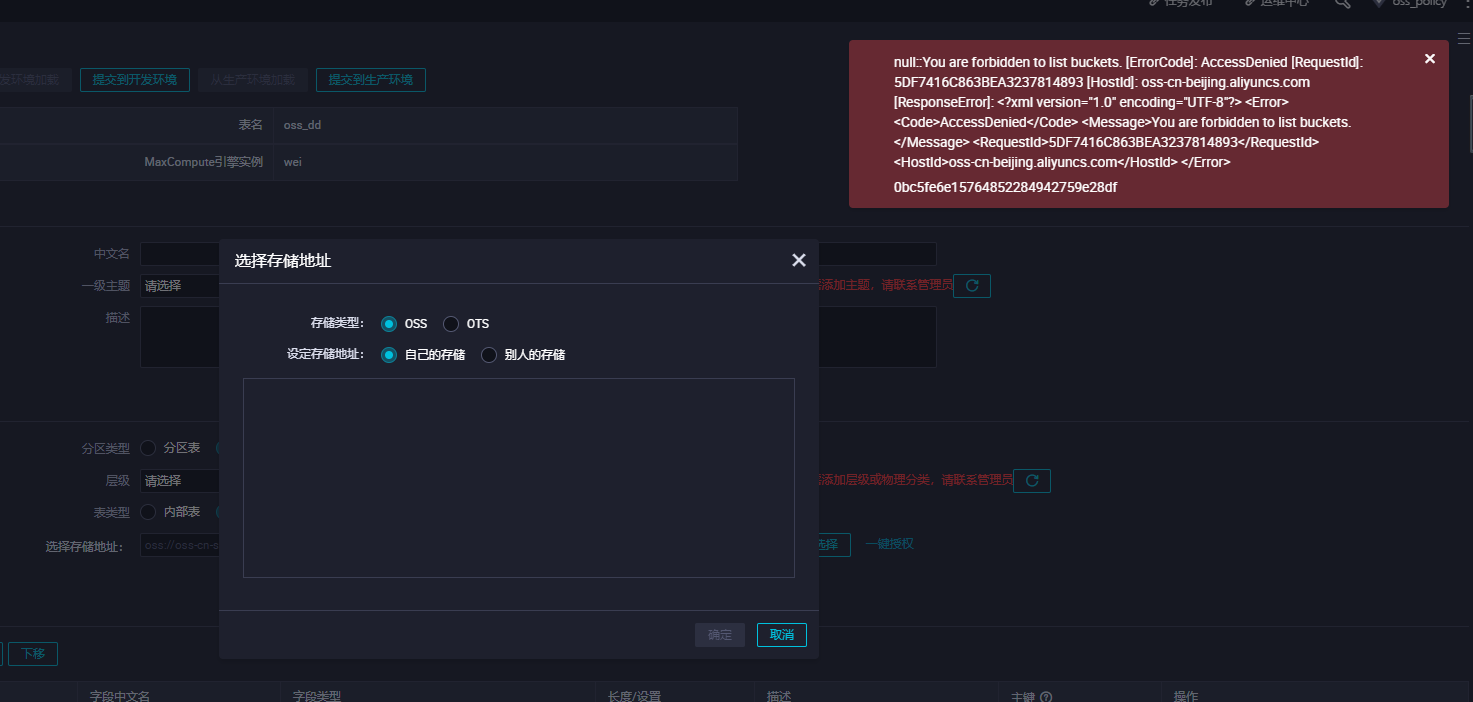
此时需要我们授权去访问OSS
授权方式有两种:
(1)当MaxCompute和OSS的Owner是同一个账号时,可以直接登录阿里云账号后,单击此处完成一键授权。一键授权,我们可以在访问控制给改子账号添加管理对象存储服务(OSS)权限(AliyunOSSFullAccess)。
(2)自定义授权
a.新增一个RAM角色oss-admin
b.修改角色策略内容设置

