
MaxCompute问答整理之7月
本文是基于本人对MaxCompute产品的学习进度,再结合开发者社区里面的一些问题,进而整理成文。希望对大家有所帮助。
问题一、DataWorks V2.0简单模式和标准模式的区别?
公司数仓的数据上云后,在使用MaxCompute计算引擎时,需要一个稳定、可靠的调度系统,将自身数据生产任务(代码)按照所需依赖关系、运行时间来调度运行,那么DataWorks就派上了用场。DataWorks提供简单模式和标准模式两种工作空间模式。
简单模式指一个DataWorks工作空间对应一个MaxCompute项目,无法设置开发环境和生产环境,只能进行简单的数据开发。标准模式指一个DataWorks工作空间对应两个MaxCompute项目,可以设置开发和生产环境,提升代码开发规范。两个模式还存在项目、用户和权限的不同。大家可以通过学习官方文档或者是实操来加强认知。
https://help.aliyun.com/document_detail/85772.html
问题二、用数据集成新增数据源时,测试连通性失败,是什么原因?
当需要新增数据源时,首先要确认自己的数据源类型、网络类型、是否支持测试连通性。当新增数据源无法支持测试连通性时,可以尝试用独享资源组来解决数据集成问题。
具体数据源的区别可以参考文档查看:https://help.aliyun.com/knowledge_detail/72964.html
温馨提示:配置数据源时记得检查账号密码。
问题三、数据源配置中数据过滤条件如何填写?
数据过滤是同步数据的删选条件,可以通过SQL语法填写where过滤语句,一般都是通过日期字段来删选数据。DataWorks的参数配置功能可以满足业务场景的需求,目前参数分为系统参数和自定义参数(推荐)两大类。关于数据源和参数配置可以参考以下文档来详细学习:
数据源配置:https://help.aliyun.com/knowledge_list/72788.html
参数配置:https://help.aliyun.com/document_detail/74450.html
问题四、UDF如何加入项目函数列表?
用户可以通过自定义函数来满足不同的计算需求,MaxCompute的UDF支持跨项目分享。UDF的发布可以通过DataWorks界面来完成。可以参考产品文档来操作:https://help.aliyun.com/document_detail/107615.html
问题五、如果我买30个CU时(预付费形式)是不是只能用30个Core来运行任务,当公有云里面资源空闲时,系统会不会像扫描按量付费那样,自动调用30Core以外的空闲资源,来加速我的任务运行?
预付费的资源池是独享的,按购买CU(1CU=1核CPU+4G内存)量固定分配资源,计算任务只能占用独享的资源。但是当在同个区域,已经开通一个预付费规格的情况下,可以通过升级和降配资源方式开通其他规格。如果任务量较大,可以考虑对于消耗资源少的任务采取预付费,资源较大的任务采取按I/O后付费,这样可以保证任务运行时一直有CU资源。
问题六、想写Spark处理MaxCompute上的表数据,但是似乎并不能像写Sql一样在DataWorks上去写Spark程序,应该在哪里写Spark程序,MaxCompute Studio可以吗?
目前MaxCompute Spark支持三种运行方式:Local模式、Cluster模式和DataWorks中执行模式。三种模式需要进行不同的配置,请参考如下文档:
https://help.aliyun.com/document_detail/102430.html
问题七、MaxCompute是否支持MD5函数?
支持,MxCompute可以通过内建函数和UDF来实现业务计算需求,常见的日期函数、数学函数、字符串函数等,MaxCompute都是支持的,可以参考如下文档:
https://help.aliyun.com/document_detail/96342.html
问题八、日志记录的各项信息代表什么如何查看?
我理解日志记录其实就是MaxCompute产品里的Logview,Logview是MaxCompute Job提交后查看和Debug任务的工具。可以通过Logview可以看到一个Job的运行状态、运行结果和具体细节以及每个步骤的进度。
具体功能组件含义请参考如下文档:https://help.aliyun.com/document_detail/27987.html
问题九、MaxCompute 2.0里的数据类型使用需要set设置,是否可以在DataWorks里面运行?
使用数据类型系统时,需要进行设置:set odps.sql.type.system.odps2=true;或setproject odps.sql.type.system.odps2=true; ,语句是可以在DataWorks新建表的DDL模式下执行操作。
温馨提示:记得关注数据类型转换。
问题十、decimal数据类型精度溢出如何解决?问题实例如下图。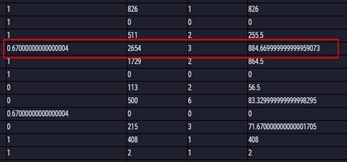
可以进行set设置:set odps.sql.decimal.odps2=true;
【预告】8月活动预告
2019大数据技术公开课第三季直播8月13日开启,直播主题及观看直播,可加入“MaxCompute开发者社群2群” 了解并观看
本文作者:亢海鹏
本文为云栖社区原创内容,未经允许不得转载。

