

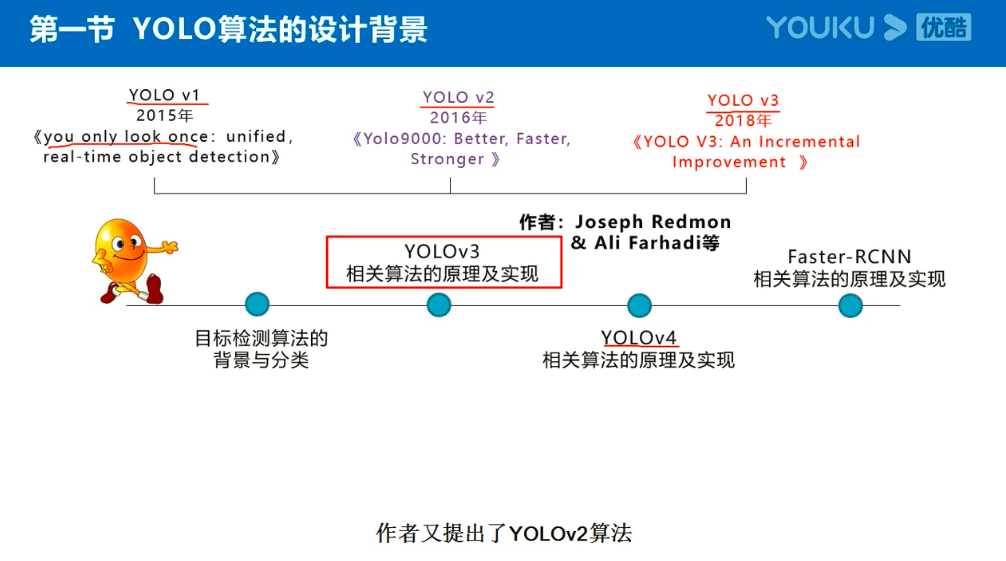
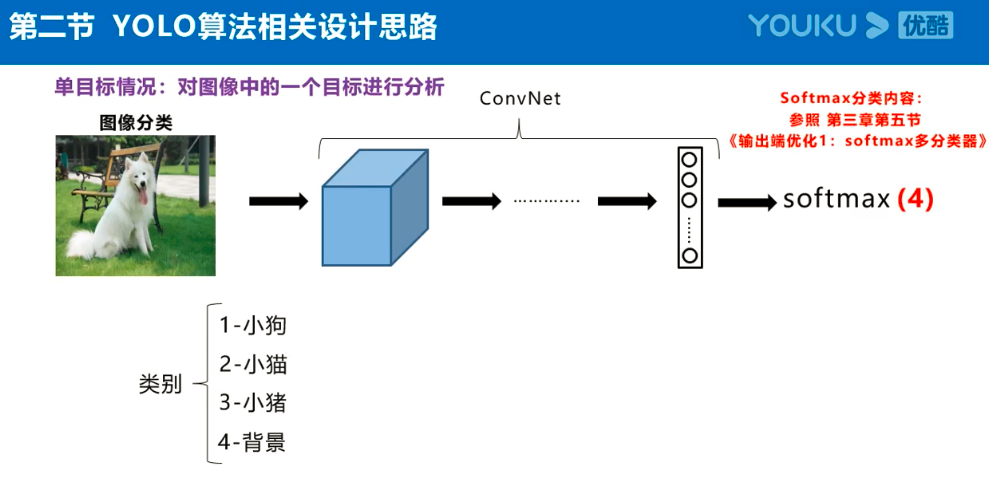
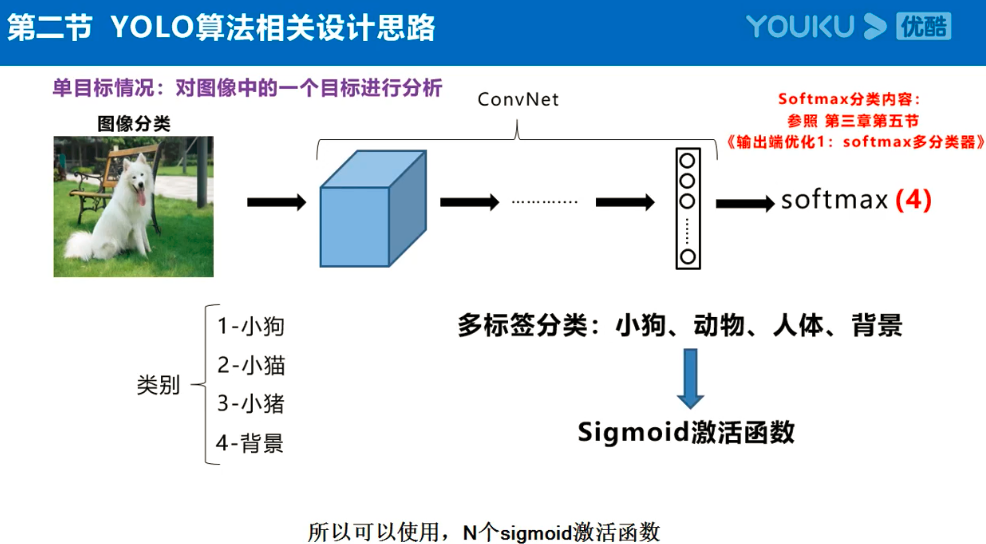
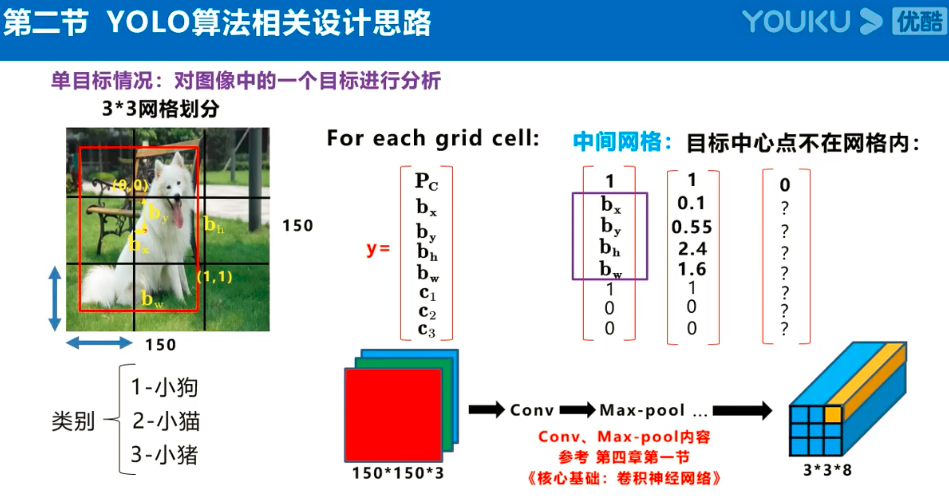
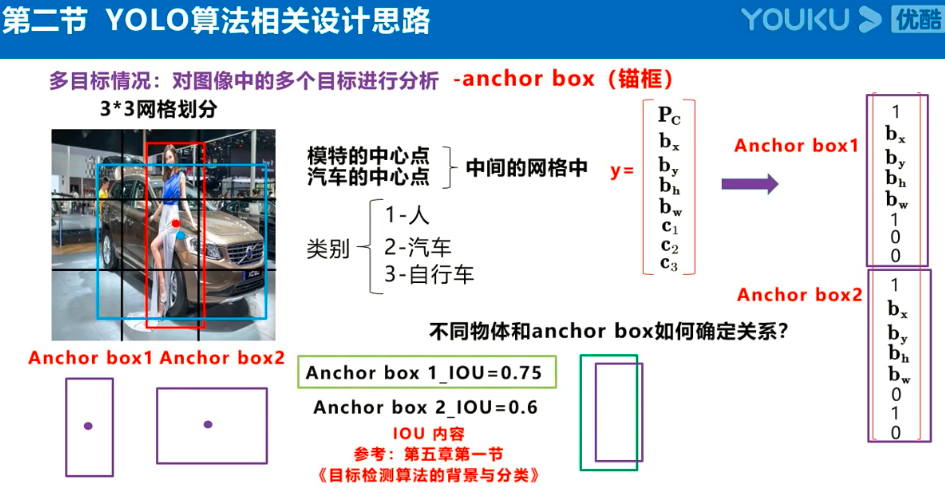