c.授予角色访问OSS必要的权限AliyunODPSRolePolicy

d.将权限AliyunODPSRolePolicy授权给该角色。
三、OSS外部表创建指引
1、外部表创建的语法格式介绍
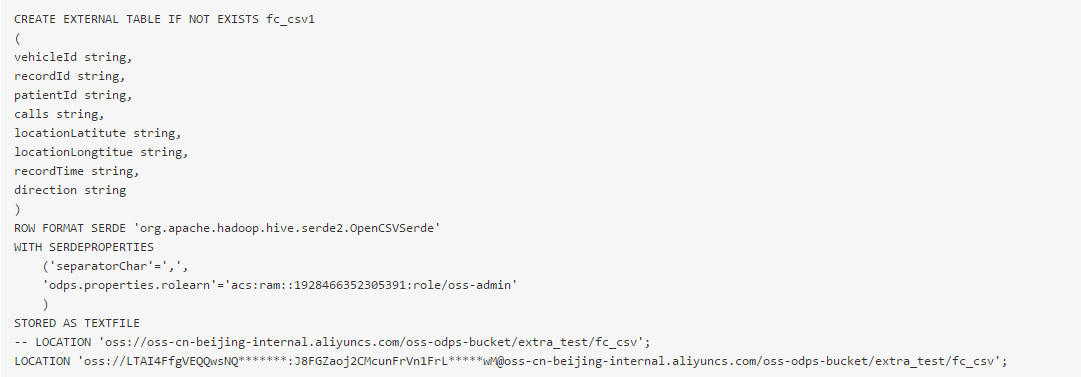
(1)外部表创建示例:
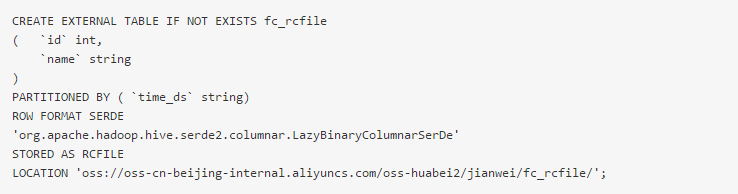
(2)LOCATION说明
LOCATION必须指定一个OSS目录,默认系统会读取这个目录下所有的文件。
建议您使用OSS提供的内网域名,否则将产生OSS流量费用。
访问OSS外部表,目前不支持使用外网Endpoint。
目前STORE AS单个文件大小不能超过3G,如果文件过大,建议split拆分。
建议您OSS数据存放的区域对应您开通MaxCompute的区域。由于MaxCompute只有在部分区域部署,我们不承诺跨区域的数据连通性。

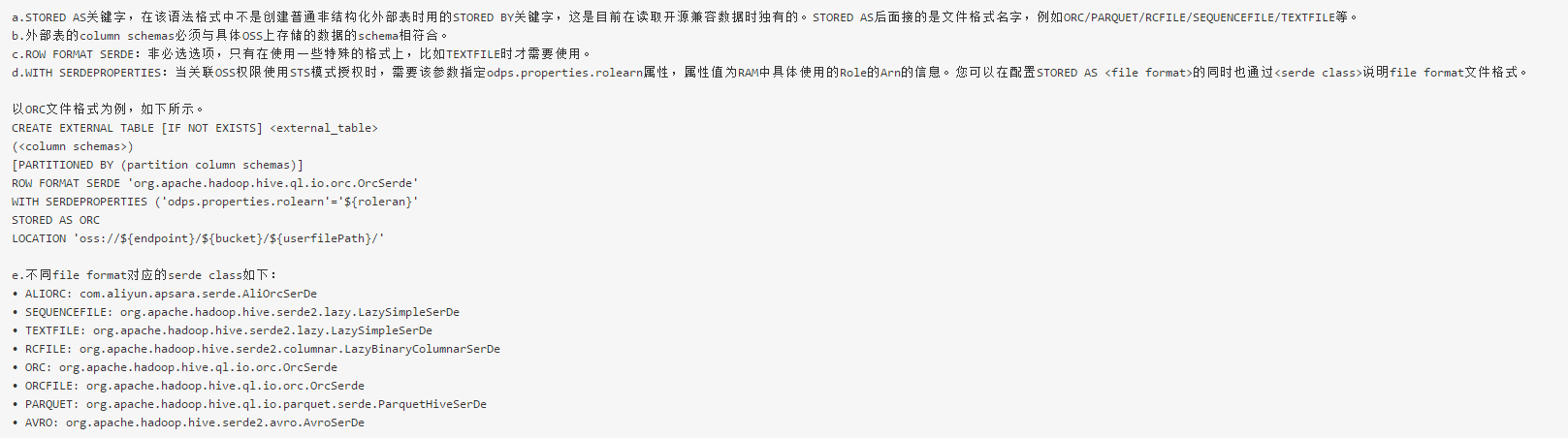
(3)外部表创建格式说明
语法格式与Hive的语法相当接近,但需注意以下问题。
(4)用Arn、AK两种认证方式建外表示例
a.用RAM中具体使用的Role的Arn的信息创建外部表
当关联OSS权限使用STS模式授权时,需要该参数指定odps.properties.rolearn属性,属性值为RAM中具体使用的Role的Arn的信息。

