
阿里巴巴 Kubernetes 应用管理实践中的经验与教训
导读:云原生时代,Kubernetes 的重要性日益凸显。然而,大多数互联网公司在 Kubernetes 上的探索并非想象中顺利,Kubernetes 自带的复杂性足以让一批开发者望而却步。本文中,阿里巴巴技术专家孙健波在接受采访时基于阿里巴巴 Kubernetes 应用管理实践过程提供了一些经验与建议,以期对开发者有所帮助。
在互联网时代,开发者更多是通过顶层架构设计,比如多集群部署和分布式架构的方式来实现出现资源相关问题时的快速切换,做了很多事情来让弹性变得更加简单,并通过混部计算任务来提高资源利用率,云计算的出现则解决了从 CAPEX 到 OPEX 的转变问题。
云计算时代让开发可以聚焦在应用价值本身,相较于以前开发者除了业务模块还要投入大量精力在存储、网络等基础设施,如今这些基础设施都已经像水电煤一样便捷易用。云计算的基础设施具有稳定、高可用、弹性伸缩等一系列能力,除此之外还配套解决了一系列应用开发“最佳实践”的问题,比如监控、审计、日志分析、灰度发布等。原来,一个工程师需要非常全面才能做好一个高可靠的应用,现在只要了解足够多的基础设施产品,这些最佳实践就可以信手拈来了。但是,在面对天然复杂的 Kubernetes 时,很多开发者都无能为力。
作为 Jira 和代码库 Bitbucket 背后的公司,Atlassian 的 Kubernetes 团队首席工程师 Nick Young 在采访中表示:
虽然当初选择 Kubernetes 的战略是正确的(至少到现在也没有发现其他可能的选择),解决了现阶段遇到的许多问题,但部署过程异常艰辛。
那么,有好的解决办法吗?
太过复杂的 Kubernetes
“如果让我说 Kubernetes 存在的问题,当然是‘太复杂了’”,孙健波在采访中说道,“不过,这其实是由于 Kubernetes 本身的定位导致的。”
孙健波补充道,Kubernetes 的定位是“platform for platform”。它的直接用户,既不是应用开发者,也不是应用运维,而是“platform builder”,也就是基础设施或者平台级工程师。但是,长期以来,我们对 Kubernetes 项目很多时候都在错位使用,大量的应用运维人员、甚至应用研发都在直接围绕 Kubernetes 很底层的 API 进行协作,这是导致很多人抱怨 “Kubernetes 实在是太复杂了”的根本原因之一。
这就好比一名 Java Web 工程师必须直接使用 Linux Kernel 系统调用来部署和管理业务代码,自然会觉得 Linux “太反人类了”。所以,目前 Kubernetes 项目实际上欠缺一层更高层次的封装,来使得这个项目能够对上层的软件研发和运维人员更加友好。
如果可以理解上述的定位,那么 Kubernetes 将 API 对象设计成 all-in-one 是合理的,这就好比 Linux Kernel 的 API,也不需要区分使用者是谁。但是,当开发者真正要基于 K8s 管理应用、并对接研发、运维工程师时,就必然要考虑这个问题,也必然要考虑如何做到像另一层 Linux Kernel API 那样以标准、统一的方式解决这个问题,这也是阿里云和微软联合开放云原生应用模型 Open Application Model (OAM)的原因。
有状态应用支持
除了天然的复杂性问题,Kubernetes 对于有状态应用的支持也一直是众多开发者花费大量时间研究和解决的问题,并不是不可以支持,只是没有相对较优的解决方案。目前,业内主流的针对有状态应用的解法是 Operator,但是编写 Operator 其实是很困难的。
在采访中,孙健波表示,这是因为 Operator 本质上是一个“高级版”的 K8s 客户端,但是 K8s API Server 的设计,是“重客户端”的模型,这当然是为了简化 API Server 本身的复杂度,但也导致了无论是 K8s client 库,还是以此为基础的 Operator,都变的异常复杂和难以理解:它们都夹杂了大量 K8s 本身的实现细节,比如 reflector、cache store、informer 等。这些,并不应该是 Operator 编写者需要关心的,Operator 编写者应该是有状态应用本身的领域专家(比如 TiDB 的工程师),而不应该是 K8s 专家。这是现在 K8s 有状态应用管理最大的痛点,而这可能需要一个新的 Operator 框架来解决这个问题。
另一方面,复杂应用的支持不止编写 Operator 这么简单,这里还需要有状态应用交付的技术支撑,这是目前社区上各种持续交付项目都有意或者无意间忽略掉的事情。事实上,持续交付一个基于 Operator 的有状态应用,跟交付一个无状态的 K8s Deployment 的技术挑战完全不是一个量级的。这也是孙健波所在团队在 CNCF 应用交付领域小组(CNCF SIG App Deliver)倡导“应用交付分层模型”的重要原因:如下图所示,四层模型分别为“应用定义”、“应用交付”、“应用运维与自动化”、“平台层”,只有通过这四个层不同能力的合力协作,才能真正做到高质量和高效率的交付有状态应用。
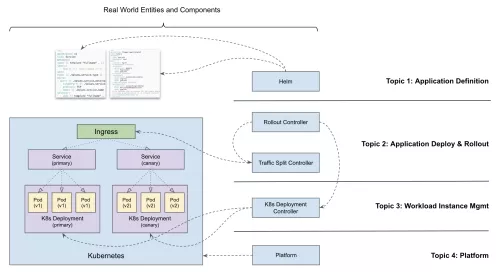
举个例子,Kubernetes API 对象的设计是“all-in-one”的, 即:应用管理过程中的所有参与者,都必须在同一个 API 对象上进行协作。这就导致开发者会看到,像 K8s Deployment 这样的 API 对象描述里, 既有应用开发关注的字段,也可以看到运维关注的字段,还有一些字段可能还是被多方关注的。
实际上,无论是应用开发、应用运维,还是 HPA 这样的 K8s 自动化能力,它们都有可能需要控制一个 API 对象里的同一个字段。最典型的情况就是副本数(replica)这种参数。但是,到底谁 own 这个字段,是一个非常棘手的问题。
综上,既然 K8s 的定位是云时代的 Linux Kernel,那么 Kubernetes 就必须在 Operator 支持、API 层以及各类接口定义的完善上不断进行突破,使得更多生态参与者可以更好的基于 K8s 构建自己的能力和价值。
阿里巴巴大规模 Kubernetes 实践
如今,Kubernetes 在阿里经济体的应用场景涵盖了阿里方方面面的业务,包括电商、物流、离在线计算等,这也是目前支撑阿里 618、双 11 等互联网级大促的主力军之一。阿里集团和蚂蚁金服内部运行了数十个超大规模的 K8s 集群,其中最大的集群约 1 万个机器节点,而且这其实还不是能力上限。每个集群都会服务上万个应用。在阿里云 Kubernetes 服务(ACK)上,我们还维护了上万个用户的 K8s 集群,这个规模和其中的技术挑战在全世界也是首屈一指的。
孙健波透露,阿里内部早在 2011 年便开始了应用容器化,当时最开始是基于 LXC 技术构建容器,随后开始用自研的容器技术和编排调度系统。整套系统本身没有什么问题,但是作为基础设施技术团队,目标一定是希望阿里的基础技术栈能够支撑更广泛的上层生态,能够不断演进和升级,因此,整个团队又花了一年多时间逐渐补齐了 K8s 的规模和性能短板。总体来看,升级为 K8s 是一个非常自然的过程,整个实践过程其实也很简单:
- 第一:解决应用容器化的问题,这里需要合理利用 K8s 的容器设计模式;
- 第二:解决应用定义与描述的问题,这里需要合理的利用 OAM,Helm 等应用定义工具和模型来实现,并且要能够对接现有的应用管理能力;
- 第三:构建完整的应用交付链,这里可以考虑使用和集成各种持续交付能力。
如上的三步完成,就具备了对接研发、运维、上层 PaaS 的能力,能够讲清楚自己的平台价值。接下来就可以试点开始,在不影响现有应用管理体系的前提下,一步步换掉下面的基础设施。
Kubernetes 本身并不提供完整的应用管理体系,这个体系是整个云原生的生态基于 K8s 构建出来的,可以用下图表示:
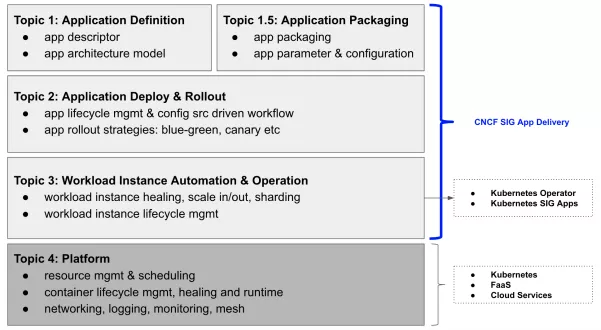
Helm 就是其中最成功的一个例子,它位于整个应用管理体系的最上面,也就是第 1 层,还有 Kustomize 等各种 YAML 管理工具,CNAB 等打包工具,它们都对应在第 1.5 层。然后有 Tekton、Flagger 、Kepton 等应用交付项目,对应在第 2 层。Operator ,以及 K8s 的各种工作负载组件,比如 Deployment、StatefulSet,对应在第 3 层。最后才是 K8s 的核心功能,负责对工作负载的容器进行管理,封装基础设施能力,对各种不同的工作负载对接底层基础设施提供 API 等。
初期,整个团队最大的挑战来自于规模和性能瓶颈,但这个解法也是最直接的。孙健波表示,随着规模逐渐增大,我们看到规模化铺开 K8s 最大的挑战实际上是如何基于 K8s 进行应用管理和对接上层生态。比如,我们需要统一的管控来自数十个团队、数百个不同目的的 Controller;我们需要以每天近万次的频率交付来自不同团队的生产级应用,这些应用的发布、扩容策略可能完全不同;我们还需要对接数十个更加复杂的上层平台,混合调度和部署不同形态的作业以追求最高的资源利用率,这些诉求才是阿里巴巴 Kubernetes 实践要解决的问题,规模和性能只是其中一个组成部分。
除了 Kubernetes 的原生功能外,在阿里巴巴内部会开发大量的基础设施以 K8s 插件的形式对接到这些功能上,随着规模的扩大,用统一的方式发现和管理这些能力成为了一个关键问题。
此外,阿里巴巴内部也有众多存量 PaaS,这些是为了满足用户不同业务场景上云所构建的,比如有的用户希望上传一个 Java 的 War 包就可以运行,有的用户希望上传一个镜像就可以运行。在这些需求背后,阿里各团队帮用户做了许多应用管理的工作,这也是存量 PaaS 出现的原因,而这些存量 PaaS 与 Kubernetes 对接过程可能会产生各种问题。目前,阿里正在通过 OAM 这个统一标准的应用管理模型,帮助这些 PaaS 向 K8s 底盘进行对接和靠拢,实现标准化和云原生化。
解耦运维和研发
通过解耦,Kubernetes 项目以及对应的云服务商就可以为不同的角色暴露不同维度、更符合对应用户诉求的声明式 API。比如,应用开发者只需要在 YAML 文件中声明”应用 A 要使用 5G 可读写空间“,应用运维人员则只需要在对应的 YAML 文件里声明”Pod A 要挂载 5G 的可读写数据卷“。这种”让用户只关心自己所关心的事情“所带来的专注力,是降低 Kubernetes 使用者学习门槛和上手难度的关键所在。
孙健波表示,现在大多数的解法实际上是“悲观处理”。比如,阿里内部的 PaaS 平台,为了减轻研发使用的负担,长期以来只开放给研发设置 5 个 Deployment 的字段。这当然是因为 K8s YAML "all-in-one"的设计,使得完整的 YAML 对研发来说太复杂,但这也导致 K8s 本身的能力,绝大多数情况下对研发来说是完全没有体感的。而对 PaaS 平台运维来说,他反而觉得 K8s YAML 太简单,不够描述平台的运维能力,所以要给 YAML 文件添加大量 annotation。
此外,这里的核心问题在于,对运维人员而言,这种“悲观处理”的结果就是他自己太“独裁”,包揽了大量细节工作,还费力不讨好。比如扩容策略,目前就是完全由运维一方说了算。可是,研发作为编写代码的实际人员,才是对应用怎么扩容最有发言权的,而且研发人员也非常希望把自己的意见告诉运维,好让 K8s 更加 灵活,真正满足扩容需求。但这个诉求在目前的系统里是无法实现的。
所以,“研发和运维解耦”并不是要把两者割裂,而是要给研发提供一个标准、高效的,同运维进行沟通的方式,这也是 OAM 应用管理模型要解决的问题。孙健波表示,OAM 的主要作用之一就是提供一套研发从自己的角度表达诉求的标准和规范,然后这套标准“你知,我知,系统知”,那么上面这些问题也就迎刃而解了。
具体来说,OAM 是一个专注于描述应用的标准规范。有了这个规范,应用描述就可以彻底与基础设施部署和管理应用的细节分开。这种关注点分离(Seperation of Conerns)的设计好处是非常明显的。举个例子,在实际生产环境中,无论是 Ingress、CNI 还是 Service Mesh,这些表面看起来一致的运维概念,在不同的 Kubernetes 集群中可谓千差万别。通过将应用定义与集群的运维能力分离,我们就可以让应用开发者更专注应用本身的价值点,而不是”应用部署在哪“这样的运维细节。
此外,关注点分离让平台架构师可以轻松地把平台运维能力封装成可被复用的组件,从而让应用开发者专注于将这些运维组件与代码进行集成,从而快速、轻松地构建可信赖的应用。OAM 的目标是让简单的应用管理变得更加轻松,让复杂的应用交付变得更加可控。孙健波表示,未来,团队将专注于将这套体系逐步向云端 ISV 和软件分发商侧推进,让基于 K8s 的应用管理体系真正成为云时代的主流。
嘉宾介绍:孙健波,阿里巴巴技术专家。Kubernetes 项目社区成员。目前在阿里巴巴参与大规模云原生应用交付与管理相关工作,2015 年参与编写《Docker 容器与容器云》技术书籍。曾任职七牛,参与过时序数据库、流式计算、日志平台等项目相关应用上云过程。
今年 12 月 6-7 日北京 ArchSummit 全球架构师峰会上,孙健波老师会继续分享《阿里巴巴 Kubernetes 应用管理实践中的经验与教训》,会介绍阿里对解耦研发和运维过程中的现有实践,以及实践本身存在的问题;以及实施的标准化、统一化解决的思路,以及对社区的进一步思考。
本文作者:孙健波、赵钰莹
本文为云栖社区原创内容,未经允许不得转载。
