

07_WGAN
GAN现在是热门的研究课题,一般有两种类型的GAN研究方向:一种是在各种各样的问题中应用GAN,另一种是试图稳定GAN的训练。 稳定GAN的训练过程是一个非常重要的事情 。
原始GAN训练过程中经常遇到的问题:
- 模式崩溃, 生成器生成非常窄的分布,仅覆盖数据分布中的单一模式。 模式崩溃的含义是生成器只能生成非常相似的样本(例如, MNIST中的单个数字),即生成的样本不是多样的。
- 没有指标可以告诉我们收敛情况。 生成器和判别器的loss并没有告诉我们任何收敛相关信息。当然,我们可以通过不时地查看生成器生成的数据来监控训练进度。但是,这是一个手动过程。因此, 我们需要有一个可解释的指标可以告诉我们有关训练的进度。
原始GAN形式的问题,一句话概括:判别器越好,生成器梯度消失越严重。 GAN网络训练的重点在于均衡生成器与判别器,若判别器太强, loss没有再下降,生成器学习不到东西,生成图像的质量便不会再有提升。 在最优判别器的下,我们可以把原始GAN定义的生成器loss等价变换为最小化真实分布与生成分布之间的JS散度。我们越训练判别器,它就越接近最优,最小化生成器的loss也就会越近似于最小化真实分布与生成分布之间的JS散度。
关键点就在于如何评价生成图片和真实图片之间的距离 :
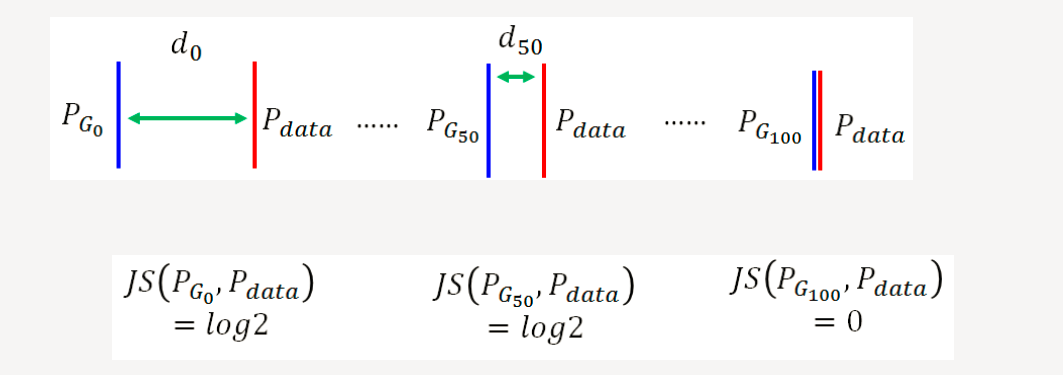
JS散度存在的问题
如果希望两个分布之间越接近它们的JS散度越小,我们通过优化JS散度就能将生成分布拉向真实分布,最终以假乱真。这个希望在两个分布有所重叠的时候是成立的,但是如果两个分布完全没有重叠的部分,或者它们重叠的部分可忽略,那它们的JS散度就一直是 log2 。
原始GAN存在的问题
在原始GAN的(近似)最优判别器下,生成器loss面临梯度消失问题。也面临优化目标荒谬、梯度不稳定、对多样性与准确性惩罚不平衡导致mode collapse问题。
原始GAN问题的根源可以归结为两点:
一是等价优化的距离衡量(JS散度)不合理,
二是生成器随机初始化后的生成分布很难与真实分布有不可忽略的重叠。
Wasserstein GAN(WGAN)就是希望解决上述两个问题。
注:WGAN(Wasserstein GAN)论文:https://arxiv.org/abs/1701.07875
解决原始GAN问题的方法:
解决问题的关键在于使用:Wasserstein距离;
衡量两个分布之间的距离Wasserstein距离 优越性在于:即使两个分布没有任何重叠,也可以反应他们之间的距离.
Wasserstein距离
P和Q为两个分布: P分布为一堆土, Q分布为要移到的目标,那么要移动P达到Q,哪种距离更小呢?