示例如下:
b.明文AK创建外部表(不推荐使用这种方式)
如果不使用STS模式授权,则无需指定odps.properties.rolearn属性,直接在Location传入明文AccessKeyId和AccessKeySecret。
Location如果关联OSS,需使用明文AK,写法如下所示。

示例如下:
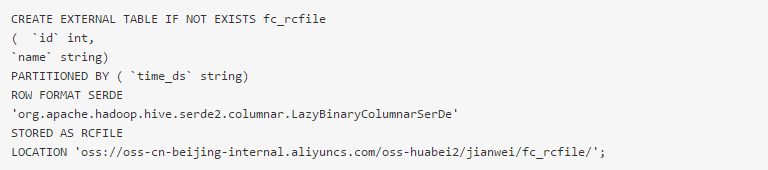
2、创建 Rcfile 类型的外部表
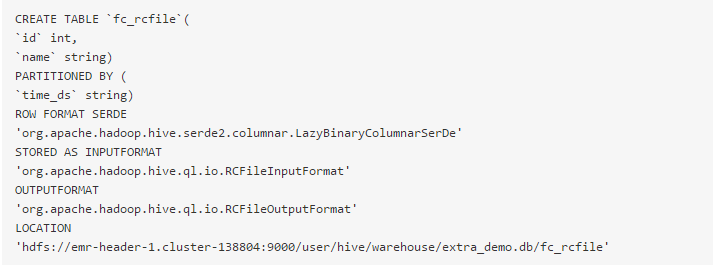
(1)查询HIVE表schema

结果如下:
(2)在MaxCompute创建外部表
(3)添加分区

(4)查询数据

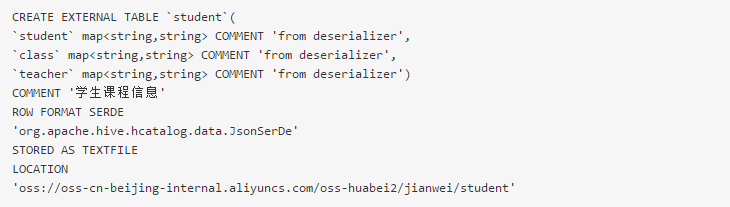
3、创建Json类型的外部表
(1)创建Json类型的外部表
(2)在对应的OSS控制台bucket上传Json文件数据。
(3)查询外部表的数据
报错信息如下所示:
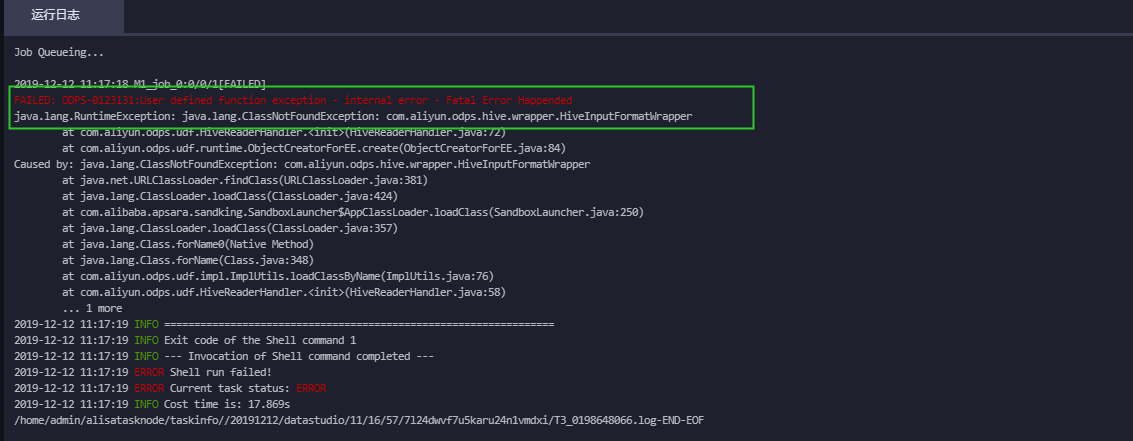
解决办法:需要设置开启hive兼容的flag。

