
携程实时智能检测平台建设实践
摘要:本次演讲将为大家介绍携程实时智能异常检测平台——Prophet。到目前为止,Prophet基本覆盖了携程所有业务线,监控指标的数量达到10K+,覆盖了携程所有订单、支付等重要的业务指标。Prophet将时间序列的数据作为数据输入,以监控平台作为接入对象,以智能告警实现异常的告警功能,并基于Flink实时计算引擎来实现异常的实时预警,提供一站式异常检测解决方案。
演讲嘉宾简介:潘国庆,携程大数据研发经理。
以下内容根据演讲视频以及PPT整理而成。
https://developer.aliyun.com/live/1790
本次分享主要围绕以下四个方面:
- 背景介绍
- Prophet
- 智能化与实时化
- 挑战与展望
一、背景介绍
1.规则告警带来的问题
大部分监控平台是基于规则告警实现监控指标的预警。规则告警一般基于统计学,如某个指标同比、环比连续上升或下降到一定阈值进行告警。规则告警需要用户较为熟悉业务指标的形态,从而才能较为准确的配置告警阈值,这样带来的问题是配置规则告警非常繁琐、告警效果也比较差,需要大量人力物力来维护规则告警。当一个告警产生时,也需要耗费许多人力验证告警是否正确并确认是否需要重新调整阈值。在携程,规则告警还涉及了其它问题,比如携程光公司级别的监控平台就有三个,每个业务部门还会根据自己的业务需求或业务场景构建自己的监控平台。携程内部有十几个不同规模的监控平台,在每一个监控平台都配置监控指标对于用户是非常繁琐的。

二、Prophet
针对规则告警存在的以上几种问题,携程构建了自己的实时智能异常检测平台——Prophet。携程构建Prophet的灵感源于FaceBook的Prophet,但实现上有别于FaceBook的Prophet。
1.一站式异常检测解决方案
首先,Prophet以时间序列类型的数据作为数据输入。其次,Prophet以监控平台作为接入对象,以去规则化为目标。基于深度学习算法实现异常的智能检测,基于实时计算引擎实现异常的实时检测,提供了统一的异常检测解决方案。
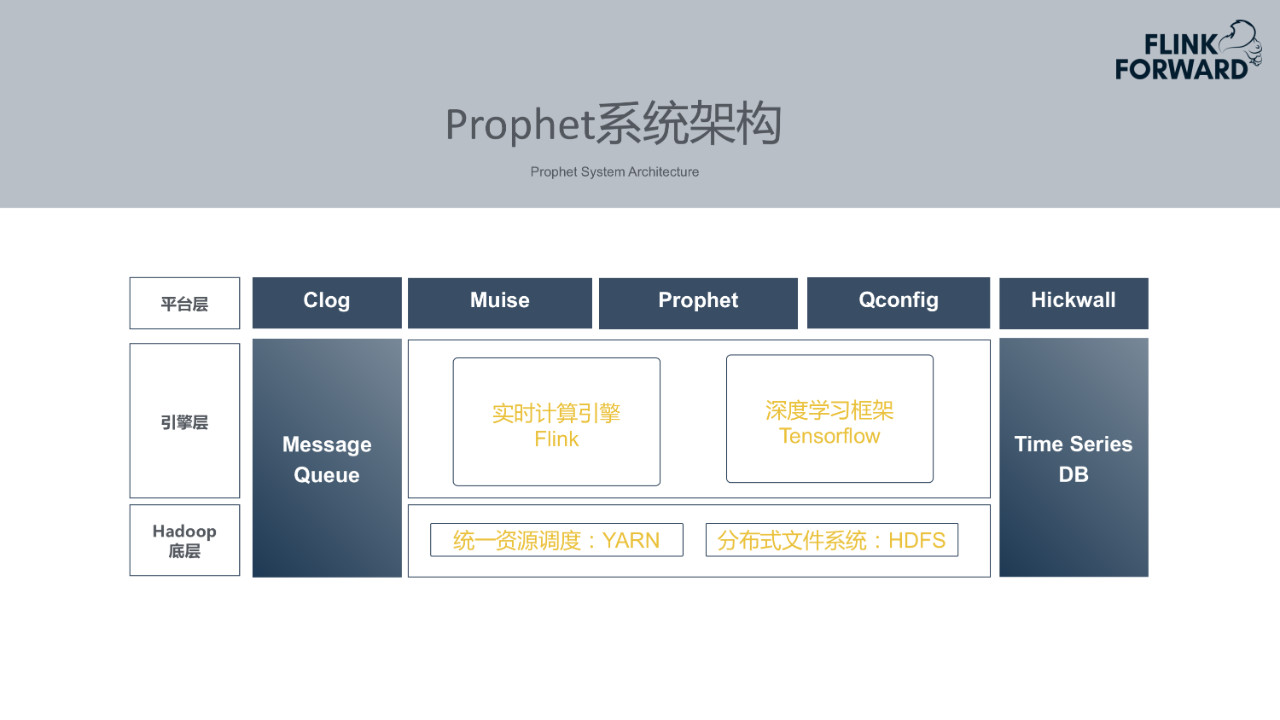
2.Prophet系统架构
- 底层:Hadoop底层。YARN作为统一资源调度的引擎,主要用于运行Flink的作业。HDFS主要用于存储训练好的TensorFlow模型。
- 引擎层:首先数据必须实时存在于消息队列当中,Prophet使用的是Kafka。此外,Prophet使用Flink计算引擎实现实时异常预警,使用TensorFlow作为深度学习模型的训练引擎。同时Prophet基于时序数据库存储历史数据。
- 平台层:最上层是对外提供服务的平台层Prophet。Clog用于采集作业日志。Muise是实时计算平台。Qconfig用于存储作业中需要用到的配置项。Hickwall用于作业的监控告警。
3.Why Flink?
