

09-MobileNet 图像分类
MobileNet的pytorch代码实现:



1 import torch.nn as nn 2 from collections import OrderedDict 3 import torch 4 # from torchsummary import summary 5 6 #定义基本的Conv_Bn_activate 7 class baseConv(nn.Module): 8 def __init__(self,inchannel,outchannel,kernel_size,stride,groups=1,active=False,bias=False): 9 super(baseConv, self).__init__() 10 11 #定义使用的激活函数 12 if active=='HS': 13 ac=nn.Hardswish 14 elif active=='RE': 15 ac=nn.ReLU6 16 else: 17 ac=nn.Identity 18 19 pad=kernel_size//2 20 self.base=nn.Sequential( 21 nn.Conv2d(in_channels=inchannel,out_channels=outchannel,kernel_size=kernel_size,stride=stride,padding=pad,groups=groups,bias=bias), 22 nn.BatchNorm2d(outchannel), 23 ac() 24 ) 25 def forward(self,x): 26 x=self.base(x) 27 return x 28 29 #定义SE模块 30 class SEModule(nn.Module): 31 def __init__(self,inchannels): 32 super(SEModule, self).__init__() 33 hidden_channel=int(inchannels/4) 34 self.pool=nn.AdaptiveAvgPool2d((1,1)) 35 self.linear1=nn.Sequential( 36 nn.Conv2d(inchannels,hidden_channel,1), 37 nn.ReLU6() 38 ) 39 self.linear2=nn.Sequential( 40 nn.Conv2d(hidden_channel,inchannels,1), 41 nn.Hardswish() 42 ) 43 44 def forward(self,x): 45 out=self.pool(x) 46 out=self.linear1(out) 47 out=self.linear2(out) 48 return out*x 49 50 #定义bneck模块 51 class bneckModule(nn.Module): 52 def __init__(self,inchannels,expand_channels,outchannels,kernel_size,stride,SE,activate): 53 super(bneckModule, self).__init__() 54 self.module=[] #存放module 55 56 if inchannels!=expand_channels: #只有不相等时候才有第一层的升维操作 57 self.module.append(baseConv(inchannels,expand_channels,kernel_size=1,stride=1,active=activate)) 58 59 self.module.append(baseConv(expand_channels,expand_channels,kernel_size=kernel_size,stride=stride,active=activate,groups=expand_channels)) 60 61 #判断是否有se模块 62 if SE==True: 63 self.module.append(SEModule(expand_channels)) 64 65 self.module.append(baseConv(expand_channels,outchannels,1,1)) 66 self.module=nn.Sequential(*self.module) 67 68 #判断是否有残差结构 69 self.residual=False 70 if inchannels==outchannels and stride==1: 71 self.residual=True 72 73 def forward(self,x): 74 out1=self.module(x) 75 if self.residual: 76 return out1+x 77 else: 78 return out1 79 80 81 #定义v3结构 82 class mobilenet_v3(nn.Module): 83 84 def __init__(self,num_classes=10,init_weight=True): 85 super(mobilenet_v3, self).__init__() 86 87 # [inchannel,expand_channels,outchannels,kernel_size,stride,SE,activate] 88 net_config = [[16, 16, 16, 3, 1, False, 'HS'], 89 [16, 64, 24, 3, 2, False, 'RE'], 90 [24, 72, 24, 3, 1, False, 'RE'], 91 [24, 72, 40, 5, 2, True, 'RE'], 92 [40, 120, 40, 5, 1, True, 'RE'], 93 [40, 120, 40, 5, 1, True, 'RE'], 94 [40, 240, 80, 3, 2, False, 'HS'], 95 [80, 200, 80, 3, 1, False, 'HS'], 96 [80, 184, 80, 3, 1, False, 'HS'], 97 [80, 184, 80, 3, 1, False, 'HS'], 98 [80, 480, 112, 3, 1, True, 'HS'], 99 [112, 672, 112, 3, 1, True, 'HS'], 100 [112, 672, 160, 5, 2, True, 'HS'], 101 [160, 960, 160, 5, 1, True, 'HS'], 102 [160, 960, 160, 5, 1, True, 'HS']] 103 104 #定义一个有序字典存放网络结构 105 modules=OrderedDict() 106 modules.update({'layer1':baseConv(inchannel=3,kernel_size=3,outchannel=16,stride=2,active='HS')}) 107 108 #开始配置 109 for idx,layer in enumerate(net_config): 110 modules.update({'bneck_{}'.format(idx):bneckModule(layer[0],layer[1],layer[2],layer[3],layer[4],layer[5],layer[6])}) 111 112 modules.update({'conv_1*1':baseConv(layer[2],960,1,stride=1,active='HS')}) 113 modules.update({'pool':nn.AdaptiveAvgPool2d((1,1))}) 114 115 self.module=nn.Sequential(modules) 116 117 self.classifier=nn.Sequential( 118 