

MaxCompute - ODPS重装上阵 第六弹 - User Defined Type
MaxCompute(原ODPS)是阿里云自主研发的具有业界领先水平的分布式大数据处理平台, 尤其在集团内部得到广泛应用,支撑了多个BU的核心业务。 MaxCompute除了持续优化性能外,也致力于提升SQL语言的用户体验和表达能力,提高广大ODPS开发者的生产力。
MaxCompute基于ODPS2.0新一代的SQL引擎,显著提升了SQL语言编译过程的易用性与语言的表达能力。我们在此推出MaxCompute(ODPS2.0)重装上阵系列文章
- 第一弹 - 善用MaxCompute编译器的错误和警告
- 第二弹 - 新的基本数据类型与内建函数
- 第三弹 - 复杂类型
- 第四弹 - CTE,VALUES,SEMIJOIN
- 第五弹 - SELECT TRANSFORM
- 第六弹 - User Defined Type
- 第七弹 - Grouping Set, Cube and Rollup
第五弹向您介绍了MaxCompute如何嵌入其他语言的脚本。SELECT TRANSFORM的优势在于可以不创建function甚至不上传资源的情况下执行其他语言的脚本,而即使需要编写资源也没有任何由MaxCompute规定的格式要求和依赖。
本文将介绍另一种将这一优势提升到更高层次的新功能:User Defined Type,简称UDT。
- 场景1
某个功能通过其他语言既可非常简单的实现,如用java预计只需要一次内置类的方法调用就可以实现,但MaxCompute没有合适的内置函数实现这一功能。为如此简单的功能写一个UDF非常繁琐,体验很差。 - 场景2
SELECT TRANSFORM能够让我直接把脚本写到sql语句中,大大提升了代码的可读性(UDF为黑盒,而直接写在sql里面的脚本,功能一目了然)和维护性(不需要commit多个代码文件,特别是sql和其他的脚本文件存放的repository还不一样)。但是某些语言无法这么用,比如java源代码必须经过编译才能执行,那么有没有办法能够让这些语言享受相同的优势? - 场景3
sql中需要调用第三方库来实现相关功能。希望能够在SQL里面直接调用,而不需要再wrap一层UDF。
上述场景的问题,通过UDT能够非常好地解决,接下来将具体介绍UDT使用。
本文中很多例子采用MaxCompute Studio作展示,没有安装MaxCompute Studio的用户,可以参照文档安装MaxCompute Studio),导入测试MaxCompute项目,创建工程。
功能简介
MaxCompute中的UDT(User Defined Type)功能支持在SQL中直接引用第三方语言的类或者对象,获取其数据内容或者调用其方法 。
在其他的SQL引擎中也有UDT的概念,但是和MaxCompute的概念有许多差异。很多SQL引擎中的概念比较像MaxCompute的struct复杂类型。而某些语言提供了调用第三方库的功能,如Oracle 的 CREATE TYPE。相比之下,MaxCompute的UDT更像这种CREATE TYPE的概念,Type中不仅仅包含数据域,还包含方法。而且MaxCompute做的更彻底:开发者不需要用特殊的DDL语法来定义类型的映射,而是在SQL中直接使用。
一个简单的例子如下:

上面的例子输出:

和java语言一样,java.lang这个package是可以省略的。所以上面例子更可以简写为:

可以看到,上面的例子在select列表中直接写上了类似于java表达式的表达式,而这个表达式的确就按照java的语义来执行了。这个例子表现出来的能力就是MaxCompute的UDT。
UDT所提供的所有扩展能力,实际上用UDF都可以实现。譬如上面的例子,如果使用UDF实现,需要做下列操作。
首先,定义一个UDF的类:
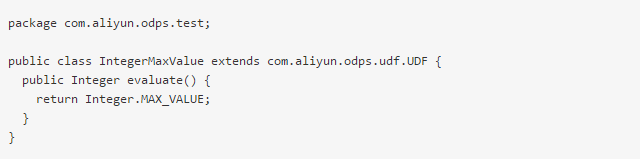
然后,将上面的UDF编译,并打成jar包。然后再上传jar包,并创建function