目前主流的实时计算引擎有Flink、Storm和SparkStreaming等多种,携程选择Flink作为Prophet平台的实时计算引擎的原因主要是Flink具备以下四点特征:
- 高效的状态管理:异常检测的过程中有许多状态信息需要存储。使用Flink自带的State Backend可以很好地存储中间状态信息。
- 丰富的窗口支持:窗口包含滚动窗口、滑动窗口以及其他窗口。Prophet基于滑动窗口进行数据处理。
- 支持多种时间语义:Prophet基于Event Time。
- 支持不同级别的容错语义:Prophet至少需要做到At Least Once或Exactly Once的级别。

4.Prophet操作流程
用户只需要在自己常用的监控平台上选择配置智能告警,后续所有流程都是由监控平台和Prophet智能告警平台对接完成。监控平台所需要做的包含两件事,首先将用户配置的监控指标同步到Prophet平台, 其次监控平台需将用户配置的监控指标数据实时的推送到Kafka消息队列中。
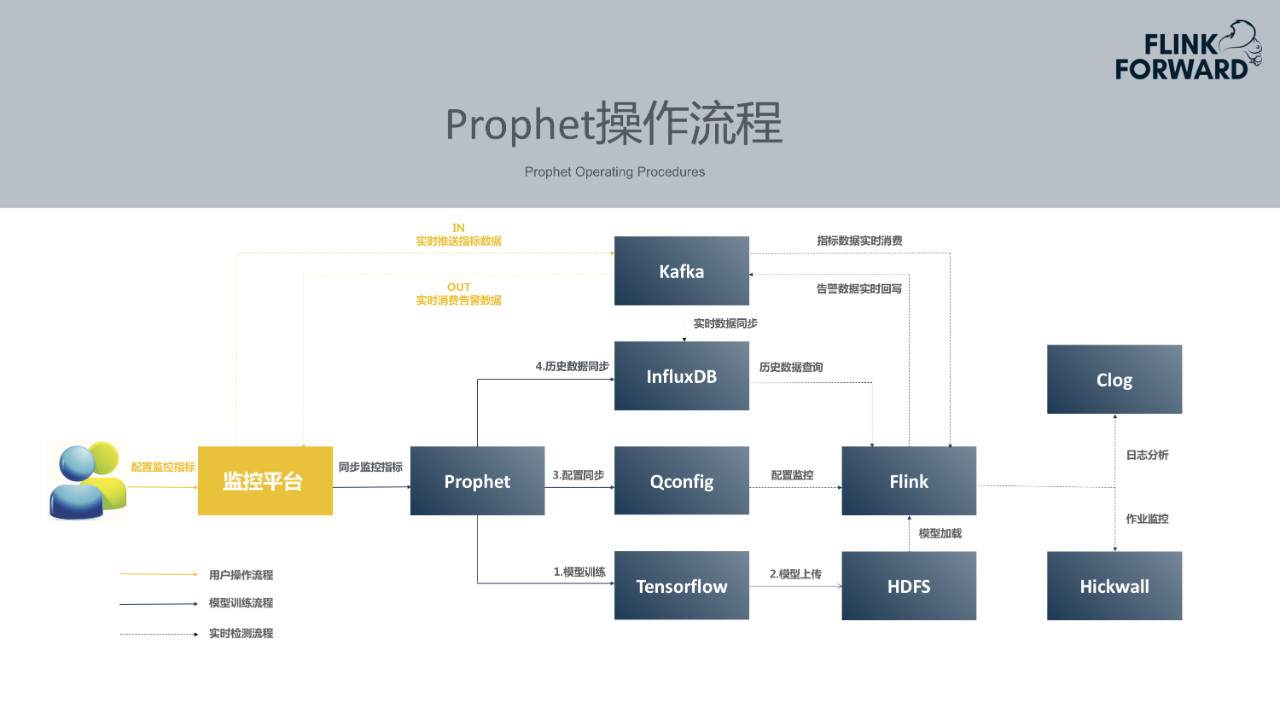
Prophet在接受到新的监控指标后,便开始尝试使用Tensorflow训练模型。模型训练需要历史数据,平台可以按照约定好的规范提供历史数据查询接口,Prophet通过接口获取历史数据并进行模型训练、如果没有接口,Prophet基于消息队列中的数据来积累训练数据集。模型训练完成后,将其上传到HDFS,Prophet会更新配置中心中的配置通知Flink有新训练好的模型可以加载。所有实时推送到Kafka里面的监控指标的数值,会同步的落到Prophet的时序数据库中,在异常检测的过程中需要用到这些指标数值。