nn.Linear(960,1280), 119 nn.Hardswish(), 120 nn.Dropout(p=0.2), 121 nn.Linear(1280,num_classes) 122 ) 123 124 if init_weight: 125 self.init_weight() 126 127 def init_weight(self): 128 for w in self.modules(): 129 if isinstance(w, nn.Conv2d): 130 nn.init.kaiming_normal_(w.weight, mode='fan_out') 131 if w.bias is not None: 132 nn.init.zeros_(w.bias) 133 elif isinstance(w, nn.BatchNorm2d): 134 nn.init.ones_(w.weight) 135 nn.init.zeros_(w.bias) 136 elif isinstance(w, nn.Linear): 137 nn.init.normal_(w.weight, 0, 0.01) 138 nn.init.zeros_(w.bias) 139 140 141 def forward(self,x): 142 out=self.module(x) 143 out=out.view(out.size(0),-1) 144 out=self.classifier(out) 145 return out 146
ClassifyNet_train.py
1 import torch 2 from torch.utils.data import DataLoader 3 from torch import nn, optim 4 from torchvision import datasets, transforms 5 from torchvision.transforms.functional import InterpolationMode 6 7 from matplotlib import pyplot as plt 8 9 10 import time 11 12 from Lenet5 import Lenet5_new 13 from Resnet18 import ResNet18,ResNet18_new 14 from AlexNet import AlexNet 15 from Vgg16 import VGGNet16 16 from Densenet import DenseNet121, DenseNet169, DenseNet201, DenseNet264 17 18 from NIN import NIN_Net 19 from GoogleNet import GoogLeNet 20 from MobileNet_v3 import mobilenet_v3 21 22 def main(): 23 24 print("Load datasets...") 25 26 # transforms.RandomHorizontalFlip(p=0.5)---以0.5的概率对图片做水平横向翻转 27 # transforms.ToTensor()---shape从(H,W,C)->(C,H,W), 每个像素点从(0-255)映射到(0-1):直接除以255 28 # transforms.Normalize---先将输入归一化到(0,1),像素点通过"(x-mean)/std",将每个元素分布到(-1,1) 29 transform_train = transforms.Compose([ 30 transforms.Resize((224, 224), interpolation=InterpolationMode.BICUBIC), 31 # transforms.RandomCrop(32, padding=4), # 先四周填充0,在吧图像随机裁剪成32*32 32 transforms.RandomHorizontalFlip(p=0.5), 33 transforms.ToTensor(), 34 transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)) 35 ]) 36 37 transform_test = transforms.Compose([ 38 transforms.Resize((224, 224), interpolation=InterpolationMode.BICUBIC), 39 # transforms.RandomCrop(32, padding=4), # 先四周填充0,在吧图像随机裁剪成32*32 40 transforms.ToTensor(), 41 transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)) 42 ]) 43 44 # 内置函数下载数据集 45 train_dataset = datasets.CIFAR10(root="./data/Cifar10/", train=True, 46 transform = transform_train, 47 download=True) 48 test_dataset = datasets.CIFAR10(root = "./data/Cifar10/", 49 train = False, 50 transform = transform_test, 51 download=True) 52 53 print(len(train_dataset), len(test_dataset)) 54 55 Batch_size = 64 56 train_loader = DataLoader(train_dataset, batch_size=Batch_size, shuffle = True, num_workers=4) 57 test_loader = DataLoader(test_dataset, batch_size = Batch_size, shuffle = False, num_workers=4) 58 59 # 设置CUDA 60 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") 61 62 # 初始化模型 63 # 直接更换模型就行,其他无需操作 64 # model = Lenet5_new().to(device) 65 # model = ResNet18().to(device) 66 # model = ResNet18_new().to(device) 67 # model = VGGNet16().to(device) 68 # model = DenseNet121().to(device) 69 # model = DenseNet169().to(device) 70 71 # model = NIN_Net().to(device) 72 73 # model = GoogLeNet().to(device) 74 model = mobilenet_v3().to(device) 75 76 # model = AlexNet(num_classes=10, init_weights=True).to(device) 77 print(" mobilenet_v3 train...") 78 79 # 构造损失函数和优化器 80 criterion = nn.CrossEntropyLoss() # 多分类softmax构造损失 81 # opt = optim.SGD(model.parameters(), lr=0.01, momentum=0.8, weight_decay=0.001) 82 opt = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=0.0005) 83 84 # 动态更新学习率 ------每隔step_size : lr = lr * gamma 85 schedule = optim.lr_scheduler.StepLR(opt, step_size=10, gamma=0.6, last_epoch=-1) 86 87 # 开始训练 88 print("Start Train...") 