
State Processor API:如何读取,写入和修改 Flink 应用程序的状态
过去无论您是在生产中使用,还是调研Apache Flink,估计您总是会问这样一个问题:我该如何访问和更新Flink保存点(savepoint)中保存的state?不用再询问了,Apache Flink 1.9.0引入了状态处理器(State Processor)API,它是基于DataSet API的强大扩展,允许读取,写入和修改Flink的保存点和检查点(checkpoint)中的状态。
在这篇文章中,我们将解释为什么此功能对Flink来说很重要,以及该功能的用途和用法。最后,我们将讨论状态处理器API的未来规划,以保持与Flink批流统一的未来整体规划一致。
截止到Apache Flink 1.9的状态流处理现状
几乎所有复杂的流处理应用程序都是有状态的,其中大多数都是设计为运行数月甚至数年。随着时间的推移,这些作业积累了很多有价值的状态,如果由于故障而丢失,这些状态的重建将变得代价很高甚至是不可能的。为了保证应用程序状态的一致性和持久性,Flink从一开始就设计了一套复杂巧妙的检查点和恢复机制。在每一个版本中,Flink社区都添加了越来越多与状态相关的特性,以提高检查点执行和恢复的速度、改进应用程序的维护和管理。
然而,Flink用户经常会提出能够“从外部”访问应用程序的状态的需求。这个需求的动机可能是验证或调试应用程序的状态,或者将应用程序的状态迁移到另一个应用程序,或者从外部系统(例如关系数据库)导入应用程序的初始状态。
尽管这些需求的出发点都是合理的,但到目前为止从外部访问应用程序的状态这一功能仍然相当有限。Flink的可查询状态(queryable state)功能只支持基于键的查找(点查询),且不保证返回值的一致性(在应用程序发生故障恢复前后,返回值可能不同),并且可查询状态只支持读取并不支持修改和写入。此外,状态的一致性快照:保存点,也是无法访问的,因为这是使用自定义二进制格式进行编码的。
使用状态处理器(State Processor)API对应用程序状态进行读写
Flink1.9引入的状态处理器API,真正改变了这一现状,实现了对应用程序状态的操作。该功能借助DataSet API,扩展了输入和输出格式以读写保存点或检查点数据。由于DataSet和Table API的互通性,用户甚至可以使用关系表API或SQL查询来分析和处理状态数据。
例如,用户可以创建正在运行的流处理应用程序的保存点,并使用批处理程序对其进行分析,以验证该应用程序的行为是否正确。 或者,用户也可以任意读取、处理、并写入数据到保存点中,将其用于流计算应用程序的初始状态。 同时,现在也支持修复保存点中状态不一致的条目。最后,状态处理器API开辟了许多方法来开发有状态的应用程序,以绕过以前为了保证可以正常恢复而做的诸多限制:用户现在可以任意修改状态的数据类型,调整运算符的最大并行度,拆分或合并运算符状态,重新分配运算符UID等等。
将应用程序与数据集进行映射
状态处理器API将流应用程序的状态映射到一个或多个可以分别处理的数据集。为了能够使用API,您需要了解此映射的工作方式。
首先,让我们看看有状态的Flink作业是什么样的。Flink作业由算子(operator)组成,通常是一个或多个source算子,一些进行数据处理的算子以及一个或多个sink算子。每个算子在一个或多个任务中并行运行,并且可以使用不同类型的状态:可以具有零个,一个或多个列表形式的operator states,他们的作用域范围是当前算子实例;如果这些算子应用于键控流(keyed stream),它还可以具有零个,一个或多个keyed states,它们的作用域范围是从每个处理记录中提取的键。您可以将keyed states视为分布式键-值映射。
下图显示的应用程序“MyApp”,由称为“Src”,“Proc”和“Snk”的三个算子组成。Src具有一个operator state(os1),Proc具有一个operator state(os2)和两个keyed state(ks1,ks2),而Snk则是无状态的。

MyApp的保存点或检查点均由所有状态的数据组成,这些数据的组织方式可以恢复每个任务的状态。在使用批处理作业处理保存点(或检查点)的数据时,我们脑海中需要将每个任务状态的数据映射到数据集或表中。因为实际上,我们可以将保存点视为数据库。每个算子(由其UID标识)代表一个名称空间。算子的每个operator state都射到名称空间中的一个单列专用表,该列保存所有任务的状态数据。operator的所有keyed state都映射到一个键值多列表,该表由一列key和与每个key state映射的一列值组成。下图显示了MyApp的保存点如何映射到数据库
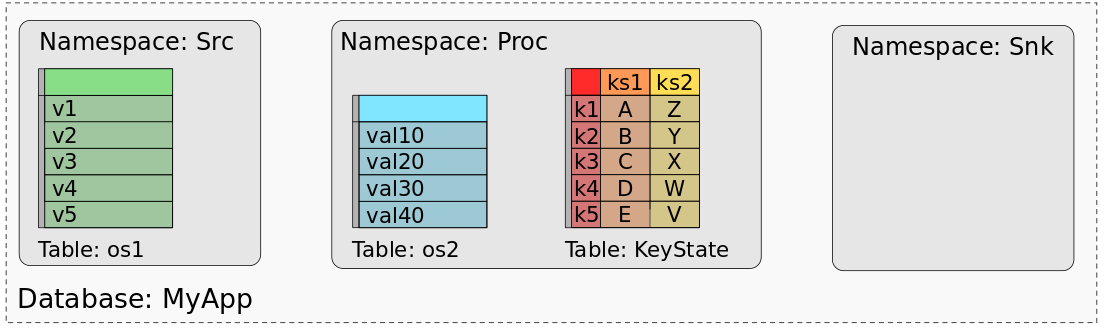
该图显示了"Src"的operator state的值如何映射到具有一列和五行的表,一行数据代表对于Src的所有并行任务中的一个并行实例。类似地,"Proc"的operator state os2,也映射到单个表。对于keyed state,ks1和ks2则是被组合到具有三列的单个表中,一列代表主键,一列代表ks1,一列代表ks2。该表为两个keyed state的每个不同key都保有一行。由于“Snk”没有任何状态,因此其映射表为空。
状态处理器API提供了创建,加载和编写保存点的方法。用户可以从已加载的保存点读取数据集,也可以将数据集转换为状态并将其添加到保存点中。总之,可以使用DataSet API的全部功能集来处理这些数据集。使用这些方法,可以解决所有前面提到的用例(以及更多用例)。如果您想详细了解如何使用状态处理器API,请查看文档。
为什么使用DataSet API?
如果您熟悉Flink的未来规划,可能会对状态处理器API基于DataSet API而感到惊讶,因为目前Flink社区计划使用BoundedStreams的概念扩展DataStream API,并弃用DataSet API。但是在设计此状态处理器功能时,我们还评估了DataStream API以及Table API,他们都不能提供相应的功能支持。由于不想此功能的开发因此受到阻碍,我们决定先在DataSet API上构建该功能,并将其对DataSet API的依赖性降到最低。基于此,将其迁移到另一个API应该是相当容易的。
总结
Flink用户很长时间以来有从外部访问和修改流应用程序的状态的需求,借助于状态处理器API,Flink为用户如何维护和管理流应用程序打开了许多新可能性,包括流应用程序的任意演变以及应用程序状态的导出和引导。简而言之,状态处理器API得保存点不再是一个黑匣子。
本文作者:巴蜀真人
本文为阿里云内容,未经允许不得转载。