当模型训练完成后,Flink的作业一旦监听到配置发生了更新,就开始尝试加载新模型,实时消费Kafka里面的指标数据,最终产出检测结果以及异常告警会回写至Kafka,各个监控平台会从Kafka获取自己监控平台的那一部分告警数据。整套Prophet操作流程对于用户是无感知的,用户只需要配置告警,极大的提供了便捷性。
三、智能化与实时化
1.智能化挑战
在做智能检测之前还会遇到一些挑战。
- 负样本少:生产环境中发生异常的概率比较小。携程在很多年的时间仅积累了大概几千条负样本数据。
- 业务指标类型多:业务指标类型繁多,有订单、支付等业务类型的指标,也有服务类型的指标,如请求数、响应延时等,以及硬件设施类型的指标,如CPU、内存、硬盘等各种指标。
- 业务指标形态多:正因为有不同类型的业务指标,业务指标的形态也各不相同。携程将业务指标形态归纳为三部分。一是周期波动相对平稳的指标,第二是稳定的,不会剧烈波动的指标,第三是上下波动幅度非常剧烈、呈现不稳定的形态的指标。

2.深度学习算法选择
针对以上三点问题,携程尝试了RNN,LSTM和DNN等多种深度学习算法。
- RNN:RNN的优点是适合时间序列类型的数据,而缺点是存在梯度消失问题。
- LSTM模型:LSTM的优点是解决了梯度消失的问题。RNN和LSTM深度学习算法需要先给每个指标训练一个模型,然后输入当前的数据集,基于模型来预测当前数据集的走向。然后再比对预测数据集和当前数据集进行异常检测。这种方式带来的好处是检测精度高,但是单指标单模型也带来更多的资源消耗。