89 90 epochs = 100 91 92 loss_list = [] 93 train_acc_list =[] 94 test_acc_list = [] 95 epochs_list = [] 96 97 for epoch in range(0, epochs): 98 99 start = time.time() 100 101 model.train() 102 103 running_loss = 0.0 104 batch_num = 0 105 106 for i, (inputs, labels) in enumerate(train_loader): 107 108 inputs, labels = inputs.to(device), labels.to(device) 109 110 # 将数据送入模型训练 111 outputs = model(inputs) 112 # 计算损失 113 loss = criterion(outputs, labels).to(device) 114 115 # 重置梯度 116 opt.zero_grad() 117 # 计算梯度,反向传播 118 loss.backward() 119 # 根据反向传播的梯度值优化更新参数 120 opt.step() 121 122 # 100个batch的 loss 之和 123 running_loss += loss.item() 124 # loss_list.append(loss.item()) 125 batch_num+=1 126 127 128 epochs_list.append(epoch) 129 130 # 每一轮结束输出一下当前的学习率 lr 131 lr_1 = opt.param_groups[0]['lr'] 132 print("learn_rate:%.15f" % lr_1) 133 schedule.step() 134 135 end = time.time() 136 print('epoch = %d/100, batch_num = %d, loss = %.6f, time = %.3f' % (epoch+1, batch_num, running_loss/batch_num, end-start)) 137 running_loss=0.0 138 139 # 每个epoch训练结束,都进行一次测试验证 140 model.eval() 141 train_correct = 0.0 142 train_total = 0 143 144 test_correct = 0.0 145 test_total = 0 146 147 # 训练模式不需要反向传播更新梯度 148 with torch.no_grad(): 149 150 # print("=======================train=======================") 151 for inputs, labels in train_loader: 152 inputs, labels = inputs.to(device), labels.to(device) 153 outputs = model(inputs) 154 155 pred = outputs.argmax(dim=1) # 返回每一行中最大值元素索引 156 train_total += inputs.size(0) 157 train_correct += torch.eq(pred, labels).sum().item() 158 159 160 # print("=======================test=======================") 161 for inputs, labels in test_loader: 162 inputs, labels = inputs.to(device), labels.to(device) 163 outputs = model(inputs) 164 165 pred = outputs.argmax(dim=1) # 返回每一行中最大值元素索引 166 test_total += inputs.size(0) 167 test_correct += torch.eq(pred, labels).sum().item() 168 169 print("train_total = %d, Accuracy = %.5f %%, test_total= %d, Accuracy = %.5f %%" %(train_total, 100 * train_correct / train_total, test_total, 100 * test_correct / test_total)) 170 171 train_acc_list.append(100 * train_correct / train_total) 172 test_acc_list.append(100 * test_correct / test_total) 173 174 # print("Accuracy of the network on the 10000 test images:%.5f %%" % (100 * test_correct / test_total)) 175 # print("===============================================") 176 177 fig = plt.figure(figsize=(4, 4)) 178 179 plt.plot(epochs_list, train_acc_list, label='train_acc_list') 180 plt.plot(epochs_list, test_acc_list, label='test_acc_list') 181 plt.legend() 182 plt.title("train_test_acc") 183 plt.savefig('mobilenet_v3_acc_epoch_{:04d}.png'.format(epochs)) 184 plt.close() 185 186 if __name__ == "__main__": 187 188 main()
Loss和acc
1 torch.Size([64, 10]) 2 PyTorch Version: 1.12.1+cu102 3 Torchvision Version: 0.13.1+cu102 4 Load datasets... 5 Files already downloaded and verified 6 Files already downloaded and verified 7 50000 10000 8 mobilenet_v3 train... 9 Start Train... 