
redis cluster集群部署方案
什么是 Redis 集群
Redis 集群是一个分布式(distributed)、容错(fault-tolerant)的 Redis 实现,集群可以使用的功能是普通单机 Redis 所能使用的功能的一个子集(subset)。
Redis 集群中不存在中心(central)节点或者代理(proxy)节点,集群的其中一个主要设计目标是达到线性可扩展性(linear scalability)。
Redis 集群为了保证一致性(consistency)而牺牲了一部分容错性:系统会在保证对网络断线(net split)和节点失效(node failure)具有有限(limited)抵抗力的前提下,尽可能地保持数据的一致性。
请注意,本教程使用于Redis3.0(包括3.0)以上版本
如果你计划部署集群,那么我们建议你从阅读这个文档开始。
Redis集群介绍
Redis 集群是一个提供在多个Redis间节点间共享数据的程序集。
Redis集群并不支持处理多个keys的命令,因为这需要在不同的节点间移动数据,从而达不到像Redis那样的性能,在高负载的情况下可能会导致不可预料的错误.
Redis 集群通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下继续处理命令. Redis 集群的优势:
自动分割数据到不同的节点上。
整个集群的部分节点失败或者不可达的情况下能够继续处理命令。
Redis 集群的数据分片
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念.
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
节点 A 包含 0 到 5500号哈希槽.
节点 B 包含5501 到 11000 号哈希槽.
节点 C 包含11001 到 16384号哈希槽.
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我像移除节点A,需要将A中得槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.
Redis 集群的主从复制模型
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有N-1个复制品.
在我们例子中具有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用.
然而如果在集群创建的时候(或者过一段时间)我们为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了
不过当B和B1 都失败后,集群是不可用的.
Redis 一致性保证
Redis 并不能保证数据的强一致性. 这意味这在实际中集群在特定的条件下可能会丢失写操作.
第一个原因是因为集群是用了异步复制. 写操作过程:
客户端向主节点B写入一条命令.
主节点B向客户端回复命令状态.
主节点将写操作复制给他得从节点 B1, B2 和 B3.
主节点对命令的复制工作发生在返回命令回复之后, 因为如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低 —— 我们必须在性能和一致性之间做出权衡。 注意:Redis 集群可能会在将来提供同步写的方法。 Redis 集群另外一种可能会丢失命令的情况是集群出现了网络分区, 并且一个客户端与至少包括一个主节点在内的少数实例被孤立。
举个例子 假设集群包含 A 、 B 、 C 、 A1 、 B1 、 C1 六个节点, 其中 A 、B 、C 为主节点, A1 、B1 、C1 为A,B,C的从节点, 还有一个客户端 Z1 假设集群中发生网络分区,那么集群可能会分为两方,大部分的一方包含节点 A 、C 、A1 、B1 和 C1 ,小部分的一方则包含节点 B 和客户端 Z1 .
Z1仍然能够向主节点B中写入, 如果网络分区发生时间较短,那么集群将会继续正常运作,如果分区的时间足够让大部分的一方将B1选举为新的master,那么Z1写入B中得数据便丢失了.
注意, 在网络分裂出现期间, 客户端 Z1 可以向主节点 B 发送写命令的最大时间是有限制的, 这一时间限制称为节点超时时间(node timeout), 是 Redis 集群的一个重要的配置选项:
搭建并使用Redis集群
搭建集群的第一件事情我们需要一些运行在 集群模式的Redis实例. 这意味这集群并不是由一些普通的Redis实例组成的,集群模式需要通过配置启用,开启集群模式后的Redis实例便可以使用集群特有的命令和特性了.
目前redis支持的cluster特性
1):节点自动发现
2):slave->master 选举,集群容错
3):Hot resharding:在线分片
4):进群管理:cluster xxx
5):基于配置(nodes-port.conf)的集群管理
6):ASK 转向/MOVED 转向机制.
1)redis-cluster架构图
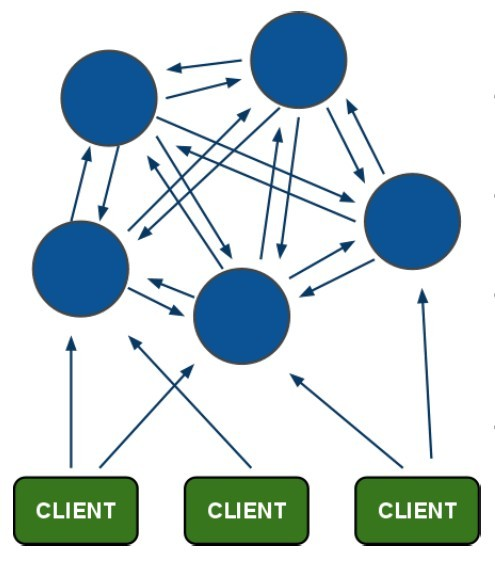
架构细节:
(1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
(2)节点的fail是通过集群中超过半数的节点检测失效时才生效.
(3)客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
(4)redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value2) redis-cluster选举:容错
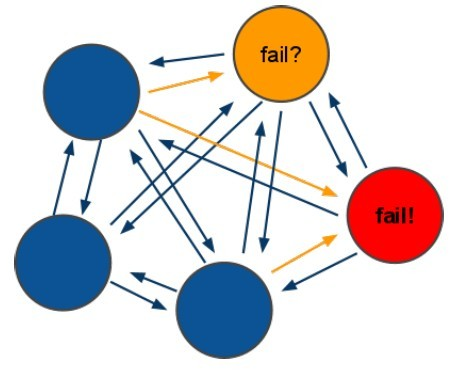
(1)领着选举过程是集群中所有master参与,如果半数以上master节点与master节点通信超过(cluster- node-timeout),认为当前master节点挂掉.
(2):什么时候整个集群不可用(cluster_state:fail),当集群不可用时,所有对集群的操作做都不可用,收到 ((error) CLUSTERDOWN The cluster is down)错误
a:如果集群任意master挂掉,且当前master没有slave.集群进入fail状态,也可以理解成进群的slot映射 [0-16383]不完成时进入fail状态.
b:如果进群超过半数以上master挂掉,无论是否有slave集群进入fail状态.
一、环境
二、搭建集群
1、本机下载redis-3.2.9.tar.gz
2、安装
将redis可执行目录添加到环境变量中,编辑~/.bash_profile添加redis环境变量:
3、创建文件夹
4、拷贝修改配置文件
5、启动6个实例
用redis-cli -c -h -p命令登录
-c是以集群方式登录;
-h后跟主机号 ;
-p后跟端口号。
绑定了127.0.0.1则可以省略-h参数。不加-c则客户端不自动切换。
例如:客户端登录7000端口的,设置的数据应该存放在7001上则会报错请转到7001。而加上-c启动则会自动切换到7001客户端保存。
6、查看redis进程启动状态
7、部署集群
7.1、安装ruby依赖,返回安装软件目录
7.2、将集群管理程序复制到/usr/local/bin/
可以看到redis-trib.rb具有以下功能:
1、create:创建集群
2、check:检查集群
3、info:查看集群信息
4、fix:修复集群
5、reshard:在线迁移slot
6、rebalance:平衡集群节点slot数量
7、add-node:将新节点加入集群
8、del-node:从集群中删除节点
9、set-timeout:设置集群节点间心跳连接的超时时间
10、call:在集群全部节点上执行命令
11、import:将外部redis数据导入集群
8、创建集群