08_GAN的评价
GAN的评价
在分类或者回归模型中,我们可以使用量化的指标来评价模型训练的好坏,比如:
- 使用分类准确率评价分类模型的性能;
- 使用均方误差评价回归模型的性能。
在生成模型上也需要一个评价指标来量化GAN的生成效果。
GAN指标最主要的有两个:
1. 样本生成的质量
2. 多样性
3.其他的:条件GAN、指标本身有上下界、鲁棒性、最根本的要与人的感知一致
目前应用比较多的GAN评价指标主要的有两个:
1. Inception Score
2. FID (Fréchet Inception Distance)
GAN的评价 Inception Score
我们希望GAN生成图像的质量好。图像质量是一个非常主观的概念,不够清晰的生成图片和足够明晰但不像真实目标的图片均应算作低质量的图片,但计算机不太容易认识到这个问题,我们希望可以设计一个可计算的量化指标,对生成图片的质量做出量化评价。
IS(Inception Score) 将生成的图片送入预训练好Inception模型,例如Inception-V3,它是一个分类器,会对每个输入的图像输出一个1000维的标签向量 ,向量的每一维表示输入样本属于某类别的概率: [0.01, 0, 0.9, …., 0.03, 0] 输出是一个长度为1000的tensor,表示属于某个类别的概率 。如果预训练的Inception-V3训练得足够好,对质量高的生成图像 , Inception-V3可将其以很高的概率分类成某个类,也就是说输出的概率值比较集中的指向某个类别 [0.01, 0, 0.9, …., 0.03, 0] ,而不是概率比较分散:[0.1, 0.12, 0.09, …., 0.03, 0.04] 。
我们可以使用熵来量化该指标,分布相对于类别的熵定义为:
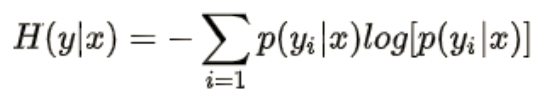
公式中,P(yi|x) 表示 x 属于第 i 类的概率, y表示预测输出。
熵是一种混乱程度的度量,对于质量较低的输入图像,分类器无法给出明确的类别,其熵应比较大,而对于质量越高的图像,其熵应当越小,当预测输出为one-hot分布时,熵达到最小值0。
IS考虑的另一个度量指标即样本的多样性问题,若GAN产生的一批样本{x1,x2,...,xn}多样性比较好,则标签向量 {y1,y2,...,yn}的 类别分布也应该是比较均匀的,也就是说不同类别的概率基本上是相等的(这里假设训练样本的类别是均衡的),则其均值应趋向均匀分布。
也就是说,多样性可以表示为,生成样本会被预测为各个类别,并且各个类别的分布基本一样,不会集中到某个类别:
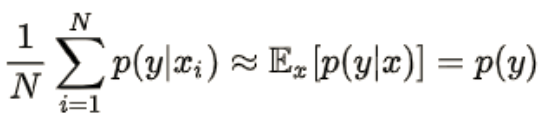
也就是说,我们将各生成样本的预测结果加起来取均值的结果相对于类别的熵越大越好(不会集中到某些类别)。
p(y)相对于类别的熵为 :

将图像质量和多样性两个指标综合考虑,可以将样本和标签的互信息 设计为生成模型的评价指标,互信息描述了给定一个随机变量后,另一个随机变量的不确定性减少程度。又被称为信息增益,即:

在不确定 x 前,边缘分布 P(y)相对于类别的熵比较大,标签 y(可能接近均匀分布)不确定程度比较大;当给定 x 后,条件分布p(y|x) 相对于类别的熵会减小,标签y 的不确定性降低(可能接近one-hot分布),不确定程度会减少,并且其差值越大,说明样本的质量越好。
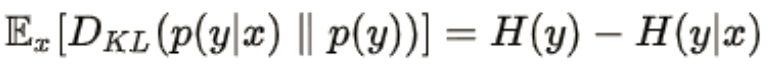
这是使用KL散度代替熵运算 。 KL散度表示两个分布的差值,当KL散度值越大时,表示两个分布的差异越大; KL散度值越小,分布的差异越小,上图中计算所有样本的KL散度求平均.
为了便于计算,添加指数项,最终的IS定义成如下形式:
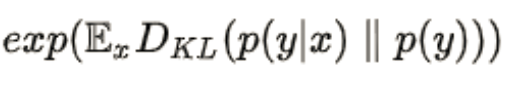
也就是:
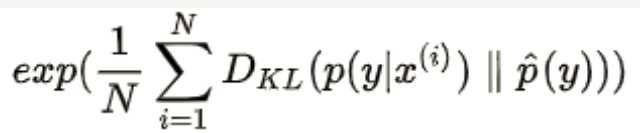
Inception Score缺陷
1)当GAN发生过拟合时,生成器只“记住了”训练集的样本,泛化性能差,但是IS无法检测到这个问题,由于样本质量和多样性都比较好, IS仍然会很高。
2.) 由于Inception-V3是在ImageNet上训练得到的,故IS会偏爱ImageNet中的物体类别,而不是注重真实性。 GAN生成的图片无论如何逼真,只要它的类别不存在于ImageNet中,IS也会比较低。
3.) 若GAN生成类别的多样性足够,但是类内发生模式崩溃问题, IS无法探测。
4) IS只考虑生成器的分布而忽略数据集的分布 。
5) IS是一种伪度量。
6) IS的高低会受到图像像素的影响。
FID指标
FID(Fréchet Inception Distance)是一种评价GAN的指标,于2017年提出,用于计算为真实图像和生成的图像计算的特征向量之间的距离。两组图像越相似,说明生成效果越好。
FID总结了这两组在使用用于图像分类的 inception v3 模型计算的原始图像的计算机视觉特征统计数据方面的相似程度。分数越低,表示两组图像更相似,或者具有更相似的统计数据,满分为0.0表示两组图像相同。
FID评分用于评估生成对抗网络生成的图像的质量,并且较低的分数已被证明与较高质量的图像具有良好的相关性。
FID分数是由Martin Heusel等人在他们2017年的论文中提出和使用的,题为《GANs Trained by a Two Time-Scale Update Rule Converge to a Nash Equilibrium》
FID是作为对现有 Inception score(IS)的改进而提出的,它比Inception Score更好地捕获了生成的图像与真实图像的相似性。FID评分的目标是根据生成图像集合的统计数据与目标域中真实图像集合的统计数据进行比较来评估生成图像。
FID指标的计算
FID与 IS一样,使用 inception v3 模型。具体而言,使用预训练的模型提取真实图像和生成图像的特征(不需计算类别输出),并假设该抽象特征符合多元高斯分布,估计生成样本高斯分布的均值ug和方差vg ,以及训练样本均值udata和方差vdata ,计算两个高斯分布的弗雷歇距离,此距离值即FID:
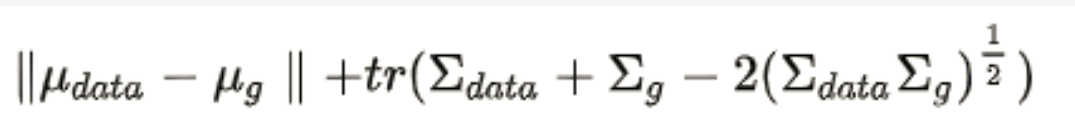
FID越低,表示图像质量越好;相反,分数越高表示图像质量越低,并且关系可能是线性的。
FID 分数的计算流程:
首先加载预先训练的 Inception v3 模型,移除模型的输出层,最后一个池化层作为输出层。此输出层输出长度为2048的特征张量。这称为图像的编码向量或特征向量。
分别提取到真是图像的特征向量和生成图像的特征向量。这是两个包含长度为2048的特征向量的集合,分别表示真实图像和生成的图像。
然后使用从论文中得出的以下等式计算FID分数: 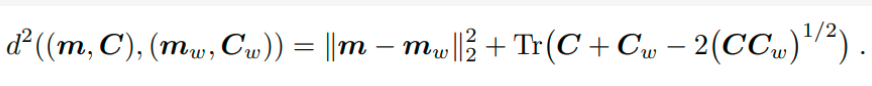
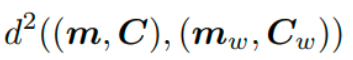 表示它是一个距离并具有平方单位。
表示它是一个距离并具有平方单位。
m和mw是指真实和生成的图像的特征平均值,均为长度2048个元素的向量,其中每个元素都是在图像中观察到的平均特征 .
c和cw是真实图像特征和生成图像特征向量的协方差矩阵,通常称为 sigma。
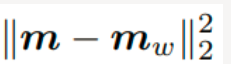 是指两个平均向量之间的平方差。 Tr 是指线性代数迹运算,例如,沿方阵主对角线的元素之和
是指两个平均向量之间的平方差。 Tr 是指线性代数迹运算,例如,沿方阵主对角线的元素之和
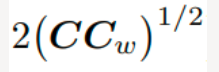 是平方矩阵的平方根,作为两个协方差矩阵之间的乘积平方根。
是平方矩阵的平方根,作为两个协方差矩阵之间的乘积平方根。

pip install pytorch-fid # 先安装
计算:
python -m pytorch_fid path/to/dataset1 path/to/dataset2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号