基础教材系列:Linux原理《趣谈linux》极客时间笔记
1、电脑一通电,先运行主板上ROM(只读存储器)里写死的程序BIOS,BIOS去找要运行什么操作系统,运行操作系统的第一段代码,创建0号进程,它是这次开机所有进程的爹,
2、然后操作系统代码里先初始化中断门Interrupt Gate处理包括系统调用在内的各种中断,再初始化内存管理模块,然后运行一个函数初始化其他,这时会创建第二个进程,即1号进程,这是爹的大儿子,它以后会管理用户态的所有进程。
用户态和内核态的区别,两个态是针对代码权限而言的,物理上,就是两类代码访问的物理地址不一样,两者不能越界访问对方的物理地址。
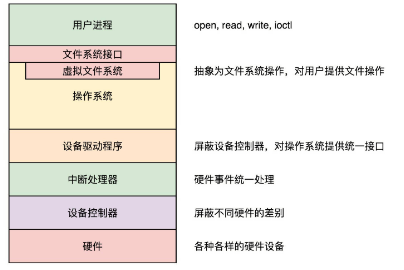
用户态,处于应用层,是用户写的代码;内核态,是操作系统访问关键资源的代码。用户写代码(比如C语言)进行网络请求时,代码里具体函数会经过Glibc库(它封装了系统调用函数,使系统调用更方便)转化为系统调用函数,系统调用函数再去调内核代码,内核代码再去调设备驱动(这里是网卡驱动),网卡发完数据包,系统调用结束,返回用户态。
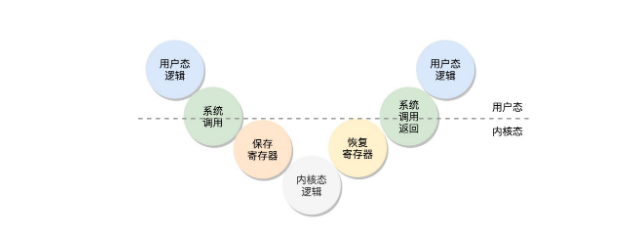
3、然后创建第三个进程,负责所有内核态线程的调度和管理。(对于内核而言,进程和线程都是task,一样的)
4、系统启动之后,init 进程(即1号进程)会启动很多的 daemon 进程,为系统运行提供服务,然后就是启动 getty,让用户登录,登录后运行 shell,用户启动的进程都是通过 shell 运行的,从而形成了一棵进程树。
5、线程和进程区别:进程默认有一个主线程的。线程是负责执行二进制指令的,它会根据项目执行计划书,一行一行执行下去。进程要比线程管的宽多了,除了执行指令之外,内存、文件系统等等都要它来管。进程相当于一个项目,而线程就是为了完成项目需求,而建立的一个个开发任务。默认情况下,你可以建一个大的任务,就是完成某某功能,然后交给一个人让它从头做到尾,这就是主线程。但是有时候,你发现任务是可以拆解的,如果相关性没有非常大前后关联关系,就可以并行执行。
线程的数据:
1)线程栈上本地数据,线程私有
2)在整个进程里共享的全局数据:例如全局变量,虽然在不同进程中是隔离的,但是在一个进程中是共享的。
Mutex,全称 Mutual Exclusion,中文叫互斥。谁拿到锁了谁访问,没抢到的阻塞,不想阻塞的返回错误码,用完的人释放锁,
3)线程私有数据:key 一旦被创建,所有线程都可以访问它,但各线程可根据自己的需要往 key 中填入不同的值,这就相当于提供了一个同名而不同值的全局变量。
进程的权限:
1)通过chmod u+s program 命令,设置set-user-ID 的标识位,以用户和用户组控制权限
2)capabilities,这个解决了非 root 用户进程使用 exec 执行一个程序的时候,如何保留权限的问题。
进程的上下文切换主要干两件事情,一是切换进程空间,也即虚拟内存;二是切换寄存器和 CPU 上下文。所谓的进程切换,就是将某个进程的 thread_struct 里面的寄存器的值,写入到 CPU 的 TR 指向的 tss_struct,对于 CPU 来讲,这就算是完成了切换。
CPU调度不同进程的切换,是通过主动调度或抢占式调度进行的:进程调度第一定律—— 一定要等待正在运行的进程调用 __schedule 才能抢占。调度主要发生在中断、调用返回的时候。
进程的创建:fork函数最后会走到系统调用 sys_fork,此函数先复制进程结构,如任务ID、任务状态、运行统计、亲缘关系、权限、调度相关、信号处理、内存管理等内容,然后调用wake_up_new_task函数唤醒新进程。
线程的创建:它由内核态和用户态合作完成,用户态先调用glibc库中的函数allocate_stack,此函数中触发内核态系统调用,进行标志位设定、亲缘关系和信号处理,内核调用完成,返回系统调用,返回用户态,在用户态调用start_thread函数,开始运行线程,运行完成后,调用函数deallocate_stack释放线程栈,至此线程生命周期完成。
6、内存空间怎么分配
为了防止一个物理地址面对多个值得冲突,计算机使用虚拟地址,对于一个进程来说,如果有32位,那它就拥有一个2^32=4G的空间,64位则更大,这个大虚拟地址一分为二,一份用来放内核的东西,称为内核空间,一部分用来放进程的东西,称为用户空间。
用户空间在下,在低地址;内核空间在上,在高地址。
从低位开始,往上走,分别放了可执行代码、静态常量、静态变量、堆、文件依赖的动态链接库、栈(主线程的栈空间就在这儿),用户态触发系统调用的话,就会用到内核空间,内核空间里的地址,对于每个进程来说,是公有的(对于每个进程来说,用户空间是是它一个人的),别的进程用了那块地址,我就不能用了,所以内核空间要用锁。
物理内存根据 NUMA 架构分节点。每个节点里面再分区域。每个区域里面再分页。物理页面通过伙伴系统(如果对应的页块链表中没有空闲页块,那我们就在更大的页块链表中去找。当分配的页块中有多余的页时,伙伴系统会根据多余的页块大小插入到对应的空闲页块链表中。例如,要请求一个 128 个页的页块时,先检查 128 个页的页块链表是否有空闲块。如果没有,则查 256 个页的页块链表;如果有空闲块的话,则将 256 个页的页块分成两份,一份使用,一份插入 128 个页的页块链表中。如果还是没有,就查 512 个页的页块链表;如果有的话,就分裂为 128、128、256 三个页块,一个 128 的使用,剩余两个插入对应页块链表。)进行分配。分配的物理页面要变成虚拟地址让上层可以访问,kswapd 可以根据物理页面的使用情况对页面进行换入换出。对于内存的分配需求,可能来自内核态,也可能来自用户态。
对于内核态,kmalloc 在分配大内存的时候,以及 vmalloc 分配不连续物理页的时候,直接使用伙伴系统,分配后转换为虚拟地址,访问的时候需要通过内核页表进行映射。对于 kmem_cache 以及 kmalloc 分配小内存,则使用 slub 分配器,将伙伴系统分配出来的大块内存切成一小块一小块进行分配。kmem_cache 和 kmalloc 的部分不会被换出,因为用这两个函数分配的内存多用于保持内核关键的数据结构。内核态中 vmalloc 分配的部分会被换出,因而当访问的时候,发现不在,就会调用 do_page_fault。
对于用户态的内存分配,或者直接调用 mmap 系统调用分配,或者调用 malloc。调用 malloc 的时候,如果分配小的内存,就用 sys_brk 系统调用;如果分配大的内存,还是用 sys_mmap 系统调用。正常情况下,用户态的内存都是可以换出的,因而一旦发现内存中不存在,就会调用 do_page_fault。
7、文件系统如何存放文件:
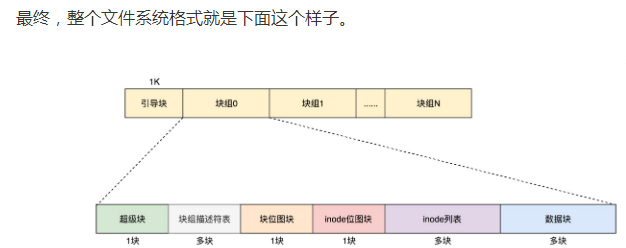
linux主流用的是ext格式,新买的应该要格式化(将一块盘使用命令组织成一定格式的文件系统的过程),要格式化了才能放文件。使用 Windows 的时候,咱们常格式化的格式为 NTFS(New Technology File System)。在 Linux 下面,常用的是 ext3 或者 ext4。硬盘分成大小相同的块,一个块默认大小是4K个扇区。一个文件可以分布在多个块上, 每个文件都有大小、权限等基本信息,放在一个叫inode的结构里,inode有12个值,每个值放数据块的位置,对于数据块过大的情况,12个不够用,ext2、3,用的是间接块方法,即在第12个值里,不放数据块的位置,而放下一个inode[1]的位置信息,ext4用的是Extents方法,inode里放的都是树的根结点位置,每个根结点有多个子树,子树上的每个结点,指向一个连续块的地址。
硬链接与软链接的区别:硬链接与原始文件共用一个 inode 的,但是 inode 是不跨文件系统的,每个文件系统都有自己的 inode 列表,因而硬链接是没有办法跨文件系统的。而软链接不同,软链接相当于重新创建了一个文件。这个文件也有独立的 inode,只不过打开这个文件看里面内容的时候,内容指向另外的一个文件。这就很灵活了。我们可以跨文件系统,甚至目标文件被删除了,链接文件还是在的,只不过指向的文件找不到了而已。
8、CPU给设备发了一个指令,让它读取一些数据,它读完的时候,怎么通知CPU呢?
有一个硬件的中断控制器,当设备完成任务后触发中断到中断控制器,中断控制器就通知 CPU,一个中断产生了,CPU 需要停下当前手里的事情来处理中断。
中断有两种,一种软中断,例如代码调用 INT 指令触发,一种是硬件中断,就是硬件通过中断控制器触发的。
一个设备驱动程序初始化的时候,要先注册一个该设备的中断处理函数,中断返回的那一刻是进程切换的时机,中断的时候,触发的函数是 do_IRQ。这个函数是中断处理的统一入口。在这个函数里面,我们可以找到设备驱动程序注册的中断处理函数 Handler,然后执行它进行中断处理。
信号也是类似的,当信号来的时候,我们并不直接处理这个信号,而是设置一个标识位 TIF_SIGPENDING,来表示已经有信号等待处理。同样等待系统调用结束,或者中断处理结束,从内核态返回用户态的时候,再进行信号的处理。
信号的发送与处理是一个复杂的过程,这里来总结一下:
假设我们有一个进程 A,main 函数里面调用系统调用进入内核。按照系统调用的原理,会将用户态栈的信息保存在 pt_regs 里面,也即记住原来用户态是运行到了 line A 的地方。在内核中执行系统调用读取数据。当发现没有什么数据可读取的时候,只好进入睡眠状态,并且调用 schedule 让出 CPU,这是进程调度第一定律。将进程状态设置为 TASK_INTERRUPTIBLE,可中断的睡眠状态,也即如果有信号来的话,是可以唤醒它的。其他的进程或者 shell 发送一个信号,有四个函数可以调用 kill、tkill、tgkill、rt_sigqueueinfo。四个发送信号的函数,在内核中最终都是调用 do_send_sig_info。do_send_sig_info 调用 send_signal 给进程 A 发送一个信号,其实就是找到进程 A 的 task_struct,或者加入信号集合,为不可靠信号,或者加入信号链表,为可靠信号。do_send_sig_info 调用 signal_wake_up 唤醒进程 A。进程 A 重新进入运行状态 TASK_RUNNING,根据进程调度第一定律,一定会接着 schedule 运行。进程 A 被唤醒后,检查是否有信号到来,如果没有,重新循环到一开始,尝试再次读取数据,如果还是没有数据,再次进入 TASK_INTERRUPTIBLE,即可中断的睡眠状态。当发现有信号到来的时候,就返回当前正在执行的系统调用,并返回一个错误表示系统调用被中断了。系统调用返回的时候,会调用 exit_to_usermode_loop。这是一个处理信号的时机。调用 do_signal 开始处理信号。根据信号,得到信号处理函数 sa_handler,然后修改 pt_regs 中的用户态栈的信息,让 pt_regs 指向 sa_handler。同时修改用户态的栈,插入一个栈帧 sa_restorer,里面保存了原来的指向 line A 的 pt_regs,并且设置让 sa_handler 运行完毕后,跳到 sa_restorer 运行。返回用户态,由于 pt_regs 已经设置为 sa_handler,则返回用户态执行 sa_handler。sa_handler 执行完毕后,信号处理函数就执行完了,接着根据第 15 步对于用户态栈帧的修改,会跳到 sa_restorer 运行。sa_restorer 会调用系统调用 rt_sigreturn 再次进入内核。在内核中,rt_sigreturn 恢复原来的 pt_regs,重新指向 line A。从 rt_sigreturn 返回用户态,还是调用 exit_to_usermode_loop。这次因为 pt_regs 已经指向 line A 了,于是就到了进程 A 中,接着系统调用之后运行,当然这个系统调用返回的是它被中断了,没有执行完的错误。
9、管道的原理:所谓的匿名管道,其实就是内核里面的一串缓存。所谓的命名管道,其实是也是内核里面的一串缓存。
10、进程间通信机制:
对共享的内存进行保护,就需要信号量这样的同步协调机制。
无论是共享内存还是信号量,创建与初始化都遵循同样流程,通过 ftok 得到 key,通过 xxxget 创建对象并生成 id;生产者和消费者都通过 shmat 将共享内存映射到各自的内存空间,在不同的进程里面映射的位置不同;为了访问共享内存,需要信号量进行保护,信号量需要通过 semctl 初始化为某个值;接下来生产者和消费者要通过 semop(-1) 来竞争信号量,如果生产者抢到信号量则写入,然后通过 semop(+1) 释放信号量,如果消费者抢到信号量则读出,然后通过 semop(+1) 释放信号量;共享内存使用完毕,可以通过 shmdt 来解除映射。
semop 会调用 semtimedop,这是一个非常复杂的函数。semtimedop 做的第一件事情,就是将用户的参数,例如,对于信号量的操作 struct sembuf,拷贝到内核里面来。另外,如果是 P 操作,很可能让进程进入等待状态,是否要为这个等待状态设置一个超时,timeout 也是一个参数,会把它变成时钟的滴答数目。semtimedop 做的第二件事情,是通过 sem_obtain_object_check,根据信号量集合的 id,获得 struct sem_array,然后,创建一个 struct sem_queue 表示当前的信号量操作(进程并发底层仍然是靠队列处理)。为什么叫 queue 呢?因为这个操作可能马上就能完成,也可能因为无法获取信号量不能完成,不能完成的话就只好排列到队列上,等待信号量满足条件的时候。semtimedop 会调用 perform_atomic_semop 在实施信号量操作。
信号量是一个整个 Linux 可见的全局资源,而不像咱们在线程同步那一节讲过的都是某个进程独占的资源,好处是可以跨进程通信,坏处就是如果一个进程通过 P 操作拿到了一个信号量,但是不幸异常退出了,如果没有来得及归还这个信号量,可能所有其他的进程都阻塞了。那怎么办呢?Linux 有一种机制叫 SEM_UNDO,也即每一个 semop 操作都会保存一个反向 struct sem_undo 操作,当因为某个进程异常退出的时候,这个进程做的所有的操作都会回退,从而保证其他进程可以正常工作。
等待队列上的每一个 struct sem_queue,都有一个 struct sem_undo,以此来表示这次操作的反向操作。
上面的讲解,让我想起,如果是多核CPU,所谓原子操作,究竟如何实现呢?
总之,cas的核心,就是在最底层处,硬件级别,要么锁内存,要么锁总线的前提下CPU每个核再去执行TS原子指令。所以并发的根源,其实还是某一刻只做一件事。
11、网络通信
操作系统选择对于网络协议的实现模式是,二到四层的处理代码在内核里面,七层的处理代码让应用自己去做,两者需要跨内核态和用户态通信,就需要一个系统调用完成这个衔接,这就是 Socket。
三次握手,是 TCP 层的动作,是在内核完成的,应用层不需要参与。
当一些网络包到来触发了中断,内核处理完这些网络包之后,我们可以先进入主动轮询 poll 网卡的方式,主动去接收到来的网络包。如果一直有,就一直处理,等处理告一段落,就返回干其他的事情。当再有下一批网络包到来的时候,再中断,再轮询 poll。这样就会大大减少中断的数量,提升网络处理的效率,这种处理方式我们称为 NAPI。
我们将请求封装为 HTTP 协议,通过 Socket发送到内核。内核的网络协议栈里面,在 TCP 层创建用于维护连接、序列号、重传、拥塞控制的数据结构,将 HTTP 包加上 TCP 头,发送给 IP 层,IP 层加上 IP 头,发送给 MAC 层,MAC 层加上 MAC 头,从硬件网卡发出去。
最终网络包会被转发到目标服务器,它发现 MAC 地址匹配,就将 MAC 头取下来,交给上一层。IP 层发现 IP 地址匹配,将 IP 头取下来,交给上一层。TCP 层会根据 TCP 头中的序列号等信息,发现它是一个正确的网络包,就会将网络包缓存起来,等待应用层的读取。应用层通过 Socket 监听某个端口,因而读取的时候,内核会根据 TCP 头中的端口号,将网络包发给相应的应用。
12、虚拟化
13、容器
容器实现封闭的环境主要要靠两种技术,一种是看起来是隔离的技术,称为 namespace(命名空间)。在每个 namespace 中的应用看到的,都是不同的 IP 地址、用户空间、进程 ID 等。另一种是用起来是隔离的技术,称为 cgroup(网络资源限制),即明明整台机器有很多的 CPU、内存,但是一个应用只能用其中的一部分。
在每一个进程的 task_struct 里面,有一个指向 namespace 结构体的指针 nsproxy,nsproxy中含有6个结构指针,分别描述pid、网络、用户组等信息,如果要创建一个namespace,内核会调用函数逐一复制这些值。namespace有三个常用的函数 clone、setns 和 unshare。要直接操作 Namespace,有两个常用的命令 nsenter 和 unshare。
在cgroup文件夹下,有cpu、内存、io等不同的文件夹,以cpu文件夹为例,里面是docker id的文件夹,此文件夹里是各种cpu相关参数,如设置cpu核数,cpu使用率等。系统初始化时,cgroup也会初始化,初始化 cgroup 的各个子系统的操作函数,分配各个子系统的数据结构,cgroup 初始化完毕之后,接下来就是创建一个 cgroup 的文件系统,用于配置和操作 cgroup。文件系统的操作函数会调用到 cgroup 子系统的操作函数写入 cgroup 文件,设置 cpu 或者 memory 的相关参数。文件系统再写入 tasks 文件,将进程交给某个 cgroup 进行管理。每一个 cgroup 子系统会调用相应的attach函数,
例如 CPU 调用顺序是 cpu_cgroup_attach-> sched_move_task-> sched_change_group,在 sched_change_group 中设置这个进程以这个 task_group 的方式参与调度。最终对于CPU而言,修改了 scheduled entity,也放入相应的队列里,从而下次调度的时候就起作用了。
对于内存,写入内存的限制使用函数 mem_cgroup_write->mem_cgroup_resize_limit 来设置 struct mem_cgroup 的 memory.limit 成员。在进程执行过程中,申请内存的时候,我们会调用 handle_pte_fault->do_anonymous_page()->mem_cgroup_try_charge()。在 mem_cgroup_try_charge 中,先是调用 get_mem_cgroup_from_mm 获得这个进程对应的 mem_cgroup 结构,然后在 try_charge 中,根据 mem_cgroup 的限制,看是否可以申请分配内存。所以,对于内存的 cgroup 设定,只有在申请内存的时候才起作用。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本