Redis的使用场景和高并发高性能
高性能
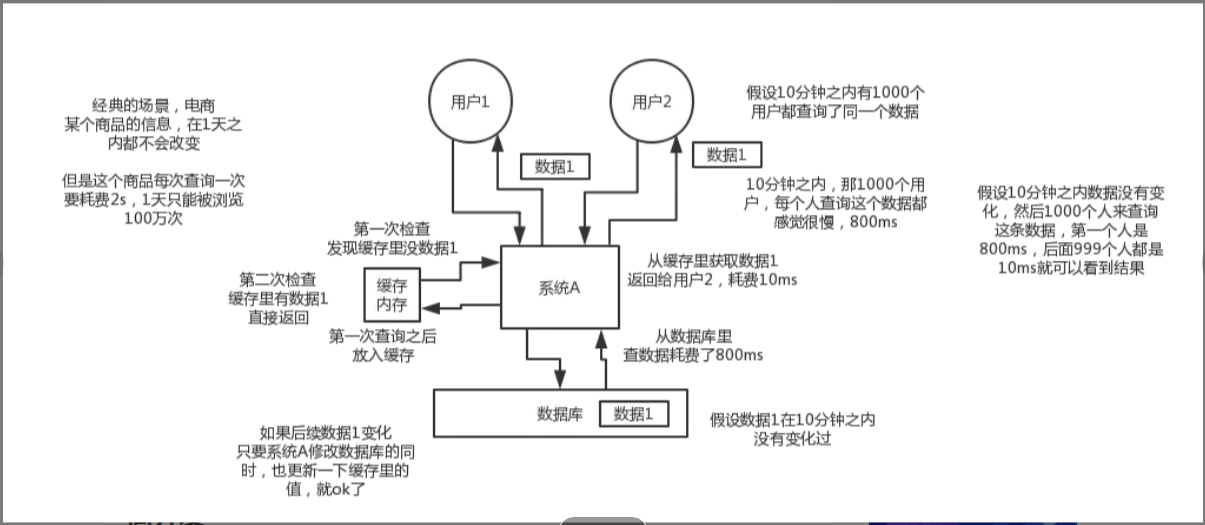
假设这么个场景,你有个操作,一个请求过来,吭哧吭哧你各种乱七八糟操作查询mysql,半天查出来一个结果,耗时600ms。但是这个结果可能接下来几个小时都不会变了,或者变了也可以不用立即反馈给用户。那么此时咋办?
缓存啊,折腾600ms查出来的结果,扔缓存里,一个key对应一个value,下次再有人查同样的数据,别走mysql折腾600ms了。直接从缓存里取出,通过一个key查出来一个value,2ms搞定。性能提升300倍。
这就是所谓的高性能。
高并发
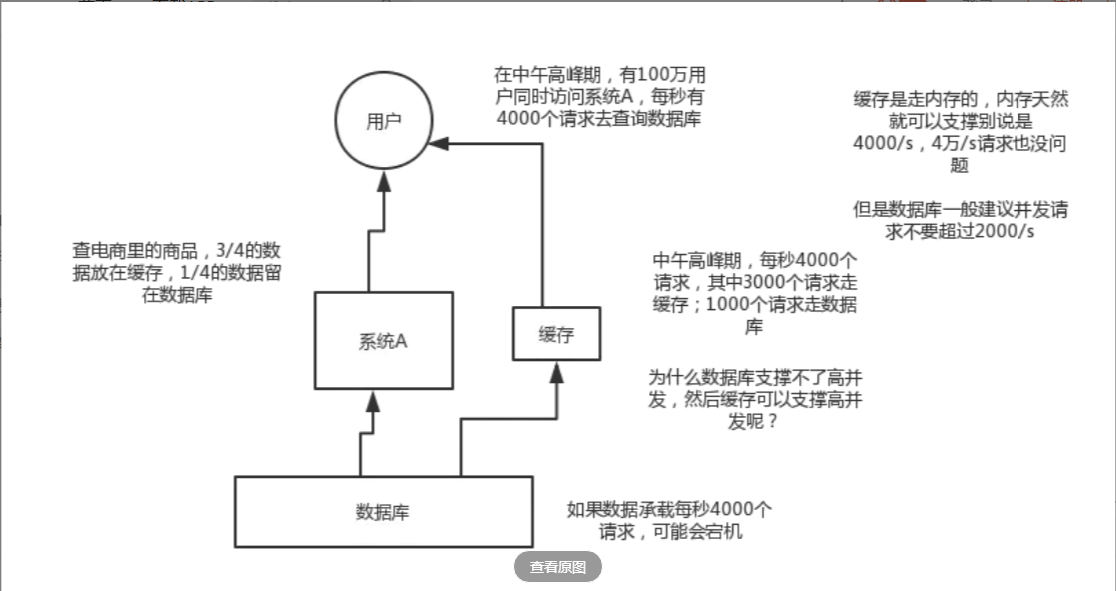
mysql这么重的数据库,压根儿设计不是让你玩儿高并发的,虽然也可以玩儿,但是天然支持不好。mysql单机支撑到2000qps也开始容易报警了。
所以要是你有个系统,高峰期一秒钟过来的请求有1万,那一个mysql单机绝对会死掉。你这个时候就只能上缓存,把很多数据放缓存,别放mysql。缓存功能简单,说白了就是key-value式操作,单机支撑的并发量轻松一秒几万十几万,支撑高并发so easy。单机承载并发量是mysql单机的几十倍。
所以要结合这俩场景考虑一下,你为啥要用缓存?
一般很多同学项目里没啥高并发场景,那就别折腾了,直接用高性能那个场景吧,就思考有没有可以缓存结果的复杂查询场景,后续可以大幅度提升性能,优化用户体验,有,就说这个理由,没有?那你也得编一个出来吧,不然你不是在搞笑么
问题分析
(1) redis 和 memcached 的区别
redis支持更丰富的数据类型(支持更复杂的应用场景):Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。memcache支持简单的数据类型,String。
redis与Memcached一样,都支持数据的持久化,为了保证效率,数据都是缓存在内存中。区别的是Redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步,而Memecache只会把数据全部存在内存之中。
集群模式:memcached没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 redis 目前是原生支持 cluster 模式的.
Memcached是多线程,非阻塞IO复用的网络模型;Redis使用单线程的多路 IO 复用模型

(2)为啥redis单线程模型也能效率这么高?
1)纯内存操作
2)核心是基于非阻塞的IO多路复用机制
3)单线程反而避免了多线程的频繁上下文切换问题(百度)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号