基于MaxCompute InformationSchema进行冷门表热门表访问分析
一、需求场景分析
在实际的数据平台运营管理过程中,数据表的规模往往随着更多业务数据的接入以及数据应用的建设而逐渐增长到非常大的规模,数据管理人员往往希望能够利用元数据的分析来更好地掌握不同数据表的使用情况,从而优化数据模型。
一个MaxCompute项目中经常使用的表简称为热门表,使用次数较少或者很长时间不使用的表简称为冷门表,本文将介绍如何去通过MaxCompute元数据信息去分析热门表和冷门表。
二、方案设计思路
MaxCompute Information_Schema提供了项目中全量的表元数据信息Tables以及包含访问表的作业明细数据tasks_history,通过汇总各个表被作业访问的次数可以获知不同表被作业使用的频度。
详细步骤如下:
1、热门数据通过获取tasks_history表里的input_tables字段的详细信息,然后通过count统计一定时间分区内的各个表使用次数
2、冷门数据通过tables和tasks_history里的input_tables表的作业汇总数量进行关联、排序,从而统计出各张表在规定时间内的使用次数,正序排列
三、方案实现方法
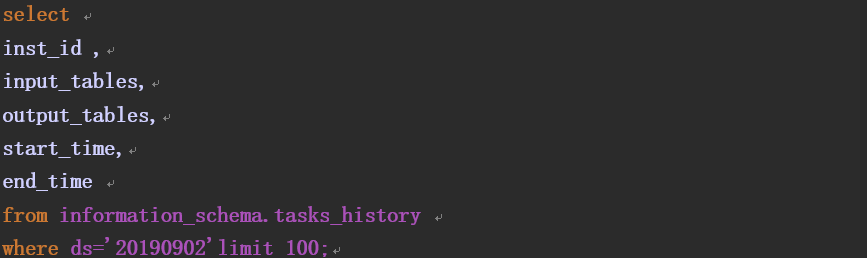
1、获取tasks_history表里的input_tables字段的详细信息。如下图所示:
查询数据的结果如下图所示:
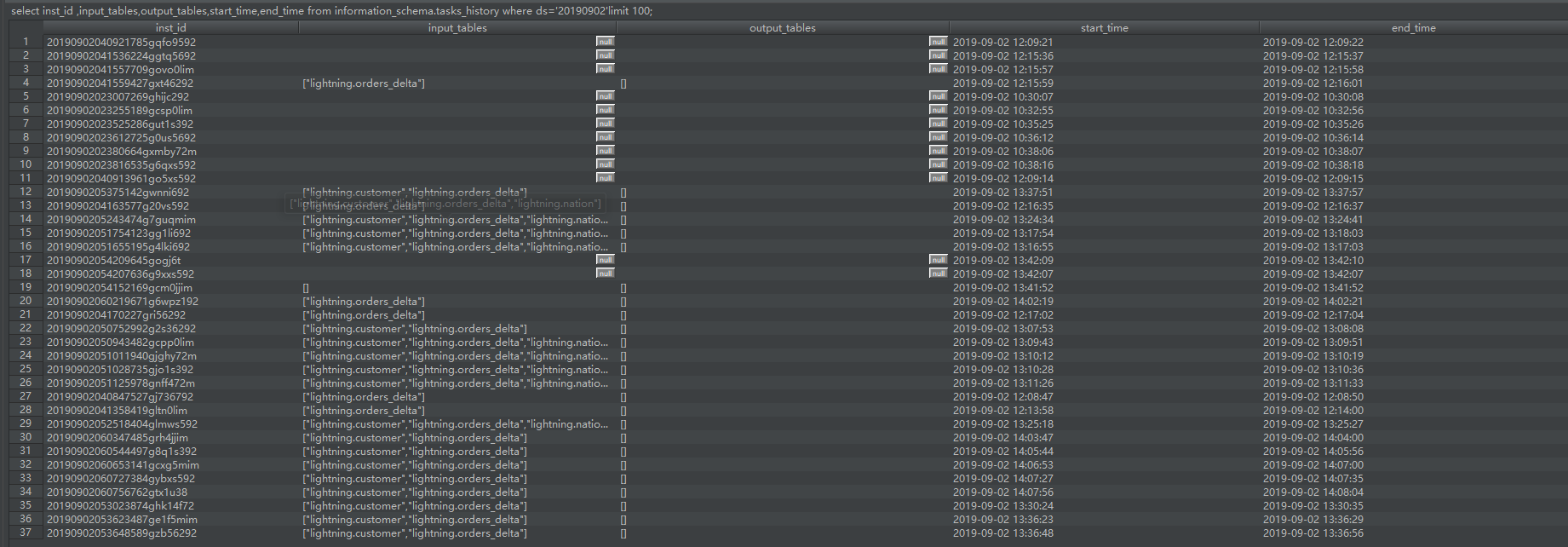
发现在tasks_history表中input_tables字段格式为
["lightning.customer","lightning.orders_delta"]
所以在统计的时候需要对字段进行按逗号分割
注意:案例中的时间分区可以根据需求去调整范围,区间根据实际场景去做相应的调整
例如:Ds>='20190902' and Ds<='20190905'
函数处理如下:

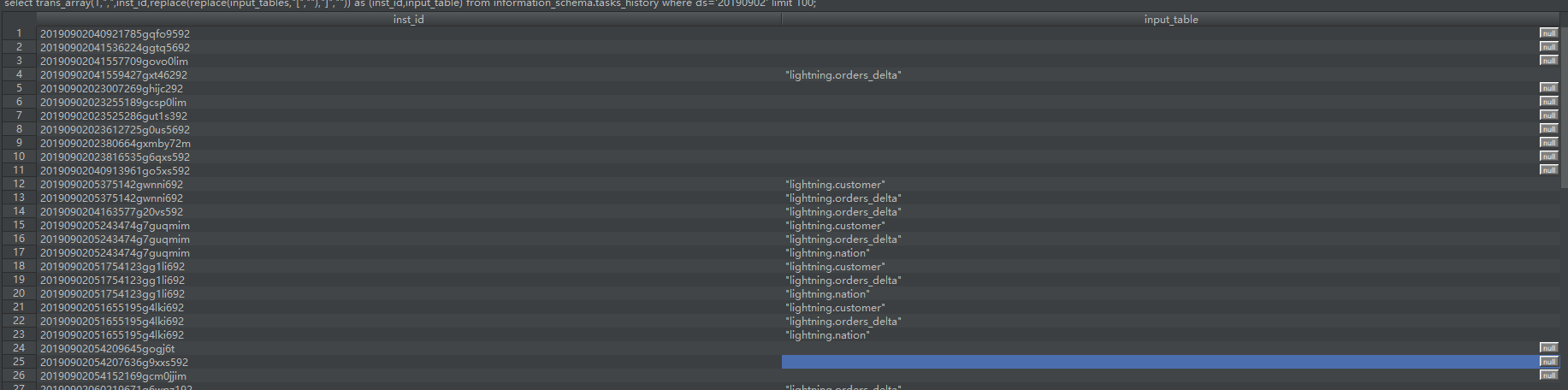
处理结果如下图:
2、统计热门表数据SQL编写:

结果如下图所示:

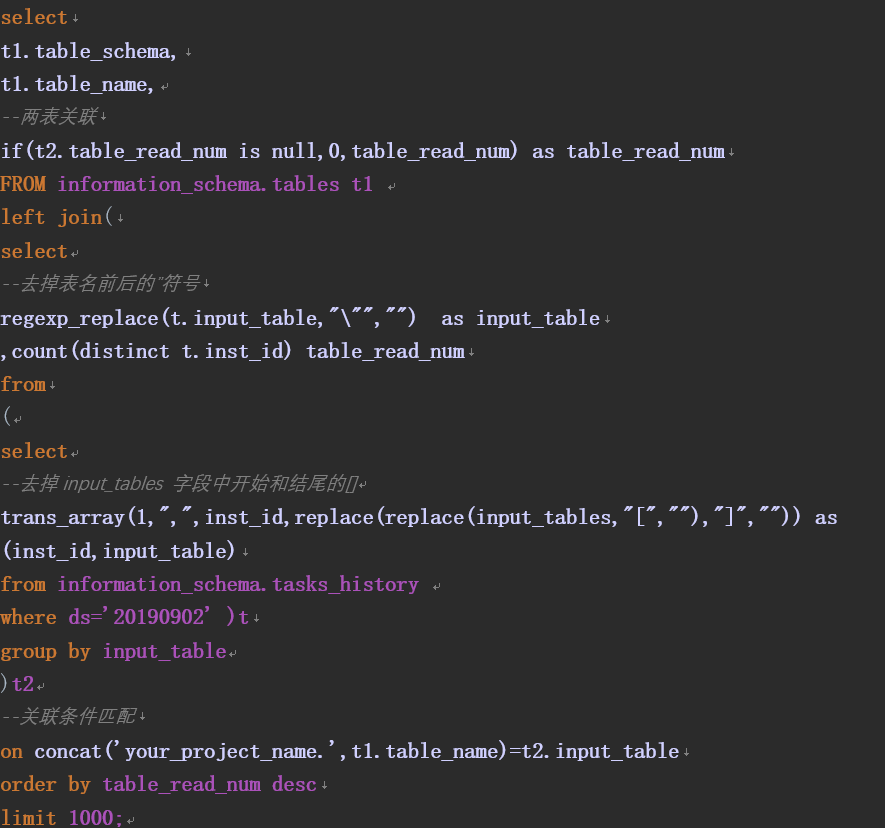
3、统计冷门表数据SQL编写:
通过tables和tasks_history里的input_tables表的作业汇总数量进行关联、排序,从而统计出各张表在规定时间内的使用次数,正序排列。
结果如下所示:


所有的表按照使用次数进行排序
即可得到各个表的使用次数排序信息。从而去进行合理化的管理数据表。
注意:SQL中的” your_project_name.”为表名前缀,客户需要参照自己的实际数据去做相应的修改调整。
本文作者:刘-建伟
本文为云栖社区原创内容,未经允许不得转载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号