- DNN:DNN的优点是单个模型能够覆盖所有异常检测的场景。但是特征提取会非常复杂,需要提取不同频域的特征,需要大量用户标注数据。
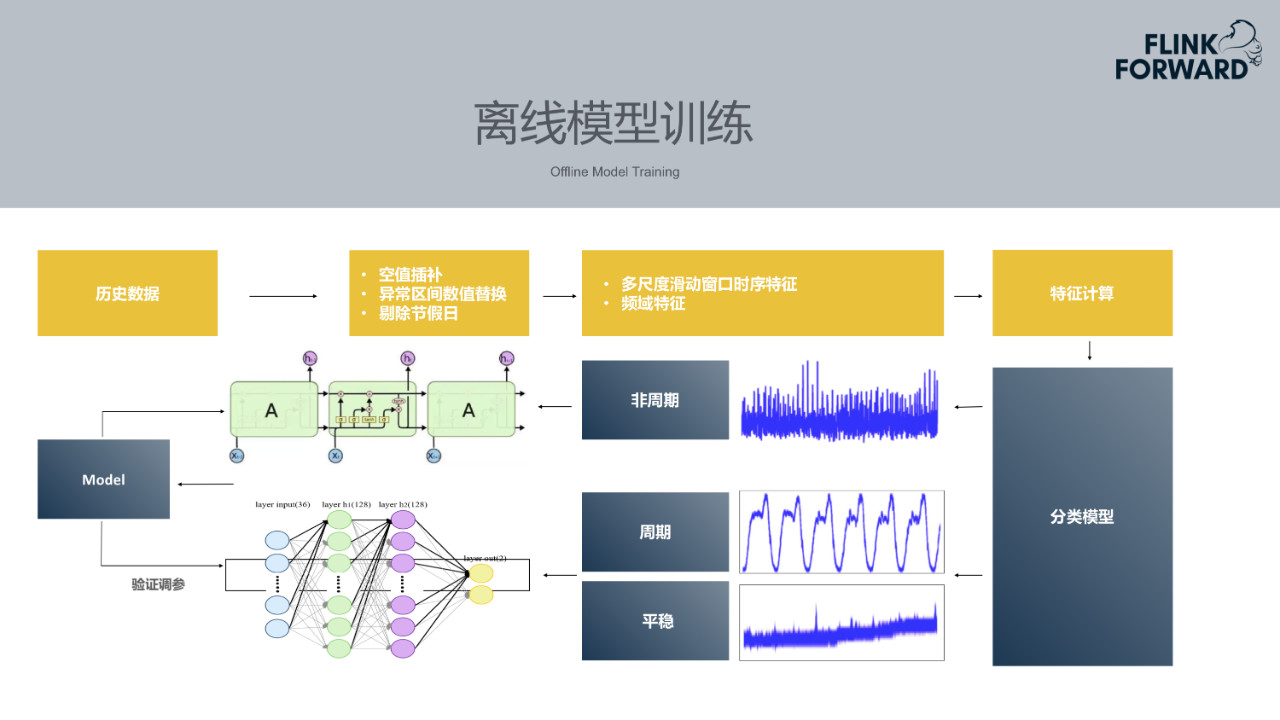
3.离线模型训练
携程一般两周发一次版本,每个业务指标都是每两周尝试训练一次,模型输入的训练数据也取两周的数据集。在使用历史数据之前需要做数据预处理,比如历史数据中可能存在null值,需要使用均值标准差将其补齐。其次历史数据区间里面肯定会有一些异常区间,需要用一些预测值替换异常区间的异常值。另外由于节假日期间数据较为复杂,需要替换节假日期间的异常值。对历史数据的数据集做数据预处理之后,开始提取其不同时序的特征或者频率的特征。然后通过一个分类模型分类出指标是平稳的、非周期的还是周期型的。不同类型的指标需要不同的模型进行训练。
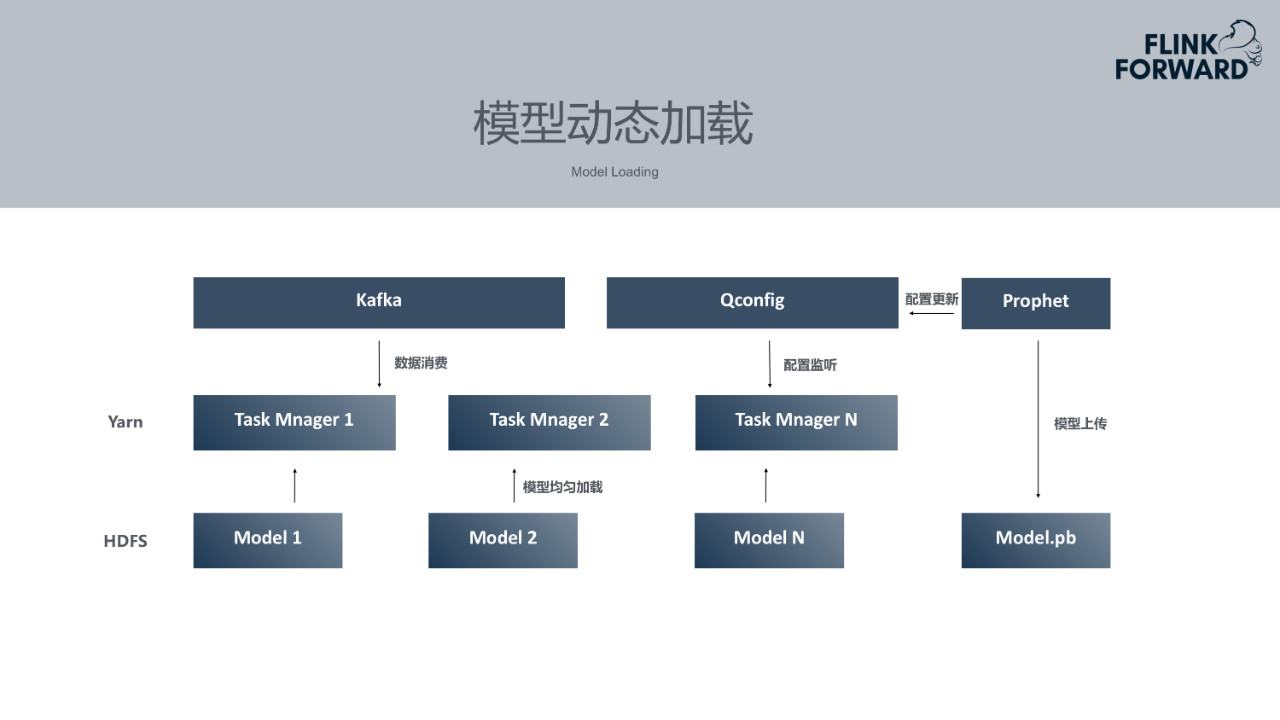
4.模型动态加载
模型训练完成后,Flink作业需要动态加载模型。但实际场景下,不可能每训练一个模型便重启一次Flink作业。所以Prophet平台将模型训练完成后上传到HDFS,通知配置中心,然后Flink作业开始从HDFS上拉取模型。为了使每个模型均匀分布在不同的Task Manager上面,所有监控指标会根据本身id做keyBy,均匀分布在不同的Task Manager上。每个Task Manager只加载自己部分的模型,以此降低资源消耗。
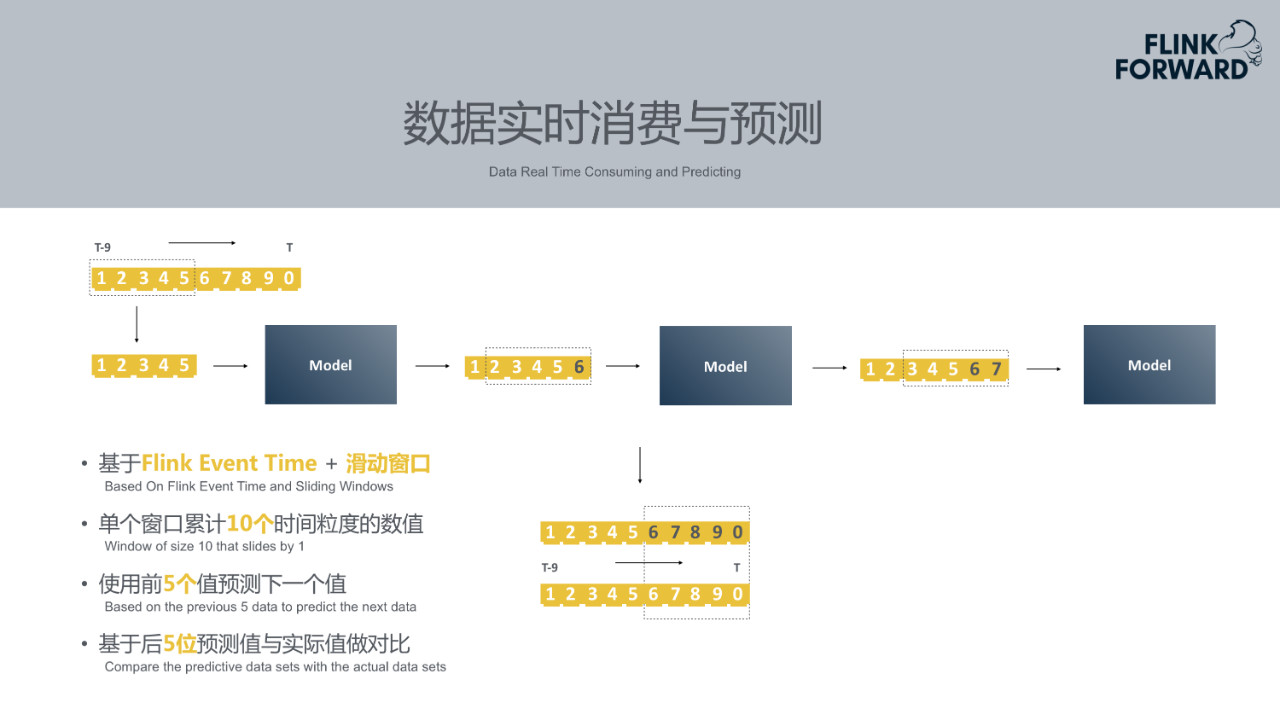
5.数据实时消费与预测