最后才可以在sql中使用

UDT相当于简化了上述一系列的过程,让开发者能够轻松简单地用其他语言扩展SQL的功能。
上述例子表现的是java静态域访问的能力,而UDT的能力远不限于此。譬如下面的例子:

上述例子输出结果 100000000000000000100。
这个例子还表现了一种用UDF比较不好实现的功能:子查询的结果允许UDT类型的列。例如上面变量a的x列是java.math.BigInteger类型,而不是内置类型。UDT类型的数据可以被带到下一个operator中再调用其他方法,甚至能参与数据shuffle。比如上面的例子,在MaxCompute studio中的执行图如下:
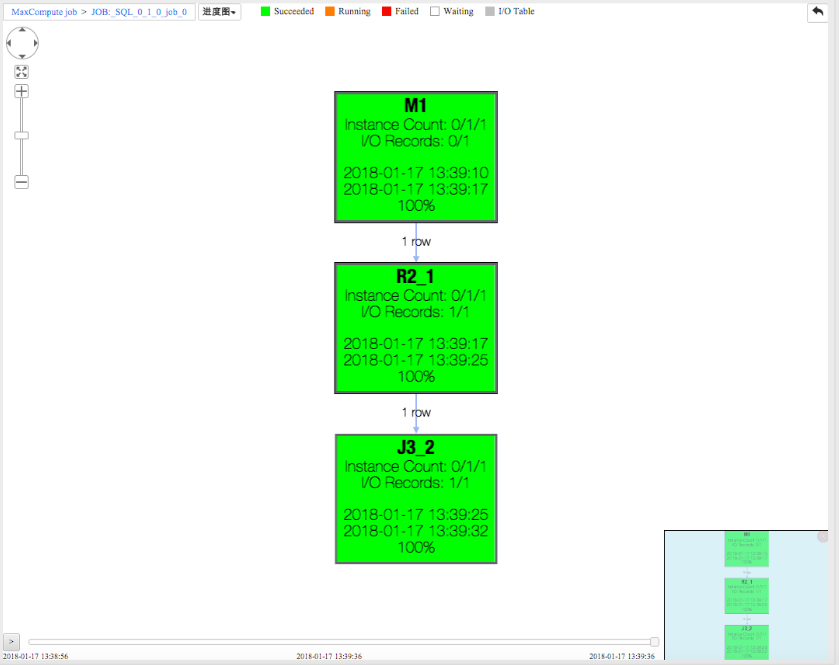
可以看出图中共有三个STAGE: M1, R2 和 J3。熟悉MapReduce原理的用户会知道,由于join的存在需要做数据reshuffle,所以会出现多个stage。一般情况下,不同stage不仅是在不同进程,甚至是在不同物理机器上运行的。双击代表M1的方块,显示如下:

可以看到,M1仅仅执行了 new java.math.BigInteger(x) 这个操作。而同样点开代表J3的方块,可以看到 J3 在不同的阶段执行了 java.math.BigInteger.valueOf(y) 的操作,和 x.add(y).toString() 的操作:

这几个操作不仅仅是分阶段执行的,甚至是在不同进程,不同物理机器上执行的。但是UDT把这个过程封装起来,让用户看起来和在同一个JVM中执行的效果几乎一样。
UDT同样允许用户上传自己的jar包,并且直接引用。如上面UDF的jar包。用UDT来使用:

如果觉得写 package全路径麻烦,还可以像java的import一样,用flag来指定默认的package。

详细说明
- 目前UDT 只支持java语言。
-
提供一些提升使用效率的flag:
- odps.sql.session.resources :指定引用的资源,可以指定多个,用英文逗号隔开:
set odps.sql.session.resources=foo.sh,bar.txt;注意这个flag和SELECT TRANSFORM中指定资源的flag相同,所以这个flag会同时影响SELECT TRANSFORM和UDT两个功能。 - odps.sql.session.java.imports :指定默认的package,可以指定多个,用逗号隔开。和java的import语句类似,可以提供完整类路径,如 java.math.BigInteger,也可以使用
*。暂不支持static import。
- odps.sql.session.resources :指定引用的资源,可以指定多个,用英文逗号隔开:
-
UDT支持的操作包括:
- 实例化对象的new操作。
- 实例化数组的new操作,包括使用初始化列表创建数组,如
new Integer[] { 1, 2, 3 }。 - 方法调用,包括静态方法调用(因此能用工厂方法构建对象).
- 域访问,包括静态域。
-
注意:
- 只支持公有方法和共有域的访问。
- UDT中的标识符是大小写敏感的,包括package,类名,方法名,域(field)名。
- UDT支持类型转换,但限于SQL形式,如 cast(1 as java.lang.Object)。不支持java形式的类型转换,如(Object)1。
- 暂不支持匿名类和lambda表达式(后续版本可能会支持)。
- 暂不支持无返回值的函数调用(这个是因为UDT都是出现在expression中,没有返回值的函数调用无法嵌入到expression中,这个问题在后续的版本中可能会有解决方案)。
- Java SDK 的类都是默认可用的。但是需要注意目前runtime使用的JDK版本是JDK1.8,比该版本更新的JDK功能可能不支持。
- 需要特别注意的是, 所有的运算符都是MaxCompute SQL的语义,不是UDT的语义 。如
String.valueOf(1) + String.valueOf(2)的结果是 3 (string隐式转换为double,并且double相加),而不是'12' (java中string相加是concatenate的语义)。
除了string的相加操作比较容易混淆外,另一个比较容易混淆的是=操作。SQL中的=不是赋值 而是判断相等。而对于java对象来说,判断相等应该用equals方法,通过等号判断的相等无法保证其行为(在UDT场景下,同一对象的概念是不能保证的,具体原因参考下述第8点)。 -
内置类型与特定java类型有一一映射关系,见UDF类型映射。这个映射在UDT也有效:
- 内置类型的数据能够直接调用其映射到的Java类型的方法,如
'123'.length() , 1L.hashCode()。 - UDT类型能够直接参与内置函数或者UDF的运算, 如
chr(Long.valueOf('100')),其中 Long.valueOf 返回的是 java.lang.Long 类型的数据,而内置函数chr接受的数据类型是内置类型BIGINT。 - Java的primitive类型可以自动转化为其boxing类型,并应用上面两条规则
- 注意:某些内置类型是需要
set odps.sql.type.system.odps2=true;才能使用的。否则会报错。
- 内置类型的数据能够直接调用其映射到的Java类型的方法,如
- UDT对泛型有比较完整的支持,如
java.util.Arrays.asList(new java.math.BigInteger('1')),编译器能够根据参数类型知道该方法的返回值是java.util.List<java.math.BigInteger>类型
注意构造函数需要指定类型参数,否则使用java.lang.Object,这一点和java保持一致:
new java.util.ArrayList(java.util.Arrays.asList('1', '2')) 的结果是 java.util.ArrayList<Object>类型;
而 new java.util.ArrayList<String>(java.util.Arrays.asList('1', '2')) 的结果是 java.util.ArrayList<String> 类型。
-
UDT对 "同一对象" 的概念是模糊的。这是由数据的reshuffle导致的。从上面第一部分的join的示例可以看出,对象有可能会在不同进程,不同物理机器之间传输,在传输过程中同一个对象的两个引用后面可能分别引用了不同的对象(比如对象先被shuffle到两台机器,然后下次又shuffle回一起)。
- 在使用UDT的时候,应该避免使用
= operator来判断相等,而是使用equals方法。 - 某行某列的对象,其内部包含的各个数据对象的相关性是可以保证的。不能保证的是不同行或者不同列的对象的数据相关性。
- 在使用UDT的时候,应该避免使用
- 目前UDT不能用作shuffle key:包括join,group by,distribute by,sort by, order by, cluster by 等结构的key
并不是说UDT不能用在这些结构里面,UDT可以在expression中间的任意阶段使用,只是不能作为最终输出。比如虽然不能group by new java.math.BigInteger('123'),但是可以group by new java.math.BigInteger('123').hashCode()。因为hashCode的返回值是int.class类型可以当做内置类型int来使用(应上述“内置类型与特定java类型映射”的规则)。
注意:这个限制未来的版本会计划去掉。
-
UDT扩展了类型转换规则:
- UDT对象能够被隐式类型转换为其基类对象。
- UDT对象能够被强制类型转换为其基类或子类对象。
- 没有继承关系的两个对象之间遵守原来的类型转换规则,注意这时候可能会导致内容变化,比如java.lang.Long类型的数据是可以强制转换为java.lang.Integer的,应用的是内置类型的bigint强制转换为int的过程,而这个过程会真的导致数据内容的变化,甚至可能会有精度损失。
-
目前UDT对象不能落盘。这意味着不能将UDT对象insert到表中(实际上DDL不支持UDT,创建不出来这样的表),当然,隐式类型转换变成了内置类型的除外。同时,屏显的最终结果也不能是UDT类型,对于屏显的场景,由于所有的java类都有toString()方法,而
java.lang.String类型是合法的。所以debug的时候,可以用这种方法来观察UDT的内容。- 可以设置
set odps.sql.udt.display.tostring=true;这样MaxCompute会自动把所有的以UDT为最终输出的列wrap上java.util.Objects.toString(...),从而方便调试。这个flag只对屏显语句生效,对insert语句不生效,所以专门用在调试中。 - 内置类型支持binary或者string类型,因此可自定义实现serialize的过程,将byte[]的数据落盘。下次读出来的时候再还原回来。见后面的例子
- 某些类可能自带序列化和反序列化的方法,如protobuffer。目前UDT依旧支持落盘,还是需要自行调用序列化反序列化方法,变成binary数据类型来落盘。
- 可以设置
- UDT不仅能够实现scalar函数的功能,配合着内置函数collect_list和explode(doc),完全能够实现 aggregator和table function的功能。
更多示例
使用Java数组

