基于MaxCompute InformationSchema进行血缘关系分析
一、需求场景分析
在实际的数据平台运营管理过程中,数据表的规模往往随着更多业务数据的接入以及数据应用的建设而逐渐增长到非常大的规模,数据管理人员往往希望能够利用元数据的分析来更好地掌握不同数据表的血缘关系,从而分析出数据的上下游依赖关系。
本文将介绍如何去根据MaxCompute InformationSchema中作业ID的输入输出表来分析出某张表的血缘关系。
二、方案设计思路
MaxCompute Information_Schema提供了访问表的作业明细数据tasks_history,该表中有作业ID、input_tables、output_tables字段记录表的上下游依赖关系。根据这三个字段统计分析出表的血缘关系
1、根据某1天的作业历史,通过获取tasks_history表里的input_tables、output_tables、作业ID字段的详细信息,然后分析统计一定时间内的各个表的上下游依赖关系。
2、根据表上下游依赖推测出血缘关系。
三、方案实现方法
参考示例一:
(1)根据作业ID查询某表上下游依赖SQL处理如下:

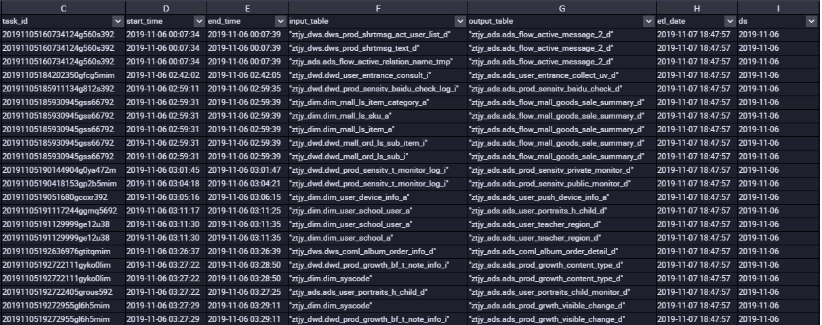
结果如下图所示:

(2)根据结果可以分析得出每张表张表的输入表输出表以及连接的作业ID,即每张表的血缘关系。
血缘关系位图如下图所示:

中间连线为作业ID,连线起始为输入表,箭头所指方向为输出表。
参考示例二:
以下方式是通过设置分区,结合DataWorks去分析血缘关系:
(1)设计存储结果表Schema

(2)关键解析sql

(3)任务依赖关系


(4)最终血缘关系
以上血缘关系的分析是根据自己的思路实践去完成。真实的业务场景需要大家一起去验证。所以希望大家有需要的可以根据自己的业务需求去做相应的sql修改。如果有发现处理不当的地方希望多多指教。我在做相应的调整。
本文作者:刘-建伟
本文为阿里云内容,未经允许不得转载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号