重新查询数据即可正确返回Json数据。
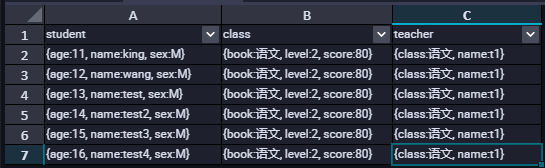
以下是在Hive中查询的数据,可以看到这两处数据是一致的。

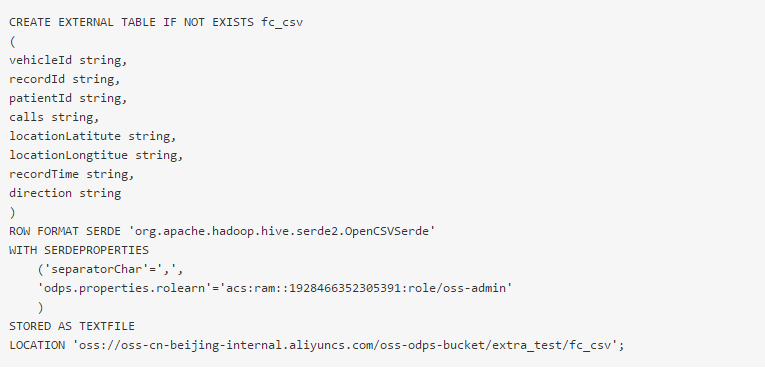
4、创建CSV格式的外部表
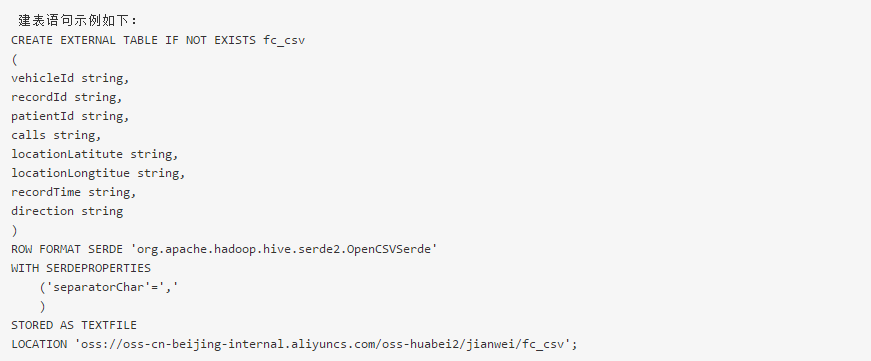
(1)创建CSV格式的外部表
(2)查询数据

