
Redis 思维导图 (解析版)
Redis常见面试题及参考回答:
一、 什么是Redis?
Redis是一个高性能的Key-Value数据库,是非关系型数据库。
Redis中 数据存放在内存中,存写速度特别快,所以redis广泛应用于缓存方向。另外rdis也常用来做分布式锁。
Redis支持多种数据类型,String、Hash、list、set、zset 。
Redis还支持 持久化、集群、事务等。
二、为什么要使用Redis?(为什么要使用缓存?)
1. 高性能:
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在数 缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当 快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
2. 高并发:
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中 去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
三、 Redis这么设置过期时间?过期后如何删除?(①定期删除 ②惰性删除)
过期时间:Redis中有个设置时间过期的功能,即对存储在 redis 数据库中的值可以设置一个过期时间。作为一个缓存数据库, 这是非常实用的。如我们一般项目中的 token 或者一些登录信息,尤其是短信验证码都是有时间限制的,按照传统的数据库处理方式,一般都是自己判断过期,这样会严重影响项目性能。
所以我们在 set key 的时候,可以给key一个 expire time,就是过期时间,通过过期时间我们可以指定这个 key 可以存活的 时间。存活时间到了,这个key就过期了。
删除过期key: 两种方式,1.定期删除 2.惰性删除
定期删除:redis默认是每隔 100ms 就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。为什么是随机抽取?是因为:假设 redis 已经存了几十万个 key ,如果此时每隔100ms就遍历所有的设置了过期时间的 key 的话,就会给 CPU 带来很大的负载。
惰性删除:因为定期删除是随机抽取,可能会导致很多过期 key 到了时间却没有被删除掉。所以就有了惰性删除。惰性删除就是 假如过期 key,靠定期删除没有被删除掉,还停留在内存里,除非你的系统去查一下那个 key,才会被redis给删除掉,所以称为惰性删除。
注意:仅通过设置过期时间是有问题的。如果定期删除漏掉了很多过期 key,然后你也没及时去查, 也就没走惰性删除,此时会怎么样?如果大量过期key堆积在内存里,导致redis内存块耗尽了。
解决的办法是 Redis 的内存淘汰机制。
四、Redis的内存淘汰机制?(怎么保证Redis中的数据都是热点数据?)
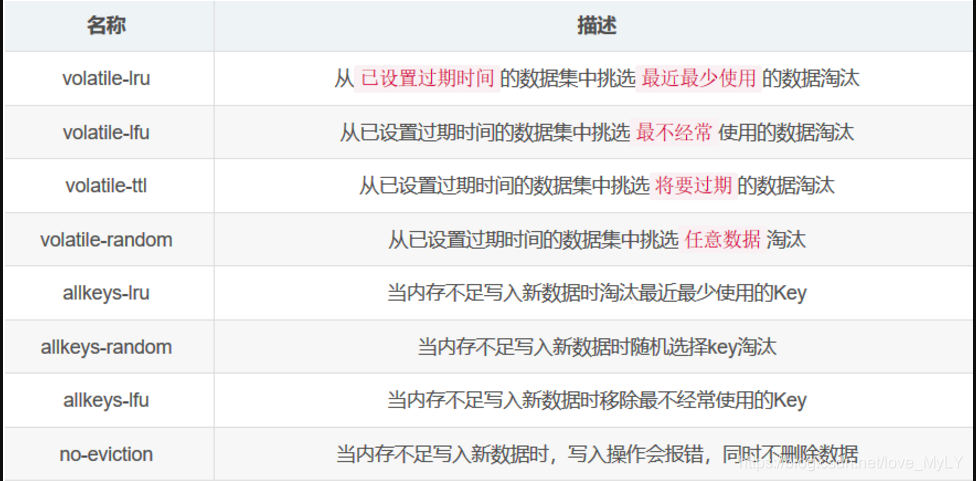
Redis配置文件中可以通过设定 maxmemory 来指定 Redis 最大内存限制,Redis 在启动时会把数据加载到内存中,达到指定的最大内存后,Redis 会根据配置的 内存淘汰机制 淘汰掉相应的key。
Redis提供了如下淘汰机制:
默认淘汰机制是:no-eviction
五、Redis 缓存雪崩问题是什么? 怎么解决?
缓存雪崩:缓存在同一时间内大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩 掉
解决办法:
事前:尽量保证整个 redis 集群的高可用性,发现机器宕机尽快补上。选择合适的内存淘汰策略。
事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉。
事后:利用 redis 持久化机制保存的数据尽快恢复缓存。
六、Redis 缓存穿透问题是什么? 怎么解决?
缓存穿透:大量去请求缓存中不存在的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决办法:
布隆过滤器:将所有可能存在的数据哈 希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压 力。
简单粗暴的方法:如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。这样就避免了数据库的查询,且对缓存的影响小。
其他方法...
七、Redis 和 Memcached 的有什么区别?
redis支持更丰富的数据类型(支持更复杂的应用场景):Redis不仅仅支持简单的k/v类型的数据,同时还提供 list,set,zset,hash等数据结构的存储。
memcache支持简单的数据类型,String。
Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memecache把数据全部存在内存之中。
集群模式:memcached没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 redis 目前 是原生支持 cluster 模式的.
Memcached是多线程,非阻塞IO复用的网络模型;Redis使用单线程的多路 IO 复用模型
八、 Redis的数据类型有哪些?它们的特点是什么?以及它们使用场景?
(Redis的5种数据类型、特点及使用场景,脑图上有,这里不赘述了。)
九、 Redis 的事务?
在Redis中, 通过 MULTI、EXEC、WATCH 等命令来实现事务(transaction)功能。
事务提供了一种将多个命令请求打包,然后一次性、按顺序地执行多个命令的机制,并且在事务执行期间,服务器不会中断事务而改去执行其他客户端的命令 请求,它会将事务中的所有命令都执行完毕,然后才去处理其他客户端的命令请求。
在传统的关系式数据库中,常常用 ACID 性质来检验事务功能的可靠性和安全性。在 Redis 中,事务总是具有原子性、一致性和隔离性,并且当 Redis 运行在某种特定的持久化模式下时,事务 也具有持久性。
十、 Redis 的并发竞争Key 的问题?
Redis并发竞争Key问题:多个系统同时对一个 key 进行操作,但是后执行的顺序和我们期望的顺序不同,这样也就导致了结果的不同。
解决:使用分布式锁。
为保证可靠性,一般选择Zookeeper实现。
基于zookeeper临时有序节点可以实现的分布式锁。大概思路为:当每个客户端对某个方法加锁时,在zookeeper上的 与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁 无法释放,而产生的死锁问题。完成业务流程后,删除对应的子节点释放锁。
注意:若Redis不存在并发竞争Key问题,不要使用分布式锁,因为会影响性能。
十一、Redis的缓存 如何保证和 数据库中的数据保持一致?
将 读请求 和 写请求 串行化,串行化到一个内存队列中,这样就可以保证一致性。
注意:除非特别必要,不要去读写串行化,因为会大幅降低系统的吞吐量,影响性能。
十二、Redis的持久化机制知道吗?(既使得Redis关闭,不丢失数据,重启后可以恢复数据。)
持久化:将内存中的数据写入到硬盘里面;这样当系统重启或者故障之后,可以恢复数据。
Redis支持两种持久化方案:① 快照(snapshotting,RDB) ②只追加文件(append-only file,AOF)
快照(RDB):
Redis可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis主从结构,主要用来提高Redis性 能),还可以将快照留在原地以便重启服务器的时候使用。
Redis默认采用 快照 持久化机制,在配置文件之可配置相关属性(save <seconds> <changes>)。
只追加文件(AOF):
每执行一条会更改Redis中的数据的命令,Redis就会将该命令写入硬盘中的AOF文件。
与快照相比,AOF实时性更好。
默认是关闭的,可以通过修改appendonly参数开启。
然后Redis还提供三种不同的AOF持久化方案:
appendfsync always #每次有数据修改发生时都会写入AOF文件,严重降低Redis的速度
appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
appendfsync no #让操作系统决定何时进行同步,不可控
一般为了兼顾数据和写入性能,会选用 appendfsync everyse ,这样Redis不仅性能几乎没有影响,而且即使系统崩溃了,最多只会丢失一秒内的数据,并且当硬盘执行写入操作繁忙时,Redis还会的放慢自己的速度以便适应硬盘的最大写入速度。
( AOF文件的 保存位置和RDB文件的位置相同,都是通过dir参数设置的,默认的文件名是appendonly.aof。)
注意:Redis关于持久化机制的优化——混合持久化
Redis 4.0之后, 开始支持 RDB 和 AOF 的混合持久化。
默认关闭,可以通过配置项 aof-use-rdb-preamble 开启。
混合持久化优点:AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头,可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。
混合持久化缺点: AOF 里面的 RDB 部分是压缩格式,而不是 AOF 格式,可读性差。
————————————————
版权声明:本文为CSDN博主「猿兄」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/love_MyLY/article/details/104190830