模型加载完成后需要做实时异常检测。首先从Kafka消息队列中消费实时数据。Prophet目前基于Flink Event Time+滑动窗口。监控指标的时间粒度可以分为很多种,如1分钟一个点、5分钟一个点、10分钟一个点等等。例如基于1分钟一个点的场景来看,在Flink作业中开一个窗口,其长度是十个时间粒度,即十分钟。当积累到十条数据时,用前五个数据预测下一个数据,即通过第1、2、3、4、5五个时刻的数据去预测第六个时刻的数据,然后用第2、3、4、5、6时刻的数据预测第七个时刻的数据。最终获得第6、7、8、9、10五个时刻的预测值和实际值。再利用预测值与实际值进行对比。以上是数据无异常的理想场景下的情况。
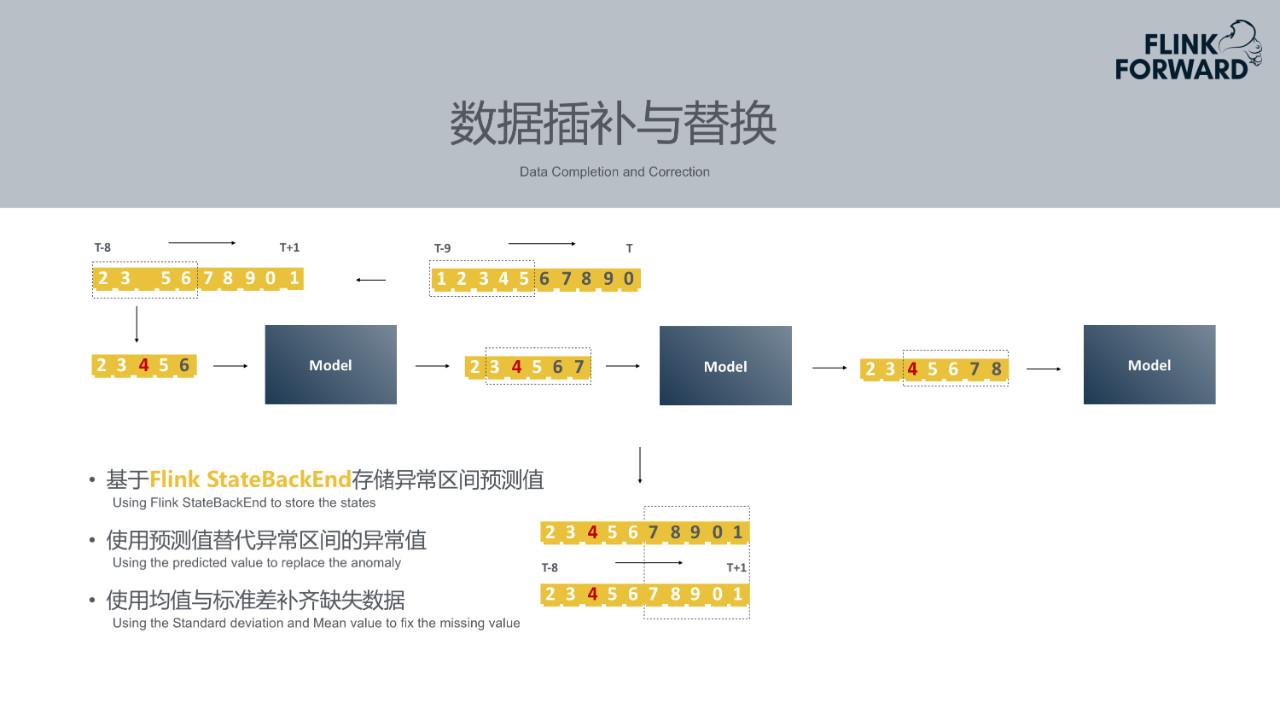
6.数据插补与替换
实际场景下往往会出现意想不到的情况。例如上述10分钟的场景中只获得了9条数据,缺少第4个时刻的数据, Prophet会使用均值标准差补齐此类缺失数据。另外如果在上一个时刻检测到第6、7、8、9、10时间区间是异常区间,发生了下跌或者上升。那么此区间的数据被认为是不正常的,不能作为模型输入。此时需要用上一批次模型预测出的第6时刻的值替换原始的第六个时间粒度的值。第2、3、4、5、6这五个时刻值中第4是插补而来的,第6是时间区间训练出来的预测预测值替换掉了异常值。以插补替换之后的值作为模型输入,得到新的预测值7。再依次进行预测。中间过程中异常区间第6、7、8、9、10时刻的预测值需要作为一个状态来存储到Flink StateBackend,后续窗口会使用到这些预测值。
7.实时异常检测
实时异常检测主要可以从以下几个方面进行判断:
- 基于异常类型与敏感度判断:不同的指标不同的异常类型,如上升异常,下跌异常。其次,不同指标敏感度不同,可以定义其为高敏感度、中敏感度、低敏感度。当高敏感度指标发生简单的下降抖动时,认为是下跌异常。中敏感度指标可能连续下跌两个点时会判断异常。对于低敏感度指标,当下跌幅度较大时才会判断为异常。
- 基于预测集与实际集的偏差判断:如果预测结果和实际结果偏差较大,认定当前第6、7、8、9、10时刻区间是潜在的异常区间。
- 基于历史同期数据均值与标准差判断:同时需要与上周同期的时间进行对比,同一区间的数值偏差较大,则判断为异常。当异常样本较多时,可以用简单的机器学习分类模型通过预测值和实际值做异常判断。

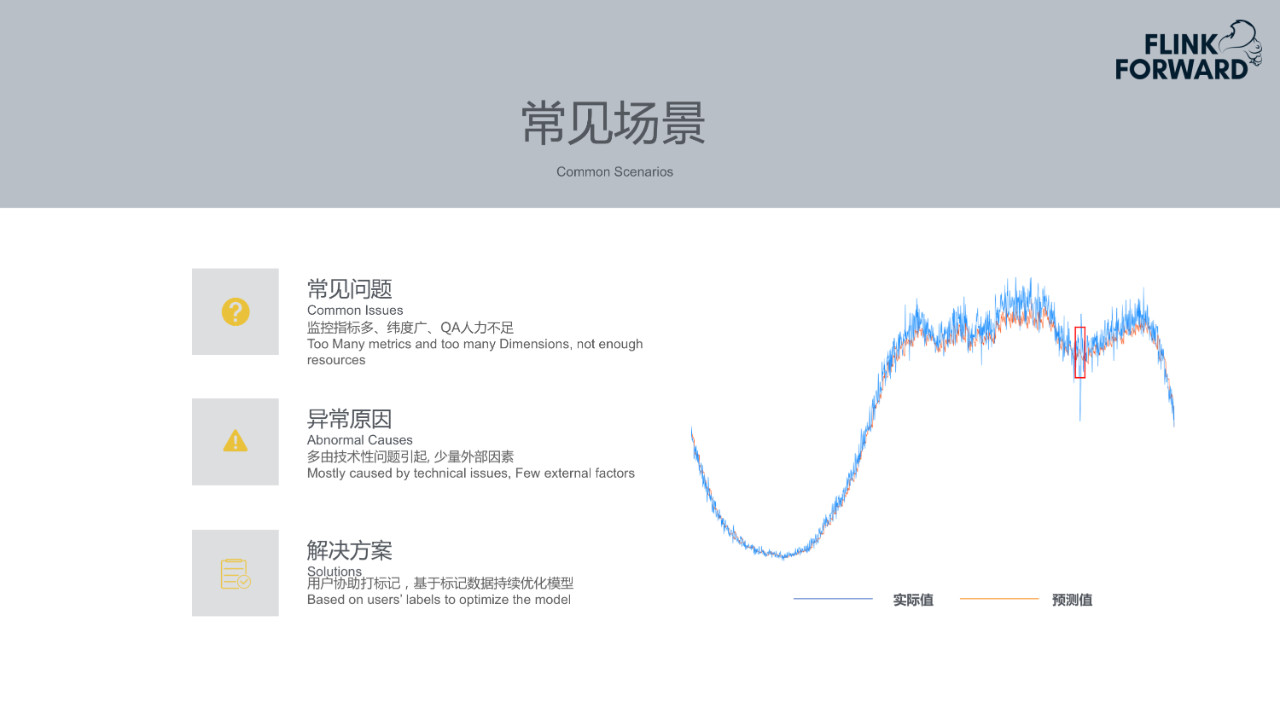
8.常见场景
- 常见问题:对于用户来说,监控指标太多,监控的维度也比较多。比如一个指标可能有max、min等不同的统计方式,监控指标的数量就会比较多。其次,用户能力有限,很难每日查看监控告警。
- 异常原因:发生异常的原因一般会是技术性问题。如发布新版本上线时可能存在的bug导致业务出现下跌。少数的情况是由于外部因素的影响,比如调用外部链接或者服务,外部服务宕掉导致自己的服务出现问题。
- 解决方案:用户为Prophet提供的检测结果进行标注,选择检测结果的正确性。用户的标注数据会用到Prophet以后的模型训练中用于优化数据集。
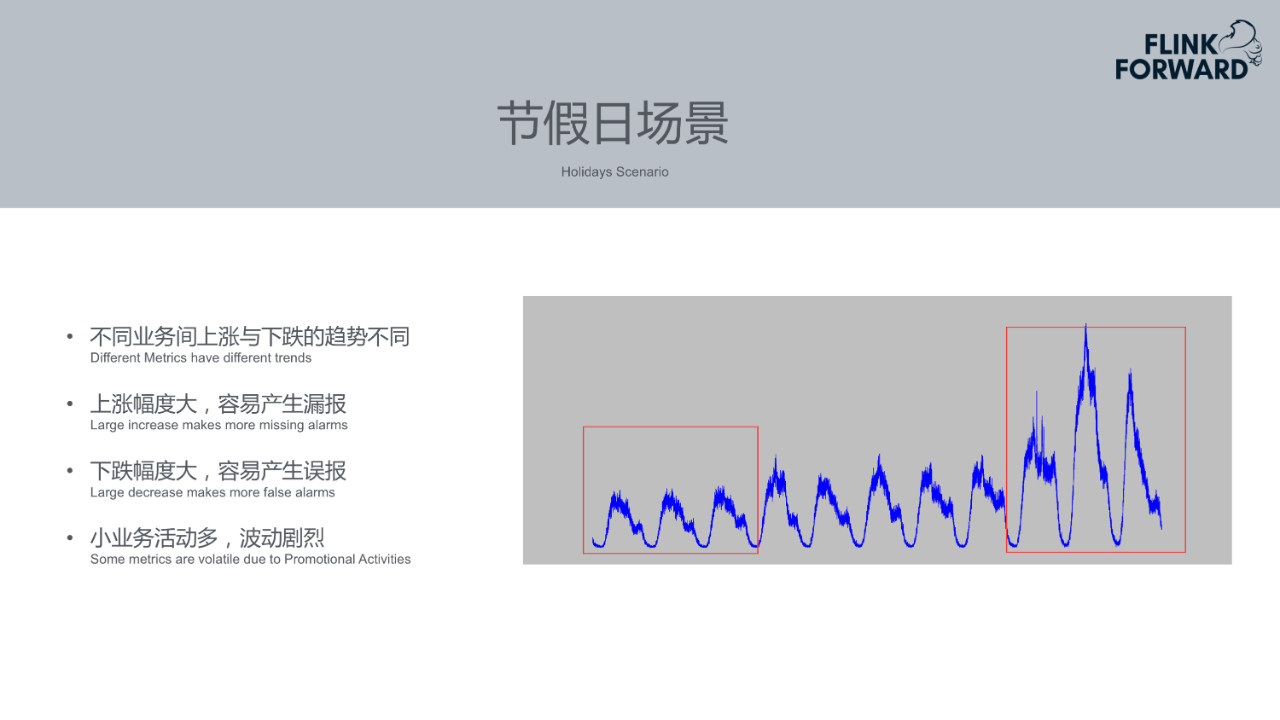
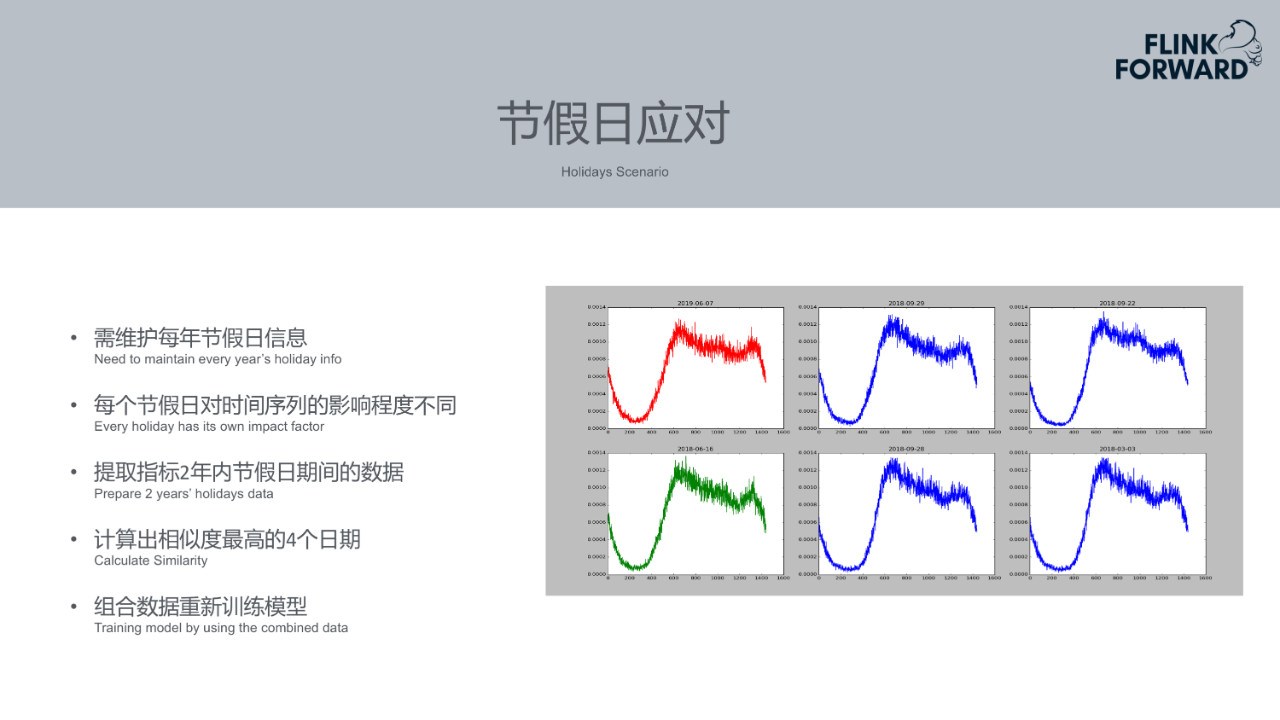
9.节假日场景
由于携程做旅游方向的业务,节假日期间问题较为突出。不同类型的业务在节假日的表现是不同的。例如携程的机票、火车票基本是在节前上升到一定量,到假期期间由于人们出游,该买的票已经购买完成,机票等业务订单量会下降很多。而酒店等业务在节假期间会上升很多。不同类型业务的趋势不同,上升幅度较大的业务容易产生漏报,对于下跌幅度较大的业务,容易产生误报。
节假日应对手段:不同的场景会导致不同的问题,所以Prophet针对节假日场景做了一些特殊处理。首先,维护每年节假日信息表,程序一旦发现下一个节假日还有一个星期时,Prophet就会提取出过去两年内的不同节假日期间的数据。然后计算前两年的不同节假日和当前节假日数值的相似度来匹配。相当于以当前节假日的数据拟合过去节假日的数据,拟合到某个时间段时,就知道大概从某个时间开始到某个时间结束是和当前趋势类似的。然后会用过去多个节假日的数据作为一个组合作为新模型的数据输入去训练数据集。不同节假日的占比不同,通过一些方式计算出不同占比值。最终相基于组合的数据集训练出新的模型,新的模型可以比较好地预测出某一个指标或者某一个业务在节假期七天之内的趋势。
10.平台现状
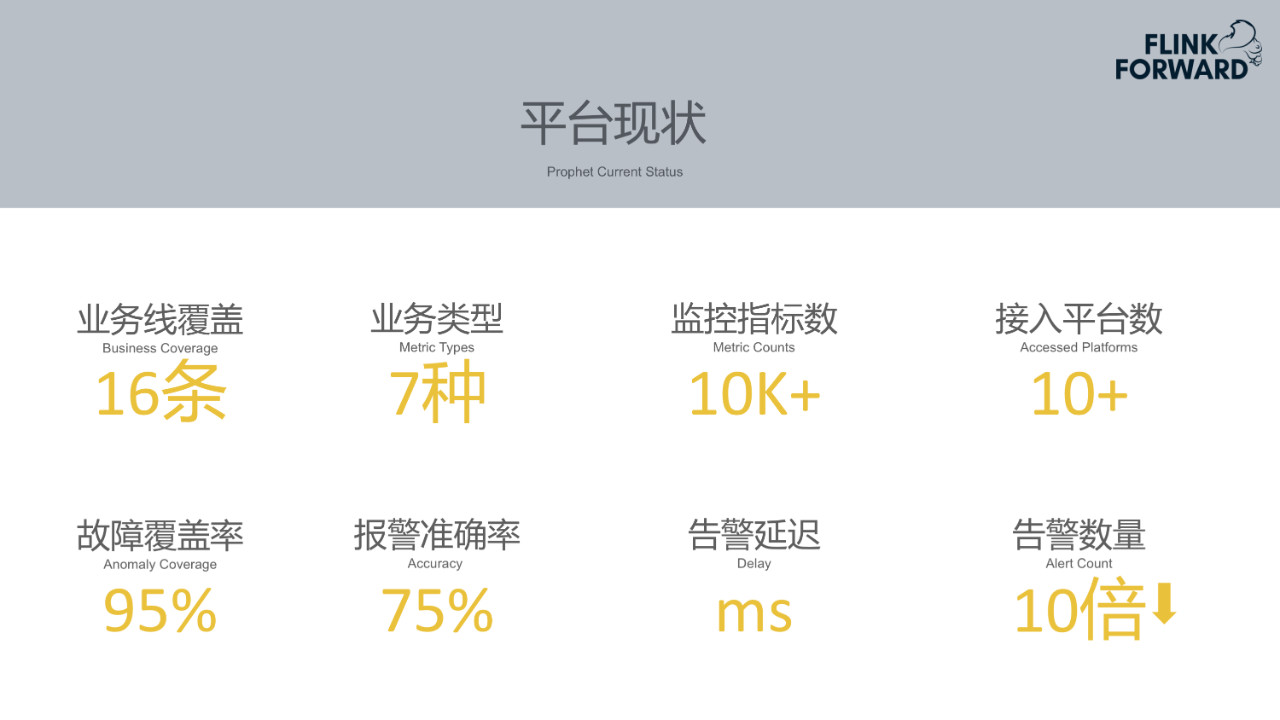
Prophet基本覆盖了携程所有业务线。即携程的重要业务指标基本都已经在使用监控智能告警。业务类型包含7种。监控指标的数量达到10K+,覆盖了携程所有订单、支付等重要的业务指标,覆盖了大部分服务的重要的业务指标。接入平台在10+左右,基本接入了携程公司所有系统级别的监控平台,在陆续接入各个业务部门自己的监控平台。Prophet平台能够覆盖95%左右的异常,准确报警率达到75%。因为每个数据同步到Prophet便触发数据实时消费、预测以及告警,告警延迟达到ms级别。告警数量也下降了十倍左右。
四、挑战与展望
1.挑战
- 资源消耗大:如果采用LSTM模型,需要为每个指标训练模型,单个Flink作业里面都加载了约4K~5K的模型,无论训练资源还是实时处理资源消耗都相对较大。
- 节假日影响:由于在业务指标在不同节假日的趋势不同,告警准确性受到一定程度的影响。
- 智能告警无法适用于全部场景:有些机器的CPU的使用率可以直接设定阈值,达到95%时告警,非常方便简单。但是如果用智能告警的方式拟合其趋势,意义不大。另外节假日大促时,会发放门票、酒店优惠券等活动,其订单量可能快速增长10倍到100倍。这种突发的快速增长在历史数据也很难学习到。上述场景的数据智能告警比较难处理。

2.展望
针对上述问题,Prophet正陆续进行改进,希望通过下面几种方式解决遇到的挑战。
- 通用模型迫在眉睫:Prophet目前训练了一个DNN模型,可以处理所有监控指标。DNN模型的准确率可能相较于LSTM模型会低一点,但能够涵盖较多场景。所以针对订单、支付等重要的业务指标,可以使用LSTM算法模型,保证准确性,但对于相对不太重要的业务指标,可以使用DNN通用模型。
- 节假日算法上线:Prophet节假日算法已经在线上验证半年,基本可以保证其准确性。
- 覆盖携程全部监控平台:Prophet已经覆盖了携程70%~80%的监控平台。大部分业务指标是在公司的系统监控级别,所以只要能覆盖公司级别的监控系统,就可以覆盖大部分重要的业务指标。后续,Prophet也将陆续接入更多业务部门的监控平台。
本文作者:潘国庆
本文为阿里云内容,未经允许不得转载。