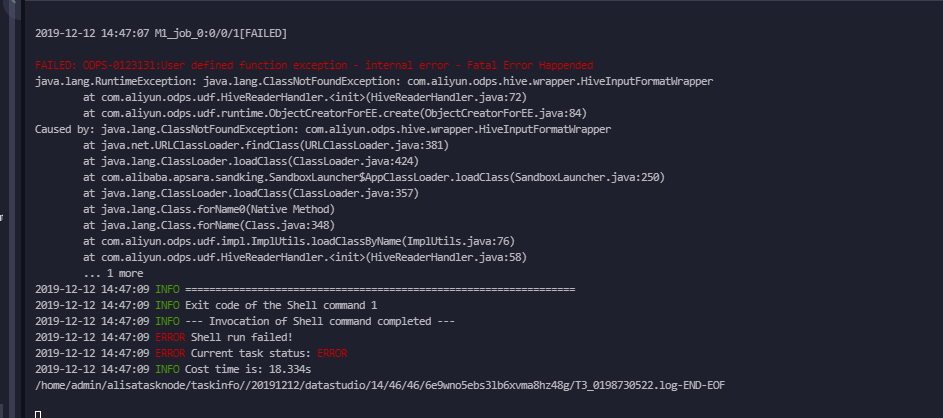
不加Hive兼容的flag设置会发现有如下报错信息:


5、创建压缩格式的外部表
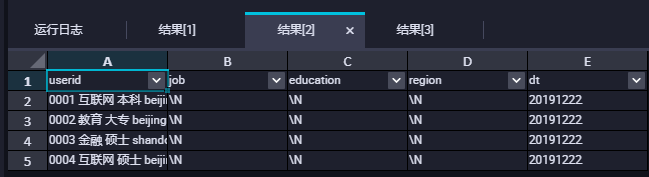
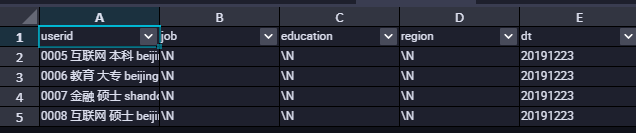
创建外部表时列分隔符需要使用field.delim。选择delimiter会报错或数据没有按照预期的分割符去分割。以下分别按照两种方式去创建外部表。
需要设置以下说明的属性flag。

(1)创建外部表
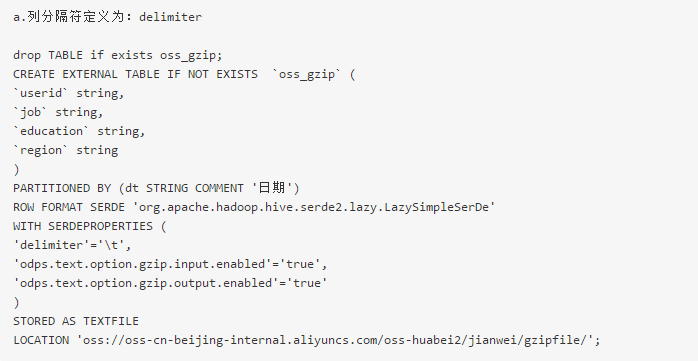
查询数据的时候会发现数据并没有按照我们的分隔符去进行分割,如下图所示:
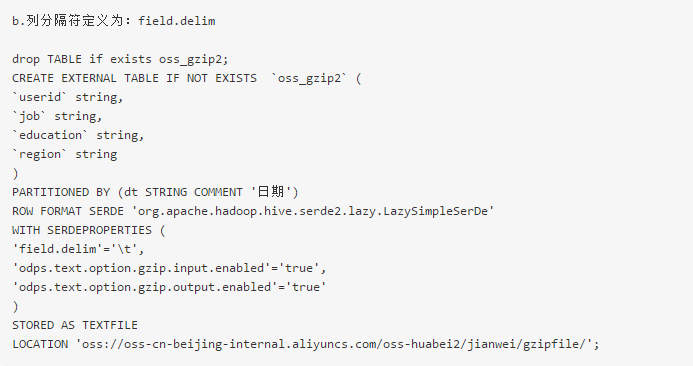

