

大数据概述
大数据
对于大数据,研究机构Gartner给出了这样的定义:“大数据”是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合。需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力来适应海量、高增长率和多样化的信息资产。
适用于大数据的技术包括大规模并行处理数据库、数据挖掘、分布式文件系统、分布式数据库、云计算平台、互联网和可扩展的存储系统等。
大数据有4个特性,简称4V:Volume、Variety、Velocity、Value
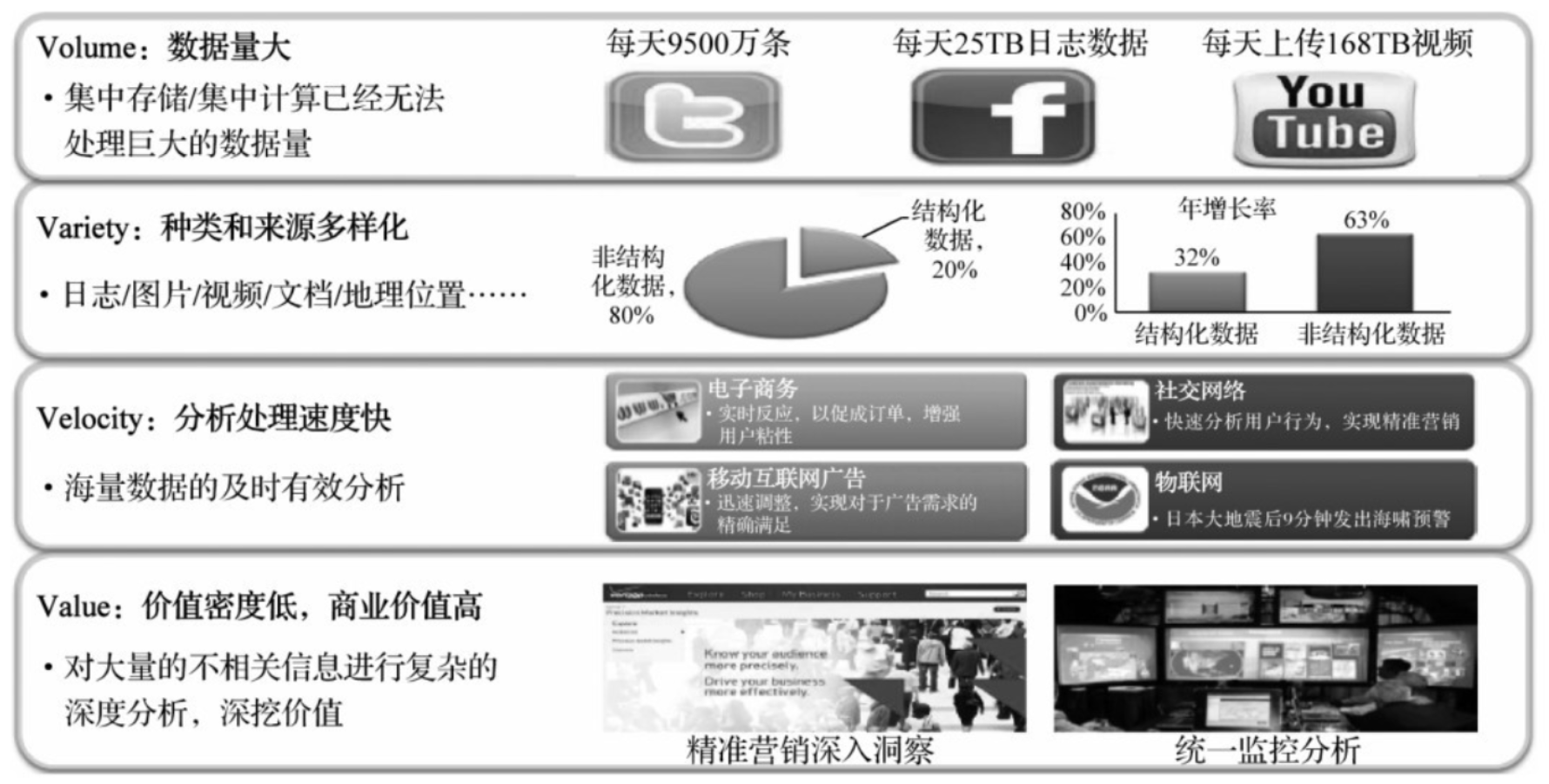
Volume(规模性):大数据的特征首先体现为“数据量大”,存储单位从过去的GB到TB,直到PB、EB。随着网格及信息技术的高速发展,数据开始爆发性增长。
Variety(多样性):大数据大体可以分为三类:一类是结构化数据,如系统数据,信息系统管理数据,医疗系统数据,其特点是数据间因果关系强;二类是非结构化数据,如视频、图片、音频等,其特点是数据间没有因果关系;三类是半结构化数据,如HTML文档、邮件、网页等,其特点是数据间的因果关系弱。
Velocity(高速性):数据被创建和移动的速度快
Value(价值性):相比于传统的小数据,大数据最大的价值在于通过大量不相关的各种类型数据中,挖掘出对未来趋势与模式预测分析有价值的数据,并通过机器 学习方法、人工智能方法或数据挖掘方法进入深度分析,发现新规律和新知识,并运用于各个领域。
大数据处理的基础技术
大数据的存储、处理与分析依赖于分布式计算机系统。分布式计算机系统是指由多台分散的、硬件自治的计算机,经过互联的网络连接而形成的系统,系统的处理和控制功能分布在各个计算机上。分布式系统由许多独立的、可协同工作的CPU组成,从用户的角度看,整个系统更像一台独立的计算机。常见的分布式系统有分布式计算系统、分布式文件系统、分布式数据库系统等。
大数据处理流程
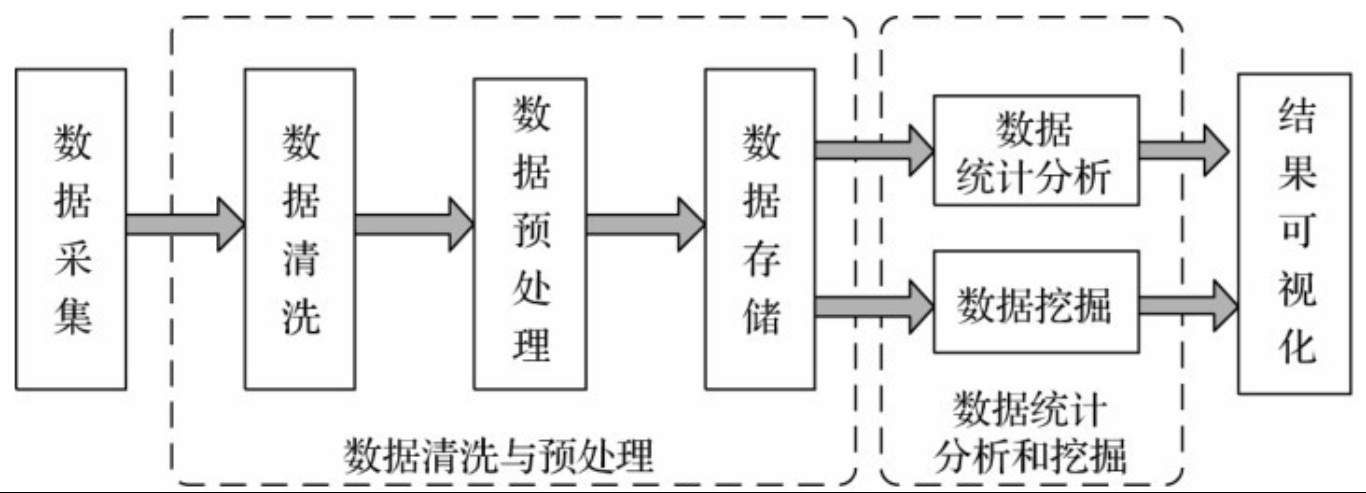
一般而言,大数据处理可分为四步:数据采集、数据清洗与预处理、数据统计分析和挖掘、结果可视化。
这四个步骤看起来与现在的数据处理分析没有太大区别,但实际上数据集更大,相互之间的关系更多,需要的计算量也更大,通常需要在分布式系统上,利用分布式计算完成。
流行的大数据技术
流行的大数据技术涉及大数据处理的各个阶段,包括:架构、采集、存储、计算处理和可视化等。而Hadoop则是一个集合了大数据不同阶段技术的生态系统。
Hadoop的核心是yarn、HDFS和MapReduce,如下图所示:

上图还集成了Spark生态圈,在未来一段时间内,Hadoop将与Spark共存,Hadoop与Spark都能部署在Yarn和Mesos的资源管理系统之上。
下面对上图的各元素进行介绍