10 learn_rate:0.010000000000000 11 epoch = 1/100, batch_num = 782, loss = 2.203190, time = 77.231 12 train_total = 50000, Accuracy = 16.68800 %, test_total= 10000, Accuracy = 16.80000 % 13 learn_rate:0.010000000000000 14 epoch = 2/100, batch_num = 782, loss = 1.756507, time = 78.007 15 train_total = 50000, Accuracy = 43.36200 %, test_total= 10000, Accuracy = 42.63000 % 16 learn_rate:0.010000000000000 17 epoch = 3/100, batch_num = 782, loss = 1.250656, time = 78.298 18 train_total = 50000, Accuracy = 59.96600 %, test_total= 10000, Accuracy = 58.98000 % 19 learn_rate:0.010000000000000 20 epoch = 4/100, batch_num = 782, loss = 0.965974, time = 78.311 21 train_total = 50000, Accuracy = 69.11800 %, test_total= 10000, Accuracy = 67.20000 % 22 learn_rate:0.010000000000000 23 epoch = 5/100, batch_num = 782, loss = 0.809132, time = 78.272 24 train_total = 50000, Accuracy = 71.93400 %, test_total= 10000, Accuracy = 69.64000 % 25 learn_rate:0.010000000000000 26 epoch = 6/100, batch_num = 782, loss = 0.687272, time = 78.191 27 train_total = 50000, Accuracy = 79.06600 %, test_total= 10000, Accuracy = 76.36000 % 28 learn_rate:0.010000000000000 29 epoch = 7/100, batch_num = 782, loss = 0.590740, time = 78.254 30 train_total = 50000, Accuracy = 82.03600 %, test_total= 10000, Accuracy = 79.09000 % 31 learn_rate:0.010000000000000 32 epoch = 8/100, batch_num = 782, loss = 0.525424, time = 78.430 33 train_total = 50000, Accuracy = 83.77600 %, test_total= 10000, Accuracy = 80.88000 % 34 learn_rate:0.010000000000000 35 epoch = 9/100, batch_num = 782, loss = 0.471912, time = 78.602 36 train_total = 50000, Accuracy = 84.00200 %, test_total= 10000, Accuracy = 80.42000 % 37 learn_rate:0.010000000000000 38 epoch = 10/100, batch_num = 782, loss = 0.427597, time = 78.734 39 train_total = 50000, Accuracy = 87.13400 %, test_total= 10000, Accuracy = 83.59000 % 40 learn_rate:0.006000000000000 41 epoch = 11/100, batch_num = 782, loss = 0.333546, time = 77.783 42 train_total = 50000, Accuracy = 91.40800 %, test_total= 10000, Accuracy = 85.92000 % 43 learn_rate:0.006000000000000 44 epoch = 12/100, batch_num = 782, loss = 0.303028, time = 78.120 45 train_total = 50000, Accuracy = 89.84200 %, test_total= 10000, Accuracy = 84.55000 % 46 learn_rate:0.006000000000000 47 epoch = 13/100, batch_num = 782, loss = 0.283803, time = 78.504 48 train_total = 50000, Accuracy = 92.21400 %, test_total= 10000, Accuracy = 85.99000 % 49 learn_rate:0.006000000000000 50 epoch = 14/100, batch_num = 782, loss = 0.266681, time = 78.542 51 train_total = 50000, Accuracy = 91.92000 %, test_total= 10000, Accuracy = 85.35000 % 52 learn_rate:0.006000000000000 53 epoch = 15/100, batch_num = 782, loss = 0.256393, time = 78.583 54 train_total = 50000, Accuracy = 92.29400 %, test_total= 10000, Accuracy = 86.37000 % 55 learn_rate:0.006000000000000 56 epoch = 16/100, batch_num = 782, loss = 0.245531, time = 79.005 57 train_total = 50000, Accuracy = 94.00400 %, test_total= 10000, Accuracy = 86.92000 % 58 learn_rate:0.006000000000000 59 epoch = 17/100, batch_num = 782, loss = 0.227954, time = 78.575 60 train_total = 50000, Accuracy = 93.80200 %, test_total= 10000, Accuracy = 86.95000 % 61 learn_rate:0.006000000000000 62 epoch = 18/100, batch_num = 782, loss = 0.218921, time = 77.286 63 train_total = 50000, Accuracy = 93.11600 %, test_total= 10000, Accuracy = 85.96000 % 64 learn_rate:0.006000000000000 65 epoch = 19/100, batch_num = 782, loss = 0.212411, time = 78.182 66 train_total = 50000, Accuracy = 94.77600 %, test_total= 10000, Accuracy = 87.32000 % 67 learn_rate:0.006000000000000 68 epoch = 20/100, batch_num = 782, loss = 0.195866, time = 79.090 69 train_total = 50000, Accuracy = 95.22400 %, test_total= 10000, Accuracy = 87.53000 % 70 learn_rate:0.003600000000000 71 epoch = 21/100, batch_num = 782, loss = 0.128505, time = 78.412 72 train_total = 50000, Accuracy = 97.53800 %, test_total= 10000, Accuracy = 88.64000 % 73 learn_rate:0.003600000000000 74 epoch = 22/100, batch_num = 782, loss = 0.108364, time = 78.324 75 train_total = 50000, Accuracy = 97.78600 %, test_total= 10000, Accuracy = 88.87000 % 76 learn_rate:0.003600000000000 77 epoch = 23/100, batch_num = 782, loss = 0.101737, time = 78.592 78 train_total = 50000, Accuracy = 97.65400 %, test_total= 10000, Accuracy = 88.23000 % 79 learn_rate:0.003600000000000 80 epoch = 24/100, batch_num = 782, loss = 0.103863, time = 77.143 81 train_total = 50000, Accuracy = 97.61200 %, test_total= 10000, Accuracy = 88.13000 % 82 learn_rate:0.003600000000000 83 epoch = 25/100, batch_num = 782, loss = 0.100137, time = 77.128 84 train_total = 50000, Accuracy = 97.76000 %, test_total= 10000, Accuracy = 88.32000 % 85 learn_rate:0.003600000000000 86 epoch = 26/100, batch_num = 782, loss = 0.090839, time = 78.363 87 train_total = 50000, Accuracy = 98.33200 %, test_total= 10000, Accuracy = 88.74000 % 88 learn_rate:0.003600000000000 89 epoch = 27/100, batch_num = 782, loss = 0.098832, time = 77.353 90 train_total = 50000, Accuracy = 97.77800 %, test_total= 10000, Accuracy = 88.31000 % 91 learn_rate:0.003600000000000 92 epoch = 28/100, batch_num = 782, loss = 0.092341, time = 78.656 93 train_total = 50000, Accuracy = 97.42000 %, test_total= 10000, Accuracy = 87.87000 % 94 learn_rate:0.003600000000000 95 epoch = 29/100, batch_num = 782, loss = 0.092752, time = 78.446 96 train_total = 50000, Accuracy = 98.16000 %, test_total= 10000, Accuracy = 88.81000 % 97 learn_rate:0.003600000000000 98 epoch = 30/100, batch_num = 782, loss = 0.089529, time = 78.002 99 train_total = 50000, Accuracy = 98.39800 %, test_total= 10000, Accuracy = 88.99000 % 100 learn_rate:0.002160000000000 101 epoch = 31/100, batch_num = 782, loss = 0.043446, time = 78.491 102 train_total = 50000, Accuracy = 99.53600 %, test_total= 10000, Accuracy = 89.99000 % 103 learn_rate:0.002160000000000 104 epoch = 32/100, batch_num = 782, loss = 0.031758, time = 78.166 105 train_total = 50000, Accuracy = 99.72200 %, test_total= 10000, Accuracy = 90.19000 % 106 learn_rate:0.002160000000000 107 epoch = 33/100, batch_num = 782, loss = 0.027834, time = 78.746 108 train_total = 50000, Accuracy = 99.76000 %, test_total= 10000, Accuracy = 90.02000 % 109 learn_rate:0.002160000000000 110 epoch = 34/100, batch_num = 782, loss = 0.029022, time = 78.762 111 train_total = 50000, Accuracy = 99.80600 %, test_total= 10000, Accuracy = 90.17000 % 112 learn_rate:0.002160000000000 113 epoch = 35/100, batch_num = 782, loss = 0.025741, time = 78.040 114 train_total = 50000, Accuracy = 99.71600 %, test_total= 10000, Accuracy = 89.72000 % 115 learn_rate:0.002160000000000 116 epoch = 36/100, batch_num = 782, loss = 0.026187, time = 79.447 117 train_total = 50000, Accuracy = 99.75200 %, test_total= 10000, Accuracy = 89.92000 % 118 learn_rate:0.002160000000000 119 epoch = 37/100, batch_num = 782, loss = 0.025791, time = 79.629 120 train_total = 50000, Accuracy = 99.68600 %, test_total= 10000, Accuracy = 89.52000 % 121 learn_rate:0.002160000000000 122 epoch = 38/100, batch_num = 782, loss = 0.028179, time = 79.393 123 train_total = 50000, Accuracy = 99.44800 %, test_total= 10000, Accuracy = 89.50000 % 124 learn_rate:0.002160000000000 125 epoch = 39/100, batch_num = 782, loss = 0.029973, time = 79.052 126 train_total = 50000, Accuracy = 99.69000 %, test_total= 10000, Accuracy = 89.52000 % 127 learn_rate:0.002160000000000 128 epoch = 40/100, batch_num = 782, loss = 0.031596, time = 77.546 129 train_total = 50000, Accuracy = 99.80400 %, test_total= 10000, Accuracy = 90.25000 % 130 learn_rate:0.001296000000000 131 epoch = 41/100, batch_num = 782, loss = 0.013997, time = 78.985 132 train_total = 50000, Accuracy = 99.95400 %, test_total= 10000, Accuracy = 90.57000 % 133 learn_rate:0.001296000000000 134 epoch = 42/100, batch_num = 782, loss = 0.008993, time = 79.669 135 train_total = 50000, Accuracy = 99.98200 %, test_total= 10000, Accuracy = 91.05000 % 136 learn_rate:0.001296000000000 137 epoch = 43/100, batch_num = 782, loss = 0.009255, time = 79.048 138 train_total = 50000, Accuracy = 99.98400 %, test_total= 10000, Accuracy = 90.95000 % 139 learn_rate:0.001296000000000 140 epoch = 44/100, batch_num = 782, loss = 0.008394, time = 79.771 141 train_total = 50000, Accuracy = 99.99200 %, test_total= 10000, Accuracy = 90.77000 % 142 learn_rate:0.001296000000000 143 epoch = 45/100, batch_num = 782, loss = 0.007559, time = 79.583 144 train_total = 50000, Accuracy = 99.98400 %, test_total= 10000, Accuracy = 90.54000 % 145 learn_rate:0.001296000000000 146 epoch = 46/100, batch_num = 782, loss = 0.006794, time = 78.839 147 train_total = 50000, Accuracy = 99.99600 %, test_total= 10000, Accuracy = 90.87000 % 148 learn_rate:0.001296000000000 149 epoch = 47/100, batch_num = 782, loss = 0.006278, time = 79.888 150 train_total = 50000, Accuracy = 99.99600 %, test_total= 10000, Accuracy = 90.74000 % 151 learn_rate:0.001296000000000 152 epoch = 48/100, batch_num = 782, loss = 0.006851, time = 78.965 153 train_total = 50000, Accuracy = 99.99600 %, test_total= 10000, Accuracy = 90.61000 % 154 learn_rate:0.001296000000000 155 epoch = 49/100, batch_num = 782, loss = 0.006146, time = 80.085 156 train_total = 50000, Accuracy = 99.99600 %, test_total= 10000, Accuracy = 90.61000 % 157 learn_rate:0.001296000000000 158 epoch = 50/100, batch_num = 782, loss = 0.006881, time = 79.867 159 train_total = 50000, Accuracy = 99.99800 %, test_total= 10000, Accuracy = 90.81000 % 160 learn_rate:0.000777600000000 161 epoch = 51/100, batch_num = 782, loss = 0.004786, time = 80.034 162 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.01000 % 163 learn_rate:0.000777600000000 164 epoch = 52/100, batch_num = 782, loss = 0.004405, time = 79.880 165 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.04000 % 166 learn_rate:0.000777600000000 167 epoch = 53/100, batch_num = 782, loss = 0.004414, time = 79.312 168 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.21000 % 169 learn_rate:0.000777600000000 170 epoch = 54/100, batch_num = 782, loss = 0.004097, time = 78.518 171 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.03000 % 172 learn_rate:0.000777600000000 173 epoch = 55/100, batch_num = 782, loss = 0.004284, time = 79.403 174 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 90.97000 % 175 learn_rate:0.000777600000000 176 epoch = 56/100, batch_num = 782, loss = 0.003366, time = 79.114 177 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 90.99000 % 178 learn_rate:0.000777600000000 179 epoch = 57/100, batch_num = 782, loss = 0.003687, time = 79.430 180 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.11000 % 181 learn_rate:0.000777600000000 182 epoch = 58/100, batch_num = 782, loss = 0.003368, time = 79.565 183 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 90.95000 % 184 learn_rate:0.000777600000000 185 epoch = 59/100, batch_num = 782, loss = 0.003185, time = 79.207 186 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.06000 % 187 learn_rate:0.000777600000000 188 epoch = 60/100, batch_num = 782, loss = 0.003753, time = 79.090 189 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.16000 % 190 learn_rate:0.000466560000000 191 epoch = 61/100, batch_num = 782, loss = 0.002950, time = 79.712 192 train_total = 50000, Accuracy = 99.99800 %, test_total= 10000, Accuracy = 91.00000 % 193 learn_rate:0.000466560000000 194 epoch = 62/100, batch_num = 782, loss = 0.003225, time = 78.063 195 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 90.96000 % 196 learn_rate:0.000466560000000 197 epoch = 63/100, batch_num = 782, loss = 0.002895, time = 79.927 198 train_total = 50000, Accuracy = 99.99800 %, test_total= 10000, Accuracy = 91.31000 % 199 learn_rate:0.000466560000000 200 epoch = 64/100, batch_num = 782, loss = 0.003493, time = 79.865 201 train_total = 50000, Accuracy = 99.99800 %, test_total= 10000, Accuracy = 91.24000 % 202 learn_rate:0.000466560000000 203 epoch = 65/100, batch_num = 782, loss = 0.002798, time = 79.844 204 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.23000 % 205 learn_rate:0.000466560000000 206 epoch = 66/100, batch_num = 782, loss = 0.002702, time = 77.140 207 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.10000 % 208 learn_rate:0.000466560000000 209 epoch = 67/100, batch_num = 782, loss = 0.002807, time = 79.522 210 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.07000 % 211 learn_rate:0.000466560000000 212 epoch = 68/100, batch_num = 782, loss = 0.002869, time = 79.749 213 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.23000 % 214 learn_rate:0.000466560000000 215 epoch = 69/100, batch_num = 782, loss = 0.003123, time = 79.775 216 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.30000 % 217 learn_rate:0.000466560000000 218 epoch = 70/100, batch_num = 782, loss = 0.003094, time = 79.988 219 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 90.94000 % 220 learn_rate:0.000279936000000 221 epoch = 71/100, batch_num = 782, loss = 0.002628, time = 79.398 222 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.04000 % 223 learn_rate:0.000279936000000 224 epoch = 72/100, batch_num = 782, loss = 0.002965, time = 79.861 225 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.05000 % 226 learn_rate:0.000279936000000 227 epoch = 73/100, batch_num = 782, loss = 0.002601, time = 79.949 228 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.26000 % 229 learn_rate:0.000279936000000 230 epoch = 74/100, batch_num = 782, loss = 0.002460, time = 78.649 231 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.18000 % 232 learn_rate:0.000279936000000 233 epoch = 75/100, batch_num = 782, loss = 0.002345, time = 79.085 234 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.15000 % 235 learn_rate:0.000279936000000 236 epoch = 76/100, batch_num = 782, loss = 0.002517, time = 77.715 237 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.18000 % 238 learn_rate:0.000279936000000 239 epoch = 77/100, batch_num = 782, loss = 0.002550, time = 79.459 240 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 90.98000 % 241 learn_rate:0.000279936000000 242 epoch = 78/100, batch_num = 782, loss = 0.002524, time = 80.004 243 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.07000 % 244 learn_rate:0.000279936000000 245 epoch = 79/100, batch_num = 782, loss = 0.002640, time = 78.525 246 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.14000 % 247 learn_rate:0.000279936000000 248 epoch = 80/100, batch_num = 782, loss = 0.002967, time = 79.542 249 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.12000 % 250 learn_rate:0.000167961600000 251 epoch = 81/100, batch_num = 782, loss = 0.002453, time = 79.494 252 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.26000 % 253 learn_rate:0.000167961600000 254 epoch = 82/100, batch_num = 782, loss = 0.002784, time = 79.490 255 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.21000 % 256 learn_rate:0.000167961600000 257 epoch = 83/100, batch_num = 782, loss = 0.002664, time = 78.257 258 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.21000 % 259 learn_rate:0.000167961600000 260 epoch = 84/100, batch_num = 782, loss = 0.002433, time = 79.710 261 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.17000 % 262 learn_rate:0.000167961600000 263 epoch = 85/100, batch_num = 782, loss = 0.002392, time = 78.902 264 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.11000 % 265 learn_rate:0.000167961600000 266 epoch = 86/100, batch_num = 782, loss = 0.003005, time = 79.356 267 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.21000 % 268 learn_rate:0.000167961600000 269 epoch = 87/100, batch_num = 782, loss = 0.002312, time = 79.344 270 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.18000 % 271 learn_rate:0.000167961600000 272 epoch = 88/100, batch_num = 782, loss = 0.002288, time = 79.583 273 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.22000 % 274 learn_rate:0.000167961600000 275 epoch = 89/100, batch_num = 782, loss = 0.002758, time = 77.864 276 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.26000 % 277 learn_rate:0.000167961600000 278 epoch = 90/100, batch_num = 782, loss = 0.002235, time = 77.513 279 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.05000 % 280 learn_rate:0.000100776960000 281 epoch = 91/100, batch_num = 782, loss = 0.002327, time = 79.680 282 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.1 5000 % 283 learn_rate:0.000100776960000 284 epoch = 92/100, batch_num = 782, loss = 0.002182, time = 79.813 285 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.3 3000 % 286 learn_rate:0.000100776960000 287 epoch = 93/100, batch_num = 782, loss = 0.002299, time = 79.420 288 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.2 7000 % 289 learn_rate:0.000100776960000 290 epoch = 94/100, batch_num = 782, loss = 0.002221, time = 79.960 291 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.2 5000 % 292 learn_rate:0.000100776960000 293 epoch = 95/100, batch_num = 782, loss = 0.002262, time = 77.989 294 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.1 7000 % 295 learn_rate:0.000100776960000 296 epoch = 96/100, batch_num = 782, loss = 0.002378, time = 79.152 297 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.2 1000 % 298 learn_rate:0.000100776960000 299 epoch = 97/100, batch_num = 782, loss = 0.002371, time = 79.593 300 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.2 6000 % 301 learn_rate:0.000100776960000 302 epoch = 98/100, batch_num = 782, loss = 0.002325, time = 78.810 303 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.2 1000 % 304 learn_rate:0.000100776960000 305 epoch = 99/100, batch_num = 782, loss = 0.002138, time = 79.787 306 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.1 5000 % 307 learn_rate:0.000100776960000 308 epoch = 100/100, batch_num = 782, loss = 0.002789, time = 79.092 309 train_total = 50000, Accuracy = 100.00000 %, test_total= 10000, Accuracy = 91.0 7000 %
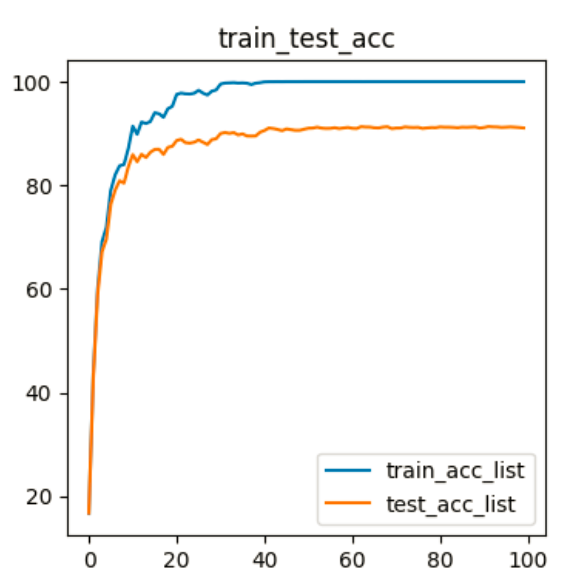
图 mobilenet_v3_acc_epoch_0100


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!
2020-01-13 基于贝叶斯的人脸验证