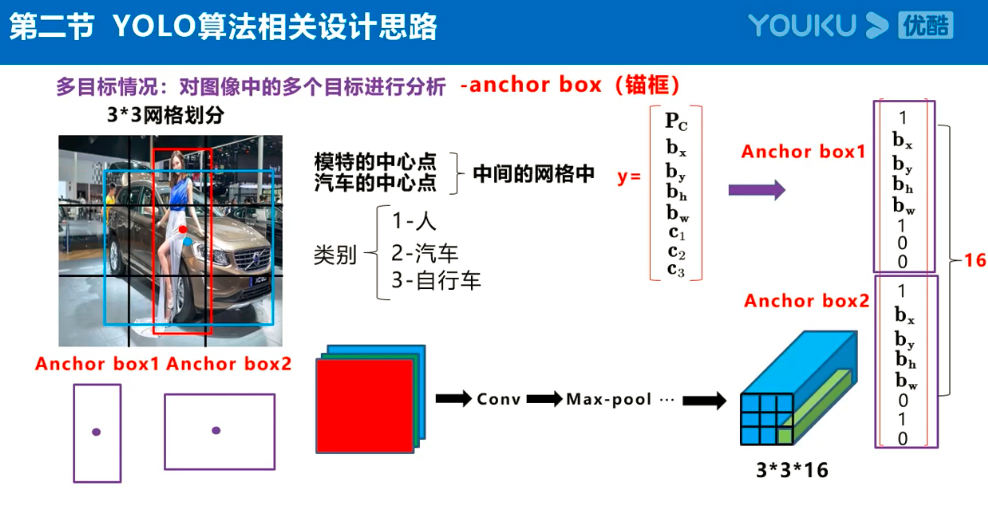
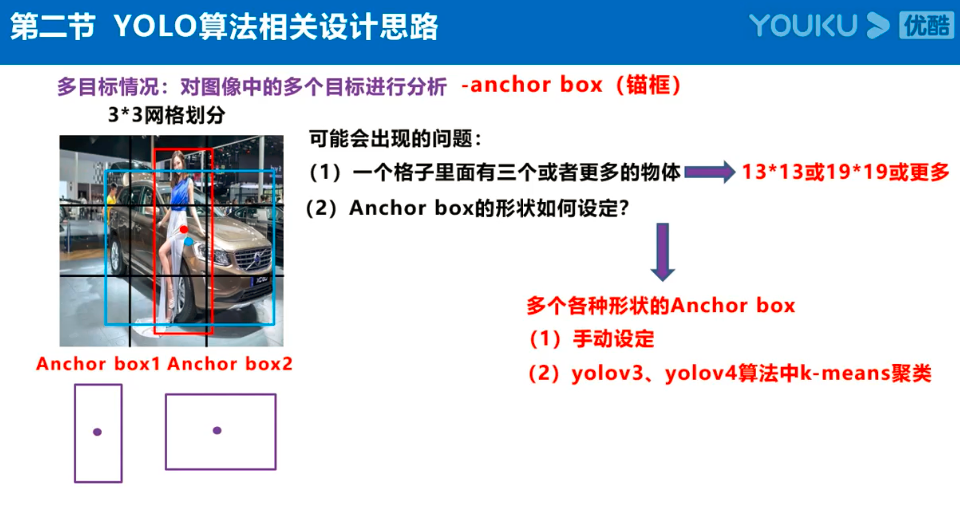
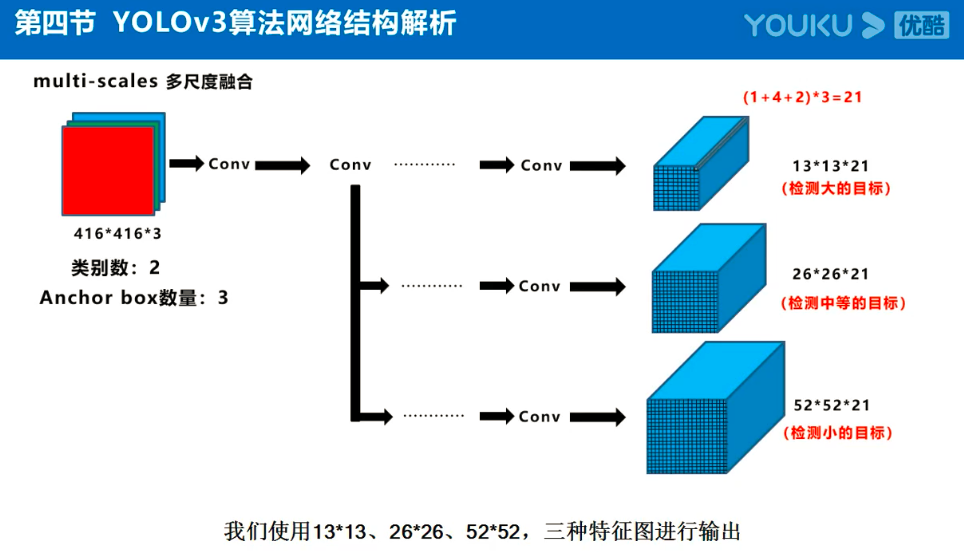
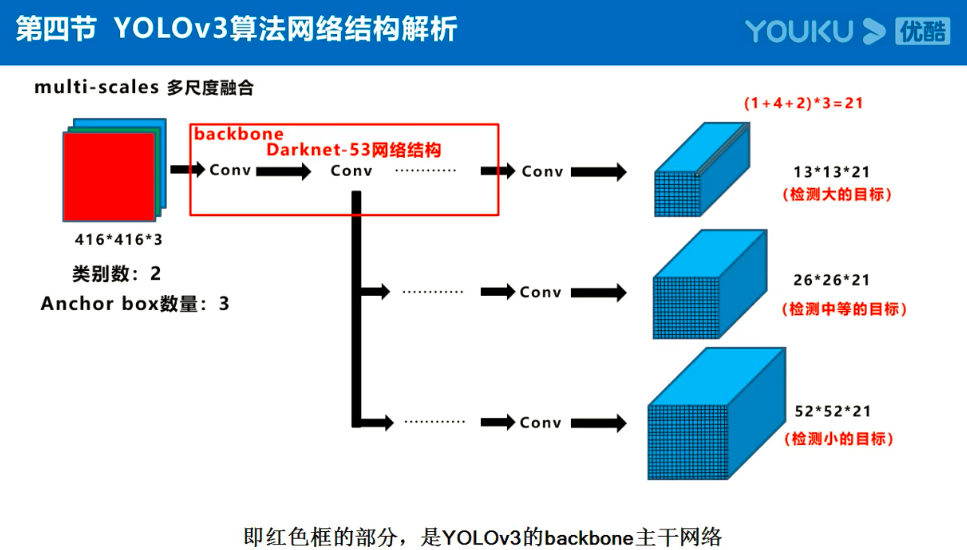
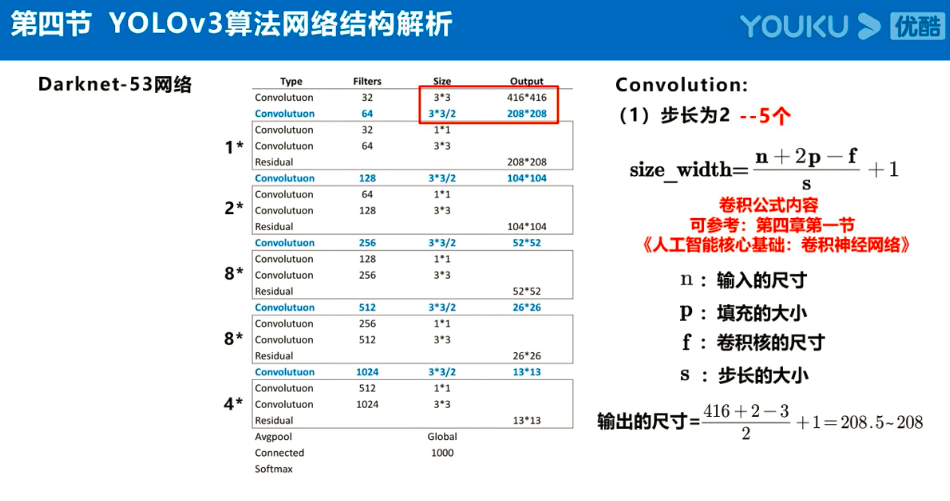
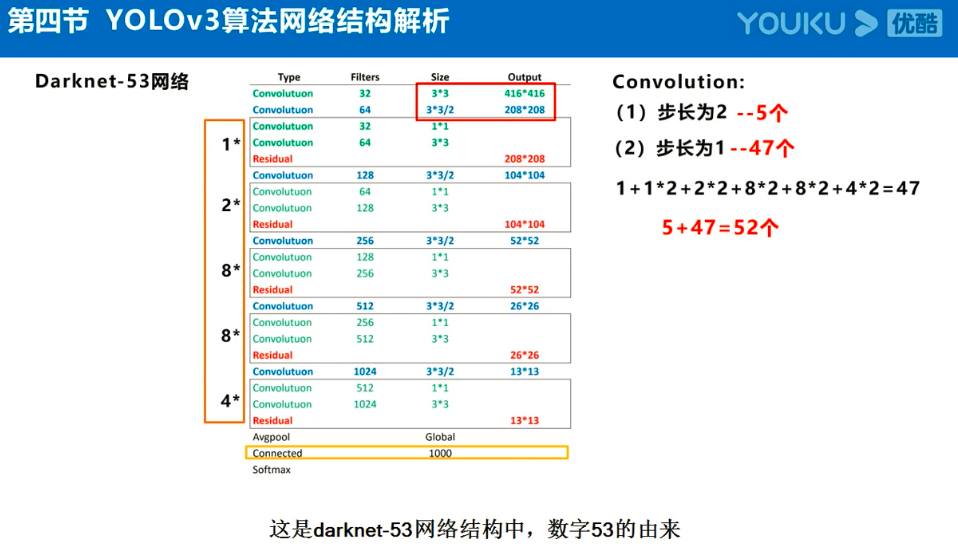
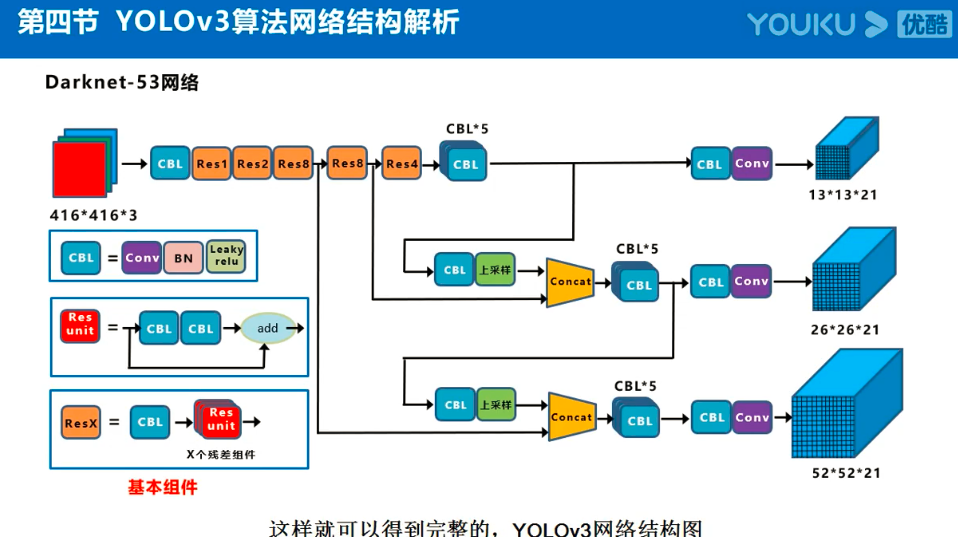
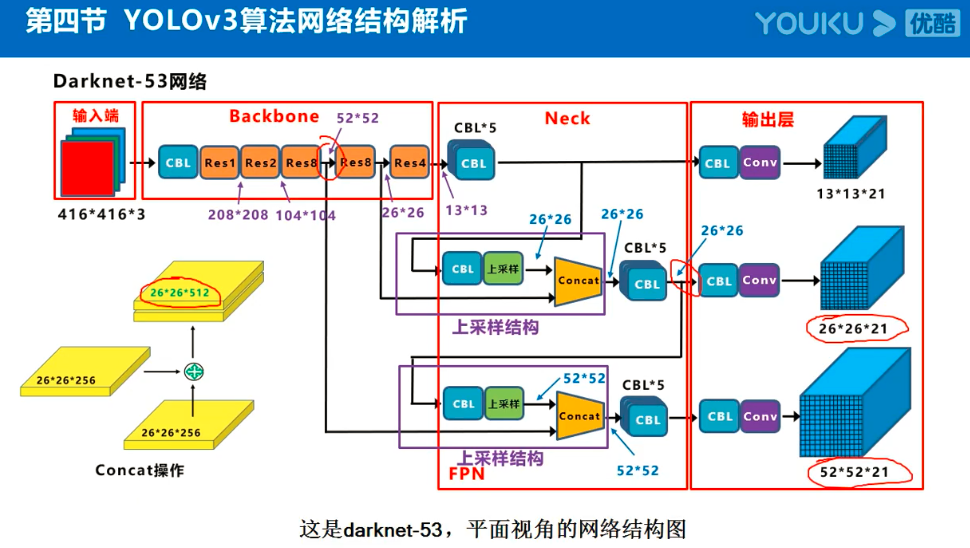
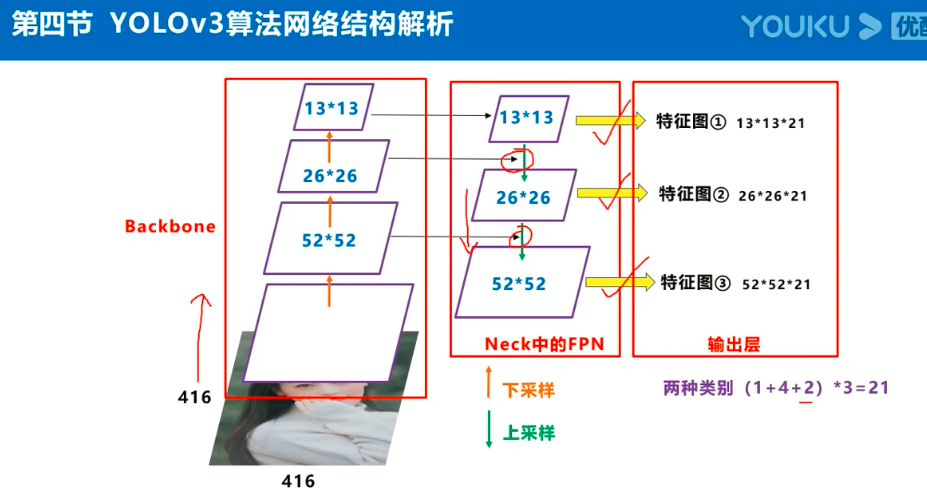
Yolov3的大致框架理解
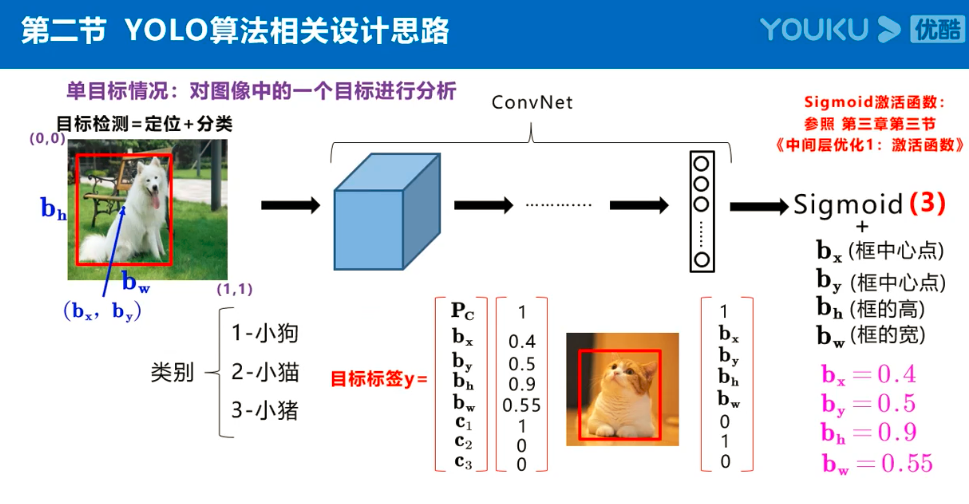

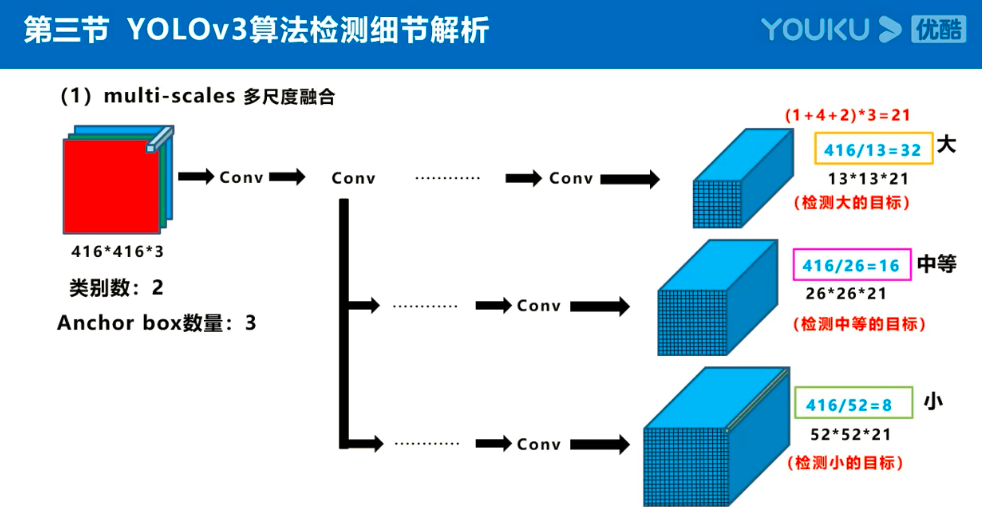
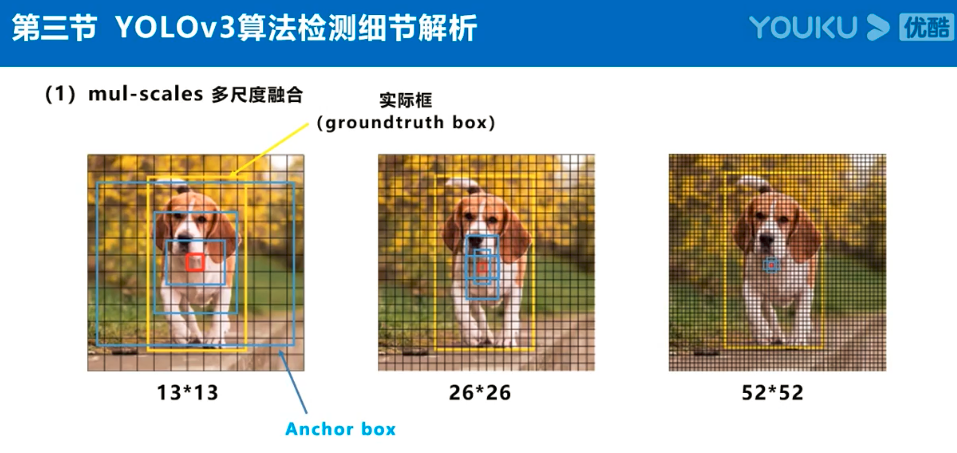


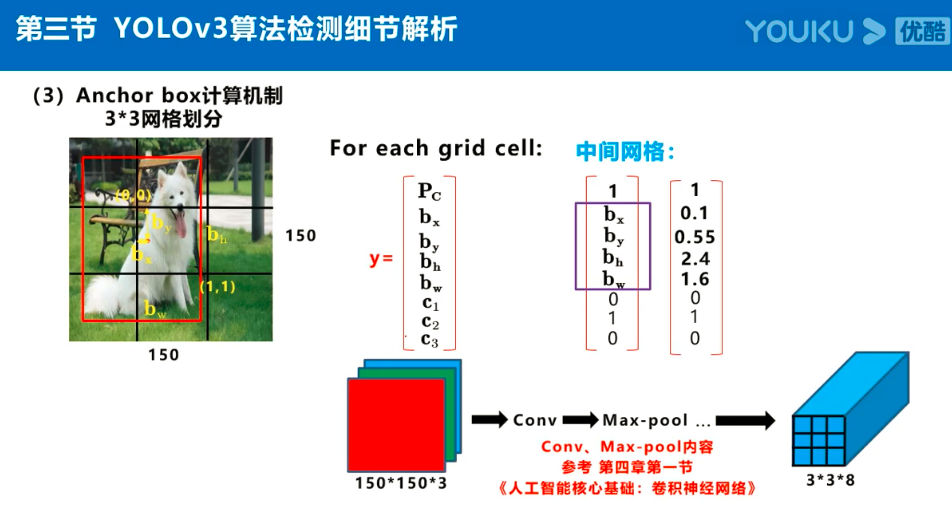
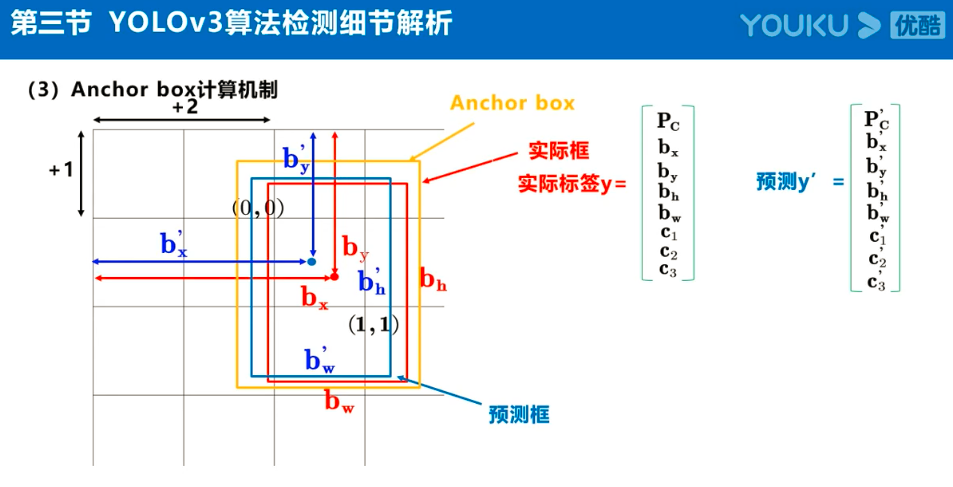
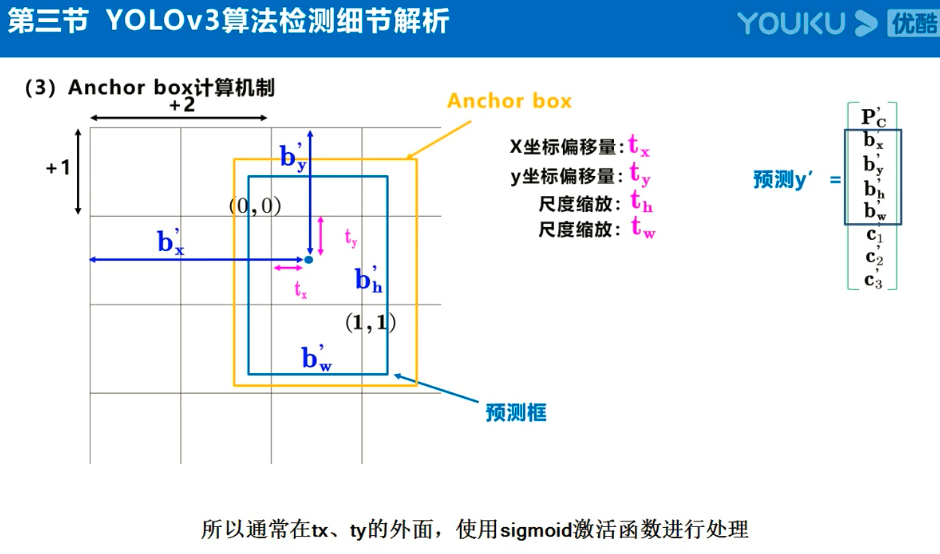
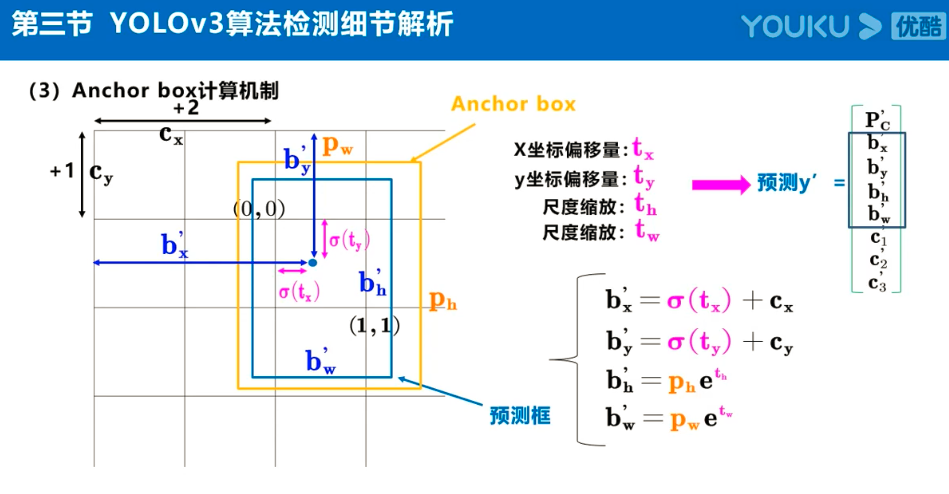
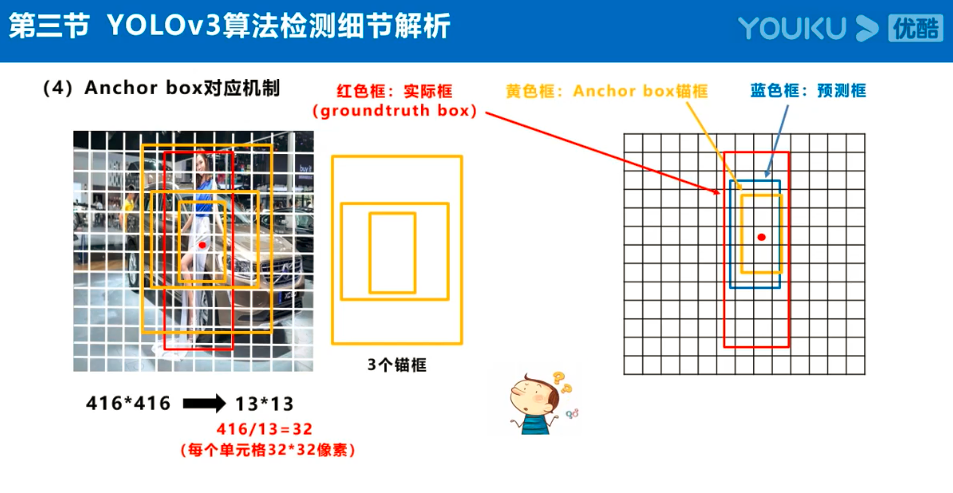
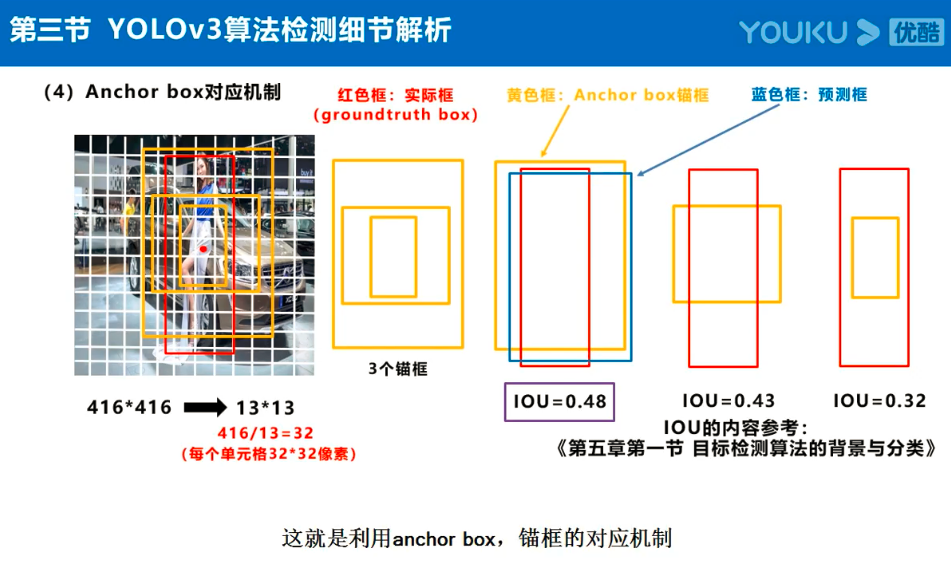
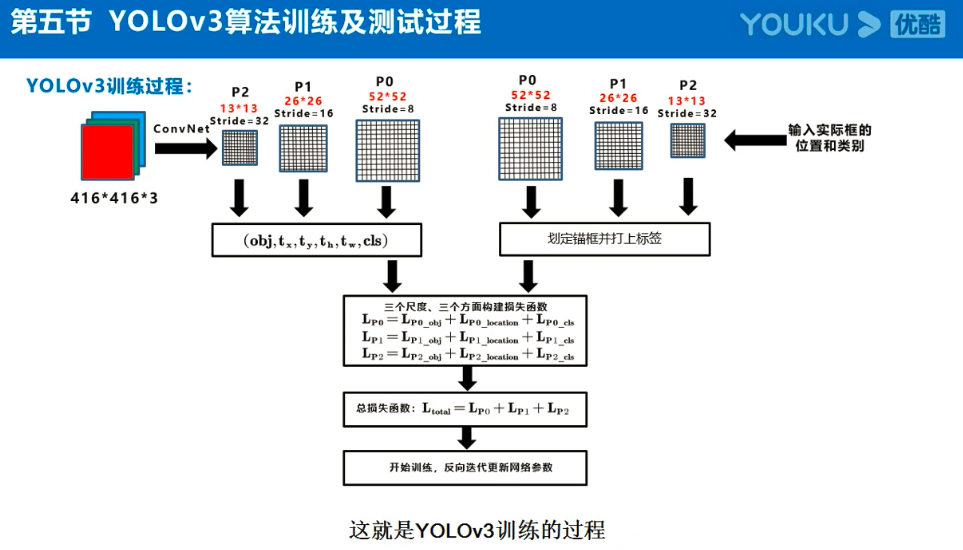
注:Anchor box、预测框、实际框三者之间的关系理解:
在目标检测任务中,通常会以某种规则在图片上生成一系列锚框,将这些锚框当成可能的候选区域。模型对这些候选区域是否包含物体进行预测,如果包含目标物体,则还需要进一步预测出物体所属的类别。还有更为重要的一点是,由于锚框位置是固定的,它不大可能刚好跟物体边界框重合,所以需要在锚框的基础上进行微调以形成能准确描述物体位置的预测框,模型需要预测出微调的幅度。简单的说,锚框对于预测框来说,就相当于网络对其的初始化权重。
预测框即是锚框的微调结果,其结果是更加的贴近真实框,问题就在与如何微调锚框,才能得到较好的结果。
参考: https://blog.csdn.net/lzzzzzzm/article/details/120621582

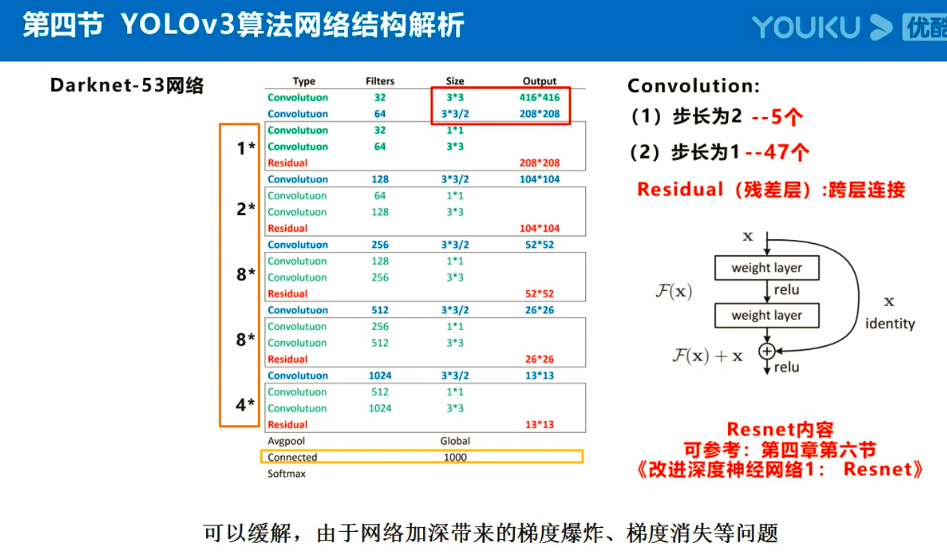
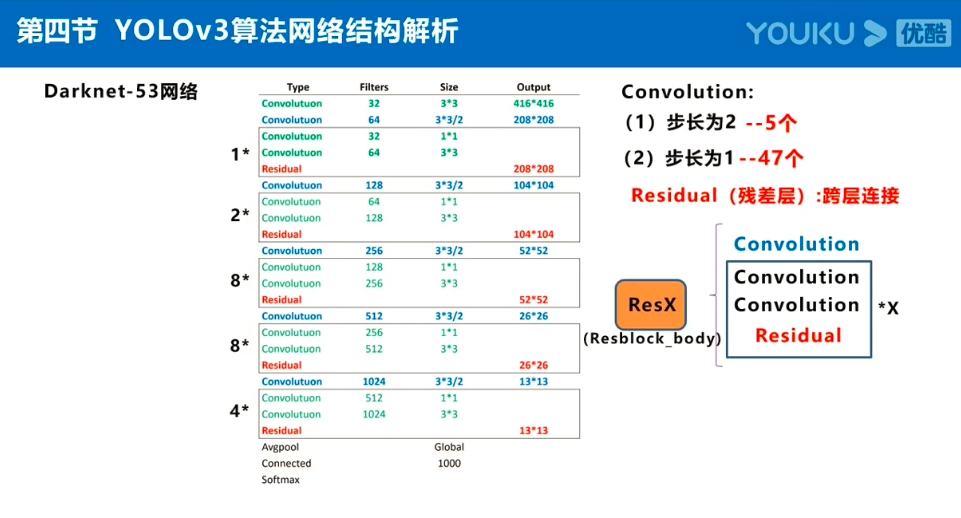
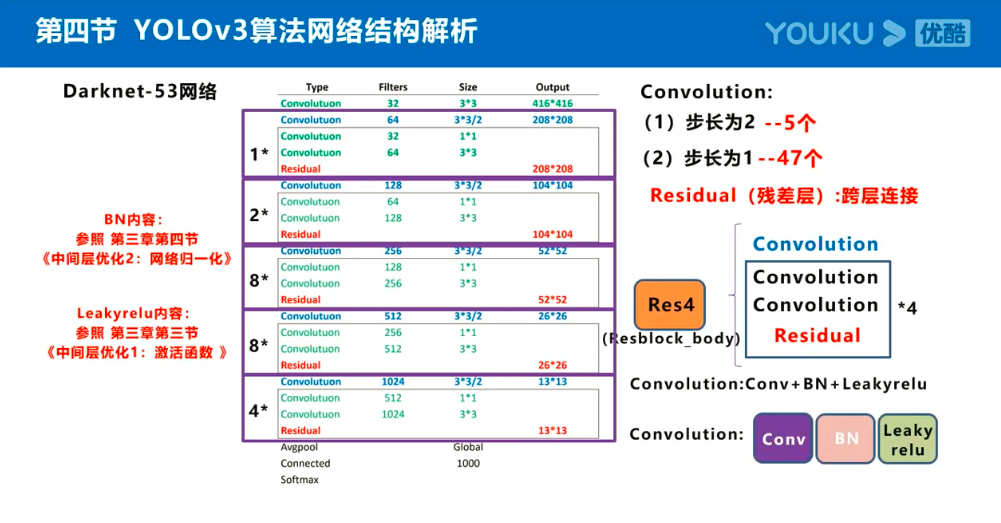
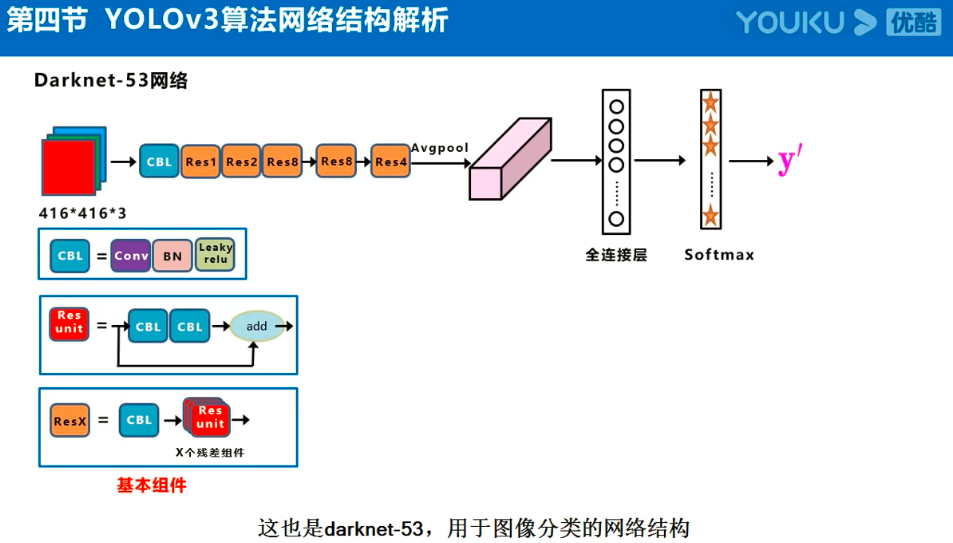
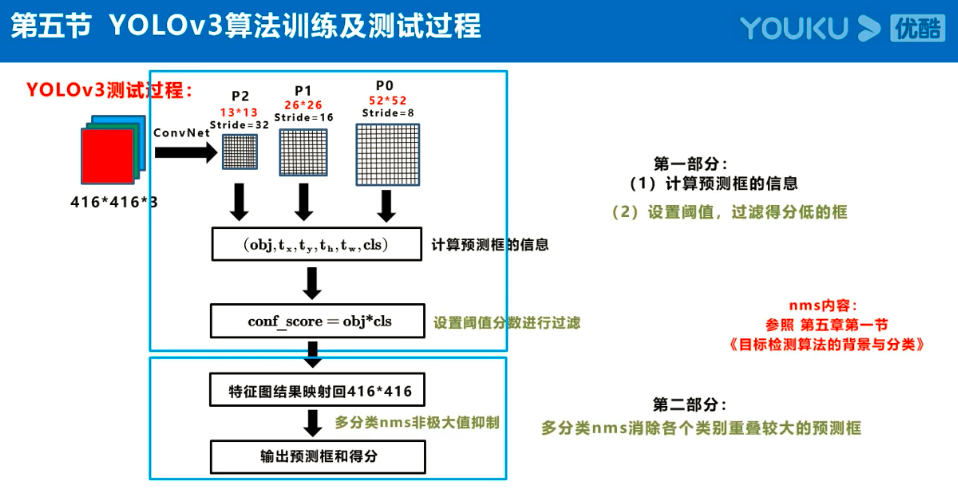

参考:https://www.jiangdabai.com/vcat/%E3%80%8A30%E5%A4%A9%E5%85%A5%E9%97%A8%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E3%80%8B%E7%B3%BB%E5%88%97%E8%AF%BE%E7%A8%8B


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现