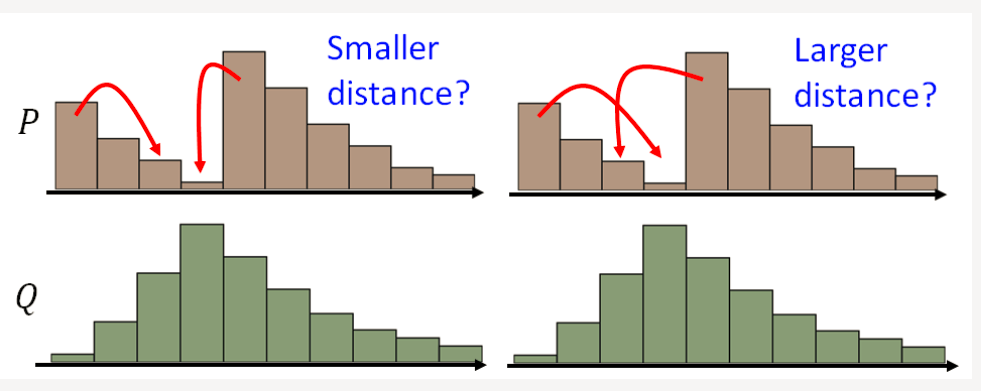
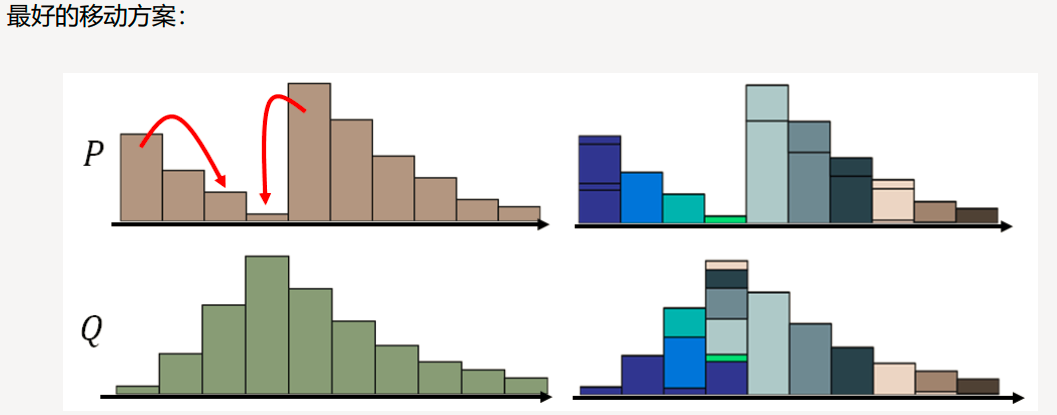
使用Wasserstein距离, 无论两个分布多远,都有梯度,都是可以更新的.
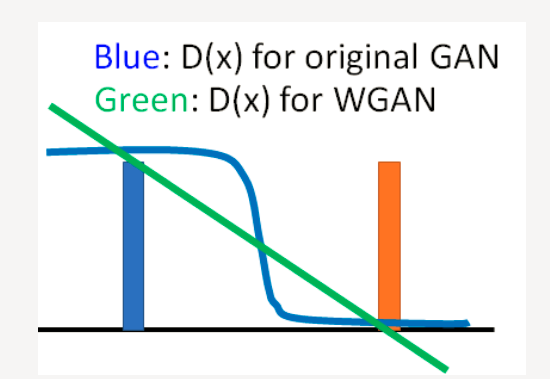
WGAN的设计
原始的生成对抗网络,所要优化的目标函数为:
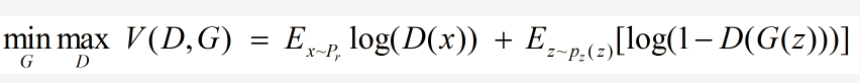
此目标函数可以分为两部分来看:
①固定生成器 G,优化判别器 D, 则上式可以写成如下形式:
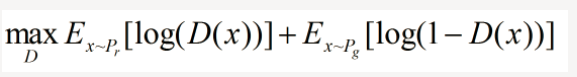
可以转化为最小化形式:
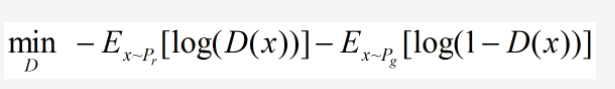
②固定判别器 D,优化生成器 G,舍去前面的常数,相当于最小化:
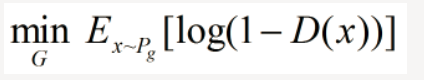
也相当于最小化:
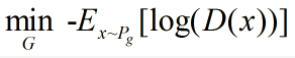
我们要构建一个判别器 D,使得 D 的参数不超过某个固定的常数,最后一层是非线性层,并且使下面式子最大化:
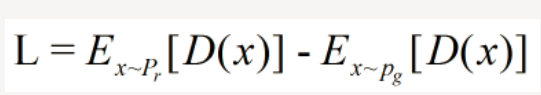
这是一种数学的近似,同要求梯度变化的不要太猛烈。
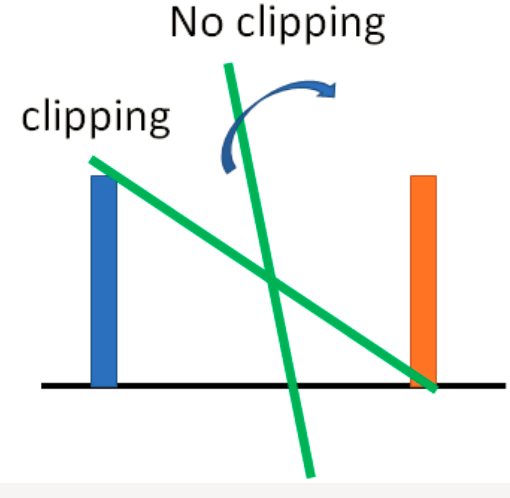
那么怎么梯度更新呢?因为D有了限制,无法直接利用SGD。这里引入一种方法: Weight clipping就是强制令权重w 限制在c ~ -c之间。在参数更新后,如果w>c,则令w=c, 如果w<-c,则令w=-c。
WGAN的实现
WGAN与原始GAN第一种形式相比,只改了四点:
一、判别器最后一层去掉sigmoid
二、生成器和判别器的loss不取log
三、每次更新判别器的参数之后把它们的值截断到不超过一个固定常数c
四、不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,但是RMSProp适合梯度不稳定的情况。
WGAN本作引入了Wasserstein距离,由于它相对KL散度与JS散度具有优越的平滑特性,理论上可以解决梯度消失问题。接着通过数学变换将Wasserstein距离写成可求解的形式,利用一个参数数值范围受限的判别器神经网络来较大化这个形式,就可以近似Wasserstein距离。
WGAN既解决了训练不稳定的问题,也提供了一个可靠的训练进程指标,而且该指标确实与生成样本的质量高度相关。
WGAN的代码实现(pytorch)



1 import torch 2 import torch.nn as nn 3 import torch.nn.functional as F 4 import torch.optim as optim 5 import numpy as np 6 import matplotlib.pyplot as plt 7 import torchvision 8 from torchvision import transforms 9 10 11 12 transform = transforms.Compose([ 13 transforms.ToTensor(), 14 transforms.Normalize(mean=0.5, std=0.5) 15 ]) 16 17 train_ds = torchvision.datasets.MNIST('data/', 18 train=True, 19 transform=transform, 20 download=True) 21 22 train_dl = torch.utils.data.DataLoader(train_ds, batch_size=512, shuffle=True) 23 24 #定义生成器 25 26 # 使用长度为 100 的noise作为输入,也可以使用torch.randn(batchsize, 100, 1, 1) 27 # 生成 1*28*28 28 class Generator(nn.Module): 29 def __init__(self): 30 super(Generator, self).