05_SGAN
SGAN
SSGAN是半监督学习生成对抗网络 (SGAN(ssgan)Semi-Supervised Learning with Generative Adversarial Networks ),初衷是利用GAN生成器生成的样本来改进和提高图像分类任务的性能。在实际的应用中有大量的数据是不带标签的,带标签的数据只占一小部分;充分的利用不标签的“无监督数据”可以提高分类模型泛化和性能。 事实上,在非常多的场景中,带有标签的数据并不容易获 得。半监督学习可以在只需要一小部分的标记数据取得非常好的分类效果。
半监督学习算法代表了监督和非监督算法的中间地带,这些算法操作的数据有一些标签,但大部分是没有标签的。一般的,如果仅选择有监督学习的方式,只对带有标签的数据进行操作,这将极大地减小数据集的规模。SSGAN为我们提供了一个使用没有标签数据增强分类器的思路。
SGAN论文地址:https://arxiv.org/pdf/1606.01583.pdf
SGAN的设计
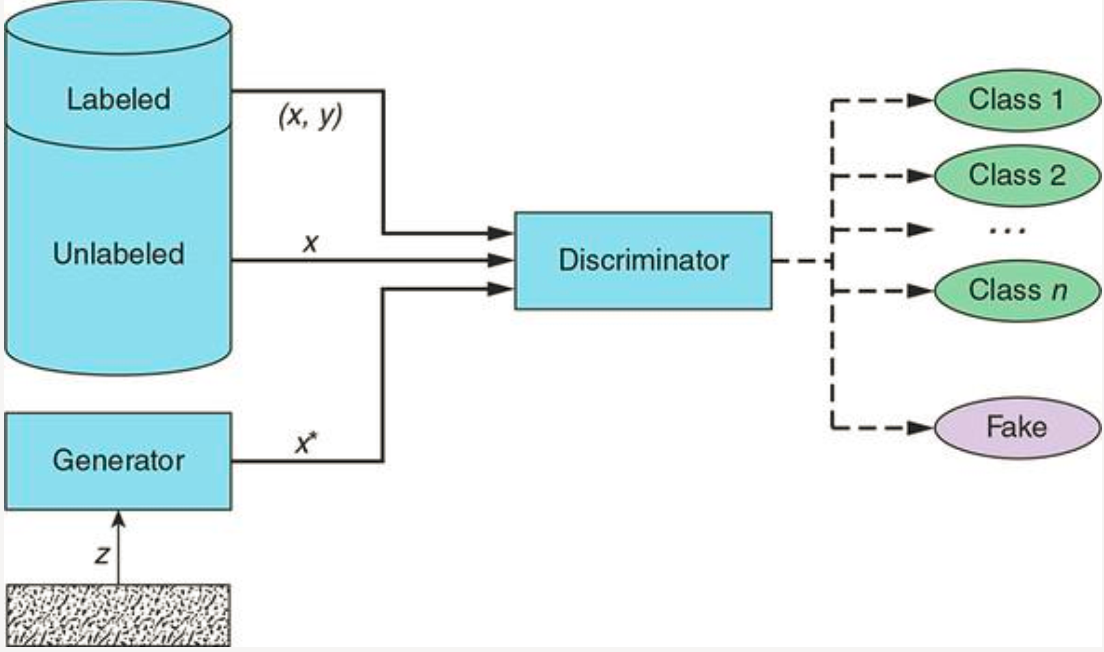
SGAN的主要思想在鉴别器的设计.相比普通的GAN的鉴别器输出0和1(真和假), SGAN通 过使鉴别器网络输出 label + 1 类别,将其转换为半监督上下文 .
我们希望设计的鉴别器既扮演执行图像分类任务的分类器的角色,又能区分由生成器生成的生成样本和真实数据.
传统的GAN在判别器网络的输出端会使用二分类模式 ,代表真和假。在SGAN中,就是把这个二分类(sigmoid)转化为多分类 (softmax),类型数量为C+1,指代C个标签的数据和" 一个假数据”,表示为

SSGAN在数据集上训练生成模型G和D(对 C +1 类别执行分类)。 在训练时, D预测输入属于C+1类中的哪一类,其中添加了一个额外的类对应生成图片。 该方法可以用于创建数据效率更高的分类器。
SGAN的模型设计
对于包含C个类别的数据集:真实的图像将被分类到C个类别中,生成的图像将分入第 C+1 类中。
在SGAN中,判别器同时接受两种模式的训练:无监督和监督 。
在无监督模式中,需要区分真实图像和生成的图像,就像在传统的GAN中一样
。
在监督模式中,需要将一幅图像分类为几个类,就像在标准的神经网络分类器中一样。
在半监督GAN中,对判别器模型进行更新,预测K+1个类,其中K为预测问题中的类数,并为一个新的“假”类添加额 外的类标签。它涉及到同时训练无监督分类任务和有监督分类任务的判别器模型。 SGAN巧妙地结合了无监督和监督学习的方面,以最小的标签量,产生难以置信的结果。
SGAN的代码实现(pytorch版本)


1 import torch 2 import torch.nn as nn 3 import torch.nn.functional as F 4 from torch.utils import data 5 import torchvision 6 from torchvision import transforms 7 8 import numpy as np 9 import matplotlib.pyplot as plt 10 import os 11 import glob 12 from PIL import Image 13 14 import time 15 16 transform = transforms.Compose([ 17 transforms.ToTensor(), # 取值范围会被归一化到(0, 1)之间 18 transforms.Normalize(mean=0.5, std=0.5) # 设置均值和方差均为0.5 19 ]) 20 21 # 加载MNIST手写体数据集合 22 23 dataset = torchvision.datasets.MNIST('data', 24 train=True, 25 transform=transform, 26 download=True 27 ) 28 29 train_label_size = 1000 30 train_unlabel_size = len(dataset) - train_label_size 31 label_ds, unlabel_ds = torch.utils.data.random_split( 32 dataset, 33 [train_label_size, train_unlabel_size] 34 ) 35 36 len(label_ds), len(unlabel_ds) 37 38 label_dl = data.DataLoader(label_ds, batch_size=256, shuffle=True) 39 unlabel_dl = data.DataLoader(unlabel_ds, batch_size=256, shuffle=True) 40 41 test_ds = torchvision.datasets.MNIST('data', 42 train=False, 43 transform=transform, 44 download=True 45 ) 46 47 device = "cuda" if torch.cuda.is_available() else "cpu" 48 49 test_dl = data.DataLoader(test_ds, batch_size=256) 50 51 def test(dataloader, model, loss_fn): 52 model.eval() 53 size = len(dataloader.dataset) 54 num_batches = len(dataloader) 55 test_loss, correct = 0, