
Kubernetes 弹性伸缩全场景解读(五) - 定时伸缩组件发布与开源

导读:Kubernetes弹性伸缩系列文章为读者一一解析了各个弹性伸缩组件的相关原理和用法。本篇文章中,阿里云容器技术专家莫源将为你带来定时伸缩组件 kubernetes-cronhpa-controller 的相关介绍与具体操作,目前该组件已经正式开源,欢迎大家一起交流探讨。
前言
容器技术的发展让软件交付和运维变得更加标准化、轻量化、自动化。这使得动态调整负载的容量变成一件非常简单的事情。在 Kubernetes 中,通常只需要修改对应的 replicas 数目即可完成。当负载的容量调整变得如此简单后,我们再回过头来看下应用的资源画像。
对于大部分互联网的在线应用而言,负载的峰谷分布是存在一定规律的。例如下图是一个典型 web 应用的负载曲线。从每天早上 8 点开始,负载开始飙高,在中午 12 点到 14 点之间,负载会回落;14 点到 18 点会迎来第二个高峰;在 18 点之后负载会逐渐回落到最低点。
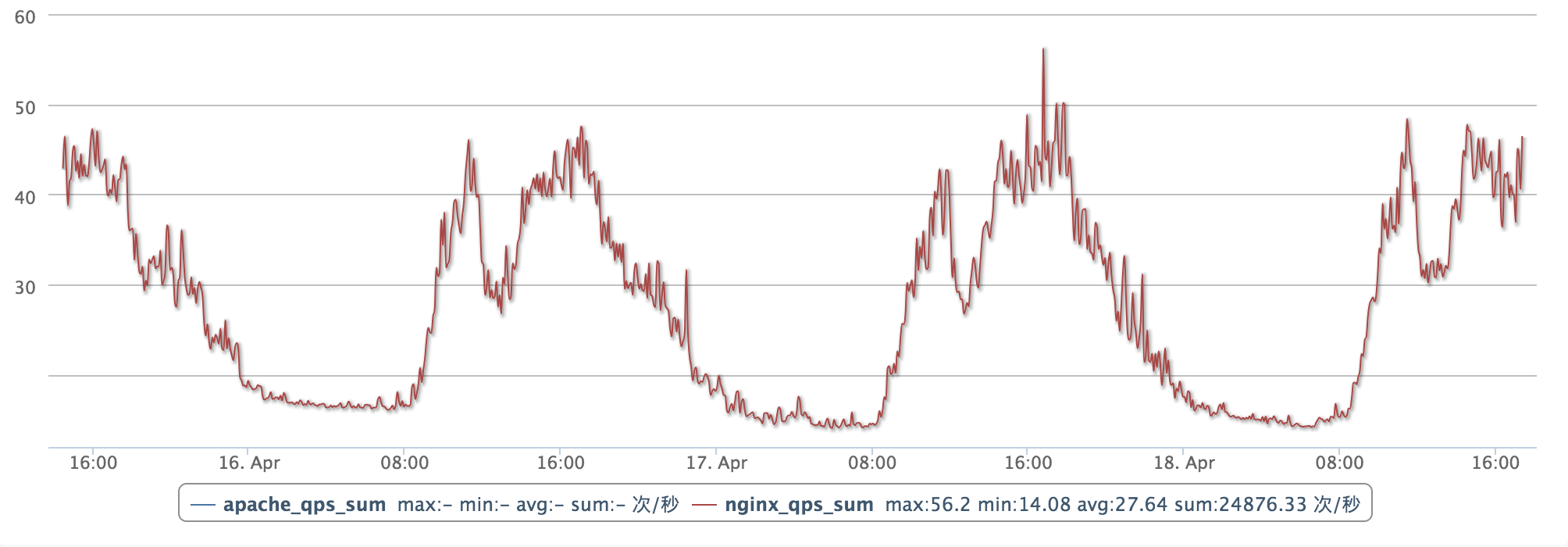
资源的波峰和波谷之间相差 3~4 倍左右的容量,低负载的时间会维持 8 个小时左右。如果使用纯静态的容量规划方式进行应用管理与部署,我们可以计算得出资源浪费比为 25% (计算方式: 1 - (18+416)/424 = 0.25 )。而当波峰和波谷之间的差别到达 10 倍的时候,资源浪费比就会飙升至 57% (计算方式: 1 - (18+1016)/1024 = 0.57 )。
那么当我们面对这么多的资源浪费时,是否可以通过弹性的方式来解决呢?
标准的 HPA 是基于指标阈值进行伸缩的,常见的指标主要是 CPU、内存,当然也可以通过自定义指标例如 QPS、连接数等进行伸缩。但是这里存在一个问题:基于资源的伸缩存在一定的时延,这个时延主要包含:采集时延(分钟级) + 判断时延(分钟级) + 伸缩时延(分钟级)。而对于上图中,我们可以发现负载的峰值毛刺还是非常尖锐的,这有可能会由于 HPA 分钟级别的伸缩时延造成负载数目无法及时变化,短时间内应用的整体负载飙高,响应时间变慢。特别是对于一些游戏业务而言,由于负载过高带来的业务抖动会造成玩家非常差的体验。
为了解决这个场景,阿里云容器服务提供了 kube-cronhpa-controller,专门应对资源画像存在周期性的场景。开发者可以根据资源画像的周期性规律,定义 time schedule,提前扩容好资源,而在波谷到来后定时回收资源。底层再结合 cluster-autoscaler 的节点伸缩能力,提供资源成本的节约。
使用方式
cronhpa 是基于 CRD 的方式开发的 controller,使用 cronhpa 的方式非常简单,整体的使用习惯也尽可能的和 HPA 保持一致。代码仓库地址
1. 安装 CRD
kubectl apply -f config/crds/autoscaling_v1beta1_cronhorizontalpodautoscaler.yaml
2. 安装 RBAC 授权
# create ClusterRole
kubectl apply -f config/rbac/rbac_role.yaml
# create ClusterRolebinding and ServiceAccount
kubectl apply -f config/rbac/rbac_role_binding.yaml3. 部署 kubernetes-cronhpa-controller
kubectl apply -f config/deploy/deploy.yaml4. 验证 kubernetes-cronhpa-controller 安装状态
kubectl get deploy kubernetes-cronhpa-controller -n kube-system -o wide
kubernetes-cronhpa-controller git:(master) kubectl get deploy kubernetes-cronhpa-controller -n kube-system
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
kubernetes-cronhpa-controller 1 1 1 1 49s运行一个 cronhpa 的 demo
安装了 kubernetes-cronhpa-controller 后,我们可以通过一个简单的 demo 进行功能的验证。在部署前,我们先看下一个标准的 cronhpa 的定义。
apiVersion: autoscaling.alibabacloud.com/v1beta1
kind: CronHorizontalPodAutoscaler
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: cronhpa-sample
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1beta2
kind: Deployment
name: nginx-deployment-basic
jobs:
- name: "scale-down"
schedule: "30 */1 * * * *"
targetSize: 1
- name: "scale-up"
schedule: "0 */1 * * * *"
targetSize: 3其中 scaleTargetRef 字段负责描述伸缩的对象,jobs 中定义了扩展的 crontab 定时任务。在这个例子中,设定的是每分钟的第 0 秒扩容到 3 个 Pod,每分钟的第 30s 缩容到 1 个 Pod。如果执行正常,我们可以在 30s 内看到负载数目的两次变化。
1. 部署 demo 应用与 cronhpa 的配置
kubectl apply -f examples/deployment_cronhpa.yaml2. 检查 demo 应用副本数目
kubectl get deploy nginx-deployment-basic
kubernetes-cronhpa-controller git:(master) kubectl get deploy nginx-deployment-basic
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment-basic 2 2 2 2 9s3. 查看 cronhpa 的状态 ,确认 cronhpa 的 job 已提交
kubectl describe cronhpa cronhpa-sample
Name: cronhpa-sample
Namespace: default
Labels: controller-tools.k8s.io=1.0
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"autoscaling.alibabacloud.com/v1beta1","kind":"CronHorizontalPodAutoscaler","metadata":{"annotations":{},"labels":{"controll...