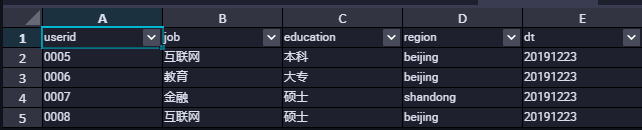

6、创建存在新数据类型的外部表
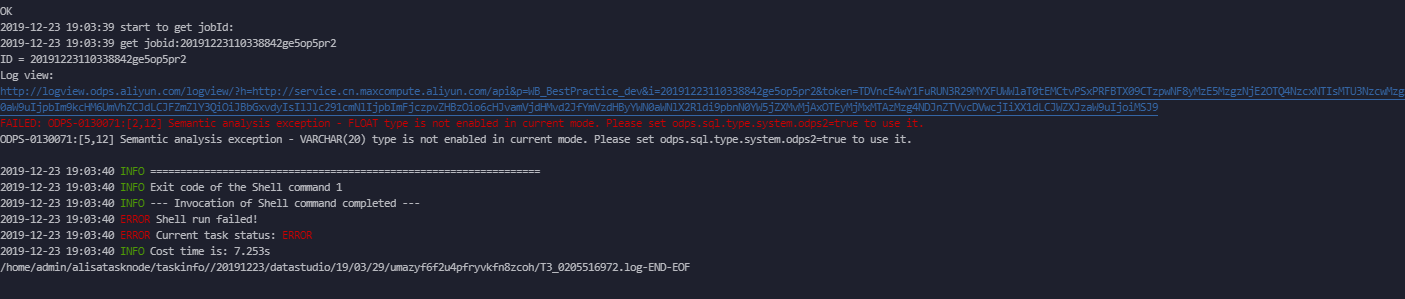
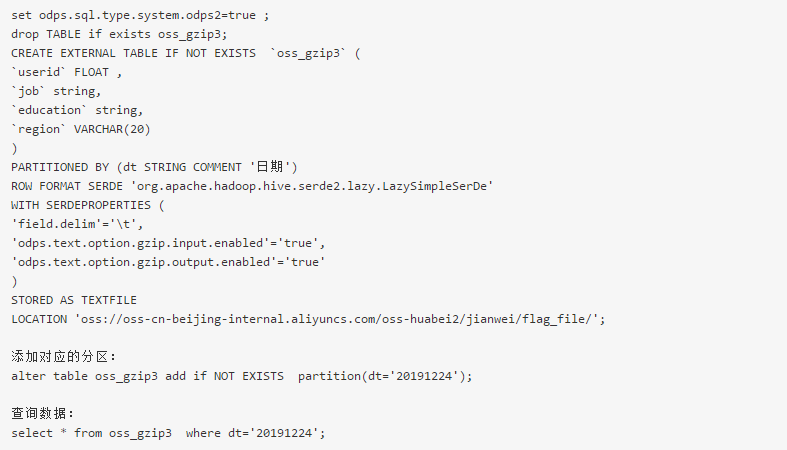
当外部表创建字段涉及新数据类型时,需要开启新类型flag。

否则会报如下错误:
四、利用Information Schema元数据查看project、table的操作行为以及费用计算
1、主账号安装package
开始使用前,需要以Project Owner身份安装Information Schema的权限包,获得访问本项目元数据的权限。
以下错误是没有安装对应的Information Schema的权限包和子账号没有相关的权限