__init__() 31 self.linear1 = nn.Linear(100, 256*7*7) 32 self.bn1 = nn.BatchNorm1d(256*7*7) 33 self.deconv1 = nn.ConvTranspose2d(256, 128, 34 kernel_size=(3, 3), 35 stride=1, 36 padding=1) # (128, 7, 7) 37 self.bn2 = nn.BatchNorm2d(128) 38 39 self.deconv2 = nn.ConvTranspose2d(128, 64, 40 kernel_size=(4, 4), 41 stride=2, 42 padding=1) # (64, 14, 14) 43 self.bn3 = nn.BatchNorm2d(64) 44 45 self.deconv3 = nn.ConvTranspose2d(64, 1, 46 kernel_size=(4, 4), 47 stride=2, 48 padding=1) # (1, 28, 28) 49 50 def forward(self, x): 51 x = F.relu(self.linear1(x)) 52 x = self.bn1(x) 53 x = x.view(-1, 256, 7, 7) 54 x = F.relu(self.deconv1(x)) 55 x = self.bn2(x) 56 x = F.relu(self.deconv2(x)) 57 x = self.bn3(x) 58 x = torch.tanh(self.deconv3(x)) 59 return x 60 61 # input: 1, 28, 28的图片 62 class Discriminator(nn.Module): 63 def __init__(self): 64 super(Discriminator, self).__init__() 65 self.conv1 = nn.Conv2d(1, 64, kernel_size=3, stride=2) 66 self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=2) 67 self.bn = nn.BatchNorm2d(128) 68 self.fc = nn.Linear(128*6*6, 1) 69 def forward(self, x): 70 x = F.dropout2d(F.leaky_relu(self.conv1(x))) 71 x = F.dropout2d(F.leaky_relu(self.conv2(x))) # (batch, 128, 6, 6) 72 x = self.bn(x) 73 x = x.view(-1, 128*6*6) # (batch, 128, 6, 6)--> (batch, 128*6*6) 74 x = self.fc(x) 75 return x 76 77 device = "cuda" if torch.cuda.is_available() else "cpu" 78 #device = "cpu" 79 gen = Generator().to(device) 80 dis = Discriminator().to(device) 81 82 #loss_fn = torch.nn.BCELoss() # 损失函数 83 d_optimizer = torch.optim.RMSprop(dis.parameters(), lr=2e-4) 84 