API Version: autoscaling.alibabacloud.com/v1beta1
Kind: CronHorizontalPodAutoscaler
Metadata:
Creation Timestamp: 2019-04-14T10:42:38Z
Generation: 1
Resource Version: 4017247
Self Link: /apis/autoscaling.alibabacloud.com/v1beta1/namespaces/default/cronhorizontalpodautoscalers/cronhpa-sample
UID: 05e41c95-5ea2-11e9-8ce6-00163e12e274
Spec:
Jobs:
Name: scale-down
Schedule: 30 */1 * * * *
Target Size: 1
Name: scale-up
Schedule: 0 */1 * * * *
Target Size: 3
Scale Target Ref:
API Version: apps/v1beta2
Kind: Deployment
Name: nginx-deployment-basic
Status:
Conditions:
Job Id: 38e79271-9a42-4131-9acd-1f5bfab38802
Last Probe Time: 2019-04-14T10:43:02Z
Message:
Name: scale-down
Schedule: 30 */1 * * * *
State: Submitted
Job Id: a7db95b6-396a-4753-91d5-23c2e73819ac
Last Probe Time: 2019-04-14T10:43:02Z
Message:
Name: scale-up
Schedule: 0 */1 * * * *
State: Submitted
Events: <none>4. 等待一段时间,查看 cronhpa 的运行状态。
kubernetes-cronhpa-controller git:(master) kubectl describe cronhpa cronhpa-sample
Name: cronhpa-sample
Namespace: default
Labels: controller-tools.k8s.io=1.0
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"autoscaling.alibabacloud.com/v1beta1","kind":"CronHorizontalPodAutoscaler","metadata":{"annotations":{},"labels":{"controll...
API Version: autoscaling.alibabacloud.com/v1beta1
Kind: CronHorizontalPodAutoscaler
Metadata:
Creation Timestamp: 2019-04-15T06:41:44Z
Generation: 1
Resource Version: 15673230
Self Link: /apis/autoscaling.alibabacloud.com/v1beta1/namespaces/default/cronhorizontalpodautoscalers/cronhpa-sample
UID: 88ea51e0-5f49-11e9-bd0b-00163e30eb10
Spec:
Jobs:
Name: scale-down
Schedule: 30 */1 * * * *
Target Size: 1
Name: scale-up
Schedule: 0 */1 * * * *
Target Size: 3
Scale Target Ref:
API Version: apps/v1beta2
Kind: Deployment
Name: nginx-deployment-basic
Status:
Conditions:
Job Id: 84818af0-3293-43e8-8ba6-6fd3ad2c35a4
Last Probe Time: 2019-04-15T06:42:30Z
Message: cron hpa job scale-down executed successfully
Name: scale-down
Schedule: 30 */1 * * * *
State: Succeed
Job Id: f8579f11-b129-4e72-b35f-c0bdd32583b3
Last Probe Time: 2019-04-15T06:42:20Z
Message:
Name: scale-up
Schedule: 0 */1 * * * *
State: Submitted
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Succeed 5s cron-horizontal-pod-autoscaler cron hpa job scale-down executed successfully此时可以在 event 中发现负载的定时伸缩已经生效。
最后
kubernetes-cronhpa-controller 可以很好的解决拥有周期性资源画像的负载弹性,结合底层的 cluster-autoscaler 可以降低大量的资源成本。目前 kubernetes-cronhpa-controller 已经正式开源,更详细的用法与文档请查阅代码仓库的文档,欢迎开发者提交 issue 与 pr。
本文作者:刘中巍(莫源)
本文为云栖社区原创内容,未经允许不得转载。

