Flink State 有可能代替数据库吗?
有状态的计算作为容错以及数据一致性的保证,是当今实时计算必不可少的特性之一,流行的实时计算引擎包括 Google Dataflow、Flink、Spark (Structure) Streaming、Kafka Streams 都分别提供对内置 State 的支持。State 的引入使得实时应用可以不依赖外部数据库来存储元数据及中间数据,部分情况下甚至可以直接用 State 存储结果数据,这让业界不禁思考: State 和 Database 是何种关系?有没有可能用 State 来代替数据库呢?
在这个课题上,Flink 社区是比较早就开始探索的。总体来说,Flink 社区的努力可以分为两条线: 一是在作业运行时通过作业查询接口访问 State 的能力,即 QueryableState;二是通过 State 的离线 dump 文件(Savepoint)来离线查询和修改 State 的能力,即即将引入的 Savepoint Processor API。
QueryableState
在 2017 年发布的 Flink 1.2 版本,Flink 引入了 QueryableState 的特性以允许用户通过特定的 client 查询作业 State 的内容 [1],这意味着 Flink 应用可以在完全不依赖 State 存储介质以外的外部存储的情况下提供实时访问计算结果的能力。

只通过 Queryable State 提供实时数据访问
然而,QueryableState 虽然设想上比较理想化,但由于依赖底层架构的改动较多且功能也比较受限,它一直处于 Beta 版本并不能用于生产环境。针对这个问题,在前段时间腾讯的工程师杨华提出 QueryableState 的改进计划 [2]。在邮件列表中,社区就 QueryableState 是否可以用于代替数据库作了讨论并出现了不同的观点。笔者结合个人见解将 State as Database 的主要优缺点整理如下。
优点:
- 更低的数据延迟。一般情况下 Flink 应用的计算结果需要同步到外部的数据库,比如定时触发输出窗口计算结果,而这种同步通常是定时的会带来一定的延迟,导致计算是实时的而查询却不是实时的尴尬局面,而直接 State 则可以避免这个问题。
- 更强的数据一致性保证。根据外部存储的特性不同,Flink Connector 或者自定义的 SinkFunction 提供的一致性保障也有所差别。比如对于不支持多行事务的 HBase,Flink 只能通过业务逻辑的幂等性来保障 Exactly-Once 投递。相比之下 State 则有妥妥的 Exactly-Once 投递保证。
- 节省资源。因为减少了同步数据到外部存储的需要,我们可以节省序列化和网络传输的成本,另外当然还可以节省数据库成本。
缺点:
- SLA 保障不足。数据库技术已经非常成熟,在可用性、容错性和运维上都很多的积累,在这点上 State 还相当于是处于原始人时期。另外从定位上来看,Flink 作业有版本迭代维护或者遇到错误自动重启带来的 down time,并不能达到数据库在数据访问上的高可用性。
- 可能导致作业的不稳定。未经过考虑的 Ad-hoc Query 可能会要求扫描并返回夸张量级的数据,这会系统带来很大的负荷,很可能影响作业的正常执行。即使是合理的 Query,在并发数较多的情况下也可能影响作业的执行效率。
- 存储数据量不能太大。State 运行时主要存储在 TaskManager 本地内存和磁盘,State 过大会造成 TaskManager OOM 或者磁盘空间不足。另外 State 大意味着 checkpoint 大,导致 checkpoint 可能会超时并显著延长作业恢复时长。
- 只支持最基础的查询。State 只能进行最简单的数据结构查询,不能像关系型数据库一样提供函数等计算能力,也不支持谓词下推等优化技术。
- 只可以读取,不能修改。State 在运行时只可以被作业本身修改,如果实在要修改 State 只能通过下文的 Savepoint Processor API 来实现。
总体来说,目前 State 代替数据库的缺点还是远多于其优点,不过对于某些对数据可用性要求不高的作业来说,使用 State 作为数据库还是完全合理的。由于定位上的不同,Flink State 在短时间内很难看到可以完全替代数据库的可能性,但在数据访问特性上 State 往数据库方向发展是无需质疑的。
Savepoint Processor API
Savepoint Processor API 是社区最近提出的一个新特性(见 FLIP-42 [3]),用于离线对 State 的 dump 文件 Savepoint 进行分析、修改或者直接根据数据构建出一个初始的 Savepoint。Savepoint Processor API 属于 Flink State Evolution 的 State Management。如果说 QueryableState 是 DSL 的话,Flink State Evolution 就是 DML,而 Savepoint Processor API 就是 DML 中最为重要的部分。
Savepoint Processor API 的前身是第三方的 Bravo 项目 [4],主要思路提供 Savepoint 和 DataSet 相互转换的能力,典型应用是 Savepoint 读取成 DataSet,在 DataSet 上进行修改,然后再写为一个新的 Savepoint。这适合用于以下的场景:
- 分析作业 State 以研究其模式和规律
- 排查问题或者审计
- 为新的应用构建的初始 State
-
修改 Savepoint,比如:
- 改变作业最大并行度
- 进行巨大的 Schema 改动
- 修正有问题的 State
Savepoint 作为 State 的 dump 文件,通过 Savepoint Processor API 可以暴露数据查询和修改功能,类似于一个离线的数据库,但 State 的概念和典型关系型数据的概念还是有很多不同,FLIP-43 也对这些差异进行了类比和总结。
首先 Savepoint 是多个 operator 的 state 的物理存储集合,不同 operator 的 state 是独立的,这类似于数据库下不同 namespace 之间的 table。我们可以得到 Savepoint 对应数据库,单个 operator 对应 Namespace。

但就 table 而言,其在 Savepoint 里对应的概念根据 State 类型的不同而有所差别。State 有 Operator State、Keyed State 和 Broadcast State 三种,其中 Operator State 和 Broadcast State 属于 non-partitioned state,即没有按 key 分区的 state,而相反地 Keyed State 则属于 partitioned state。对于 non-partitioned state 来说,state 是一个 table,state 的每个元素即是 table 里的一行;而对于 partitioned state 来说,同一个 operator 下的所有 state 对应一个 table。这个 table 像是 HBase 一样有个 row key,然后每个具体的 state 对应 table 里的一个 column。
举个例子,假设有一个游戏玩家得分和在线时长的数据流,我们需要用 Keyed State 来记录玩家所在组的分数和游戏时长,用 Operator State 记录玩家的总得分和总时长。
在一段时间内数据流的输入如下:
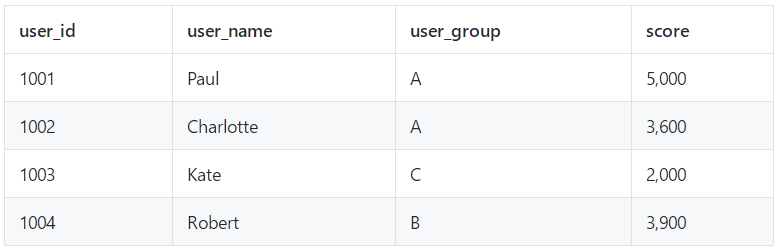

用 Keyed State ,我们分别注册 group_score 和 group_time 两个 MapState 表示组总得分和组总时长,并根据 user_group keyby 数据流之后将两个指标的累积值更新到 State 里,得到的表如下:

相对地,假如用 Operator State 来记录总得分和总时长(并行度设为 1),我们注册 total_score 和 total_time 两个 State,得到的表有两个:


至此 Savepoint 和 Database 的对应关系应该是比较清晰明了的。而对于 Savepoint 来说还有不同的 StateBackend 来决定 State 具体如何持续化,这显然对应的是数据库的存储引擎。在 MySQL 中,我们可以通过简单的一行命令 ALTER TABLE xxx ENGINE = InnoDB; 来改变存储引擎,在背后 MySQL 会自动完成繁琐的格式转换工作。而对于 Savepoint 来说,由于 StateBackend 各自的存储格式不兼容,目前尚不能方便地切换 StateBackend。为此,社区在不久前创建 FLIP-41 [5] 来进一步完善 Savepoint 的可操作性。
总结
State as Database 是实时计算发展的大趋势,它并不是要代替数据库的使用,而是借鉴数据库领域的经验拓展 State 接口使其操作方式更接近我们熟悉的数据库。对于 Flink 而言,State 的外部使用可以分为在线的实时访问和离线的访问和修改,分别将由 Queryable State 和 Savepoint Processor API 两个特性支持。
参考文献
- Queryable State in Apache Flink® 1.2.0: An Overview & Demo
- Improve Queryable State and Introduce a QueryServerProxy Component
- FLIP-43: Savepoint Processor API
- Bravo: Utilities for processing Flink checkpoints/savepoints
- FLIP-41: Unify Keyed State Snapshot Binary Format for Savepoints
作者介绍:林小铂,网易游戏高级开发工程师,负责游戏数据中心实时平台的开发及运维工作,目前专注于 Apache Flink 的开发及应用。探究问题本来就是一种乐趣。
本文作者:林小铂
本文为云栖社区原创内容,未经允许不得转载。