g_optimizer = torch.optim.RMSprop(gen.parameters(), lr=2e-4) 85 86 def generate_and_save_images(model, epoch, test_input): 87 predictions = np.squeeze(model(test_input).cpu().numpy()) 88 fig = plt.figure(figsize=(4, 4)) 89 for i in range(predictions.shape[0]): 90 plt.subplot(4, 4, i+1) 91 plt.imshow((predictions[i] + 1)/2, cmap='gray') 92 plt.axis('off') 93 plt.savefig('image_at_epoch_{:04d}.png'.format(epoch)) 94 plt.show() 95 96 test_input = torch.randn(16, 100, device=device) 97 98 D_loss = [] 99 G_loss = [] 100 101 #开始训练 102 for epoch in range(30): 103 D_epoch_loss=0 104 G_epoch_loss=0 105 count = len(train_dl.dataset) 106 for step, (img, _) in enumerate(train_dl): 107 img = img.to(device) 108 size=img.shape[0] 109 random_seed = torch.randn(size, 100, device=device) 110 111 112 for p in dis.parameters(): 113 p.data.clamp_(-0.01, 0.01) 114 d_optimizer.zero_grad() 115 real_output = dis(img).mean() 116 117 generated_img = gen(random_seed) 118 fake_output = dis(generated_img.detach()).mean() 119 120 disc_loss = -real_output + fake_output 121 disc_loss.backward() 122 d_optimizer.step() 123 124 g_optimizer.zero_grad() 125 fake_output = dis(generated_img) 126 gen_loss = -torch.mean(fake_output) 127 gen_loss.backward() 128 g_optimizer.step() 129 130 with torch.no_grad(): 131 D_epoch_loss += disc_loss.item() 132 G_epoch_loss += gen_loss.item() 133 with torch.no_grad(): 134 D_epoch_loss /= count 135 G_epoch_loss /= count 136 D_loss.append(D_epoch_loss) 137 G_loss.append(G_epoch_loss) 138 generate_and_save_images(gen, epoch, test_input) 139 print('Epoch: ', epoch) 140 141 plt.plot(D_loss, label='D_loss') 142 plt.plot(G_loss, label='G_loss') 143 plt.legend()


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具