JSON用户的福音
UDT的runtime自带一个gson的依赖(2.2.4)。因此用户可以直接使用gson

相比于get_json_object,上述用法不仅仅是使用方便了,在需要对json字符串多个部分做内容提取时,先将gson字符串反序列成格式化数据,其效率要高得多。
除了GSON, MaxCompute runtime自带的依赖还包括: commons-logging(1.1.1), commons-lang(2.5), commons-io(2.4),protobuf-java(2.4.1)。
复杂类型操作
内置类型array和map 与 java.util.List 和 java.util.Map 存在映射关系。结果就是:
- Java中实现了java.util.List 或者 java.util.Map 接口的类的对象,都可以参与MaxComputeSQL的复杂类型操作。
- MaxCompute 中 array, map的数据,能够直接调用 List 或者 Map 的接口。

还可以实现一些特殊的功能,比如 array的distinct

聚合操作的实现
UDT实现聚合的原理是,先用COLLECT_SET 或 COLLECT_LIST 函数将数据转变成 List, 之后对该List应用UDT的标量方法求得这一组数据的聚合值。
如用下面的示例实现对BigInteger求中位数(由于数据是 java.math.BigInteger类型的,所以不能直接用内置的median函数)

由于collect_list会先把所有数据都收集到一块,是没有办法实现partial aggregate的,所以这个做法的效率会比内置的aggregator或者udaf低,所以 在内置aggregator能实现的情况下,应尽量使用内置的aggregator 。同时把一个group的所有数据都收集到一起的做法,会增加数据倾斜的风险。
但是另一方面,如果UDAF本身的逻辑就是要将所有数据收集到一块(比如类似wm_concat的功能),此时使用上述方法,反而可能比UDAF(注意不是内置aggregator)高。
表值函数的实现
表值函数允许输入多行多列数据,输出多行多列数据。可以按照下述原理实现:
- 对于输入多行多列数据,可以参考聚合函数实现的示例。
- 要实现多行的输出,可以让UDT方法输出一个Collection类型的数据(List 或者 Map),然后调用explode函数,将Collections展开成多行。
- UDT本身就可以包含多个数据域,通过调用不同的getter方法来获取各个域的内容即可展开成多列。
下述示例实现将一个json字符串的内容展开出来的功能