1、HDFS(Hadoop Distributed File System Hadoop分布式文件系统)
HDFS是Hadoop体系中数据存储管理的基础,它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量数据访问能力,适合带有大型数据集的应用程序。HDFS提供了一次写入多次读取的机制,数据以块的形式,同时分布在集群的不同物理机器上。
2、MapReduce(分布式计算框架)
MapReduce是一种分布式计算模型,用于大数据计算,它屏蔽了分布式计算框架细节,将计算抽象成Map和Reduce两部分。其中,Map对数据集上的独立元素进行指定的操作,生成键-值对形式的中间结果;Reduce则对结果中相同的“键”的所有“值”进行规约,以得到最终结果。MapReduce非常适合在大量计算机组成的分布式并行环境里进行数据处理。
MapReduce提供了以下的主要功能:
(1)数据划分和计算任务调度
(2)数据/代码互定位
(3)系统优化
(4)出错检测和恢复
3、HBase(分布式列存储数据库)
HBase是一个建立在HDFS之上,面向列的针对结构化数据的可伸缩、高可靠、高性能、分布式数据库。HBase采用了BigTable的数据模型:增加的稀疏映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase利用HDFS作为其文件存储系统,并利用MapReduce来处理HBase中的海量数据,利用Zookeeper提供协同服务。
4、Zookeeper(分布式协同服务)
Zookper是一个为分布式应用提供协同服务的软件,提供包括配置维护、域名服务、分布式同步、组服务等功能,用于解决分布式环境下的数据管理问题。
5、Hive(数据仓库工具)
Hive是基于Hadoop的一个数据仓库工具,由Facebook开源,最初用于解决海量结构化日志数据的统计问题。Hive使用类SQL的HiveQL来实现数据查询,并将HQL转化为在Hadoop上执行的MapReduce任务。Hive用于离线 数据分析,可以让不熟悉MapReduce的开发人员,使用HQL来实现查询分析,降低了大数据处理的门槛 。Hive本质 上还是基于HDFS的应用程序。
6、Pig(ad-hoc脚本)
Pig是由Yahoo!提供的开源软件,设计动机是提供一种基于MapReduce的ad-hoc(计算在Query时发生)数据分析工具。Pig是一种编程语言,它简化了Hadoop常见的工作任务,Pig可加载数据、表达转换数据以及存储最终结果。
7、Sqoop(数据ETL/同步工具)
Sqoop是SQL-to-Hadoop的缩写,是一个Apache项目,主要用于传统数据库和Hadoop之间的传输数据,可以将一个关系型数据库(如MySQL、Oracle、Postgres等)中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导入到关系型数据库中。
8、Flume(日志收集工具)
Flume是一个可扩展、适合复杂环境的海量日志收集系统。
9、Mahout(数据挖掘算法库)
Mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加快捷方便地创建智能应用程序。Mahout现在已经包含了聚类、分类、推荐引擎和频繁集挖掘等广泛使用的数据挖掘方法。
10、Oozie(工作流调度器)
Oozie是一个可扩展的工作体系,集成于Hadoop堆栈,用于协调多个MapReduce作业的执行,它能够管理一个复杂的系统,基于外部事件来执行。
11、Yarn(分布式资源管理器)
Yarn是下一代MapReduce,即MR V2,是在第一代经典MapReduce调度模型基础上演变而来的,主要是为了解决原始Hadoop扩展性较差,不支持多计算框架而提出的。
12、Mesos(分布式资源管理器)
Mesos诞生于UC Berkeley的一个研究项目,现已成为Apache项目。Mesos是一个资源统一管理和调度的平台,同样支持MapReduce、Streaming等多种运算框架。
13、Tachyon(分布式内存文件系统)
Tachyon是以内存为中心的分布式文件系统,拥有高性能和容错能力,并具有类Java的文件API、插件式的底层文件系统、兼容Hadoop MapReduce和Apache Spark等特点,能够为集群框架(如Spark、MapReduce)提供可靠的内存级速度的文件共享服务。
14、Tez(DAG计算模型)
Tez是Apache开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduces两个操作进一步拆分。分解后的元操作可以任意灵活组装。
15、Spark(内存DAG计算模型)
Spark是一个Apache项目,它被称为“快如闪电的集群计算”,拥有一个繁荣的开源社区,是目前最活跃的Apache项目之一。Spark提供了一个更快、更通用的数据处理平台。和Hadoop相比,Spark可以程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍。
16、Kafka(分布式消息队列)
Kafka是Linkedin于2010年开源的消息系统,它主要用于处理活跃的流式数据。活跃的流式数据在Web网站应用中非常常见,包括网站的点击量、用户访问内容、搜索内容等。
17、Storm
Storm是一个分布式实时大数据处理系统,用于在容错和水平可扩展方法中处理大量数据,它是一个流数据框架,具有 较高的摄取率。类似于Hadoop。
国内大数据面临的一些问题
1、数据孤岛问题突出
2、大数据安全和隐私令人担忧
3、人才缺乏,大数据技术创新能力不足



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
2020-07-07 WPF颜色(SolidColorBrush)和Win32颜色(COLOREF)互转的方法