安装Information Schema的权限包方式有如下两种:
(1)在MaxCompute命令行工具(odpscmd)中执行如下命令。

(2)在DataWorks中的数据开发 > 临时查询中执行如下语句。

2、给子账号授权

3、查询元数据信息

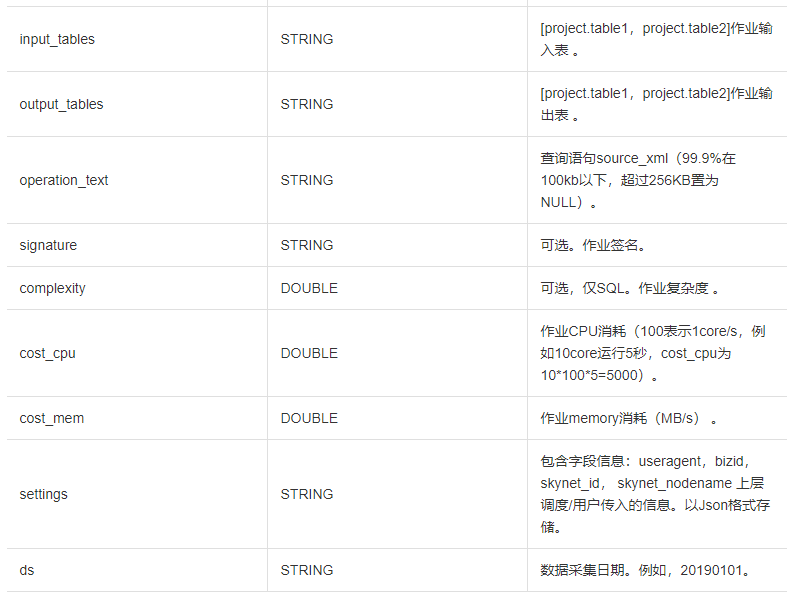
TASKS_HISTORY字段列信息如下:
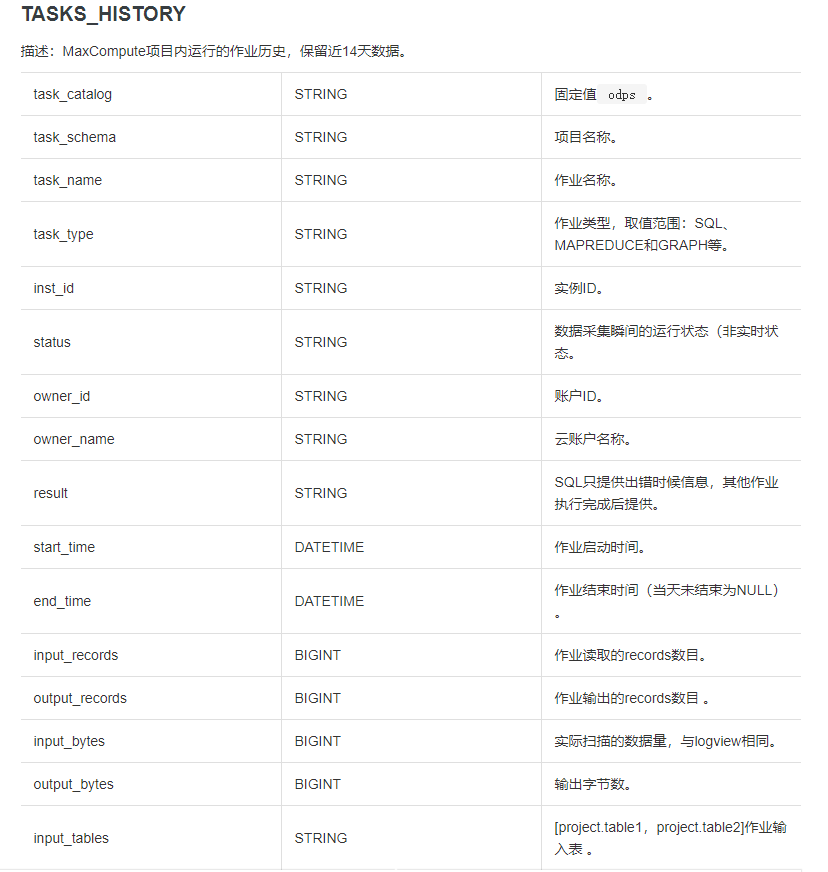
![]()
4、通过 TASKS_HISTORY 计算SQL费用
SQL任务按量计费:您每执行一条SQL作业,MaxCompute将根据该作业的输入数据及该SQL的复杂度进行计费。该费用在SQL执行完成后产生,并在第二天做一次性的计费结算。

计算输入数据量:指一条SQL语句实际扫描的数据量,大部分的SQL语句有分区过滤和列裁剪,所以一般情况下这个值会远小于源表数据大小。
在 information_schema.tasks_history中字段input_bytes为实际扫描的数据量也就是我们的计算输入数据量。字段complexity为sql复杂度。所以我们可以根据以下公式来计算SQL费用。

本文作者:刘-建伟
本文为阿里云内容,未经允许不得转载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号