读取资源文件
我们知道在UDF中可以通过ExecutionContext对象来读取资源文件。现在UDT也可以通过 com.aliyun.odps.udt.UDTExecutionContext.get() 方法来或者这样的一个 ExecutionContext 对象。
下述示例将资源文件 1.txt 读取到一个string对象中,并输出:

UDT对象持久化
UDT对象默认是不支持落盘的。但是有方法能够把UDT的对象持久化。基本的思想是将数据序列化成为binary或者string来做持久化,或者将udt对象展开,持久化里面的能转成内置类型的关键数据。
如下UDT定义:

将对象展开成内置类型:

需要用时再重新构造:

或者将对象serialize成binary。
平展开的最大问题是,序列化和反序列化的麻烦。当然可以直接转成binary。如改造Shape类:

如果直接利用已有的框架,也许会更方便。如 Shape 是用 ProtoBuffer 定义的

SQL中直接调用pb的方法
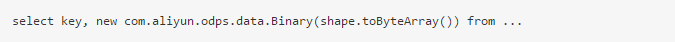
MaxCompute Studio的支持
本功能和 MaxCompute Studio 搭配着使用,才能发挥其最大的价值。
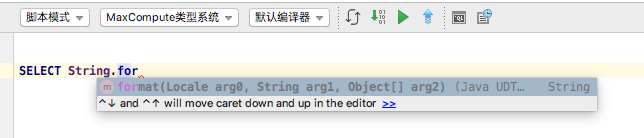
- MaxCompute Studio 智能提示能够大大提升编码效率。

- MaxCompute Studio 的类型推导过程,能让您知道某个表达式是什么类型。

- MaxCompute Studio 的实时语法检查,能快速定位问题语法问题。

功能,性能与安全性
功能方面,UDT的优势是显而易见的:
- 使用简单,不需要定义任何function。
- 支持JDK的所有功能,从而扩展了SQL的能力。
- 代码直接和SQL放在一块,便于管理。
- 其它类库拿来即用,代码重用率高。
- 可以使用面向对象的思想设计某些功能。
在性能方面,UDT执行过程和UDF非常接近,其性能与UDF几乎是一致的,而且产品针对UDT做了很多优化,在某些场景下UDT的性能甚至略高一筹:
- 对象在一个进程内实际上是不需要做列化反序列化的,只有跨进程的时候才需要。简单地说,就是在没有join或者aggregator等需要做数据reshuffle的情况下,UDT并没有序列化反序列化的开销。
- UDT的Runtime实现是基于codegen,而不是反射,所以不会存在反射带来的性能损失
- 连续的多个UDT的操作,实际上会合并在一起,在一个FunctionCall里一起执行,如上述例子中
values[x].add(values[y]).divide(java.math.BigInteger.valueOf(2))这个看似存在多次UDT方法调用的操作,实际上只有一次调用。所以虽然UDT操作的单元都比较小,但是并不会因此造成多次函数调用的接口上的额外开销。
在安全控制方面,UDT和UDF完全一样。即都会受到沙箱policy的限制。所以如果要使用受限的操作,需要打开沙箱隔离,或者申请沙箱白名单。
总结
本文从使用的角度介绍了UDT的功能。UDT能够在SQL中直接写java的表达式,并可以引用jdk中的类。这一功能极大地方便扩展SQL的功能。
当然,UDT的功能还有许多功能还有待完善。文中也提到了几点有待完善的功能:
- 支持无返回值的函数调用(或者有返回值,但是忽略返回值,直接取操作数本身,如调用List的add方法,结束后返回执行完add操作的List)。
- 支持匿名类和lambda表达式。
- 支持用作shuffle key。
- 支持JAVA外的其他语言,如python。
本文作者:海清
本文为阿里云内容,未经允许不得转载。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架
2019-01-08 玩转大数据系列之四:搜索服务
2019-01-08 RocketMQ源码分析之RocketMQ事务消息实现原下篇(事务提交或回滚)
2019-01-08 RocketMQ源码分析之RocketMQ事务消息实现原理中篇----事务消息状态回查
2019-01-08 RocketMQ源码分析之RocketMQ事务消息实现原理上篇(二阶段提交)
2019-01-08 RocketMQ源码分析之从官方示例窥探:RocketMQ事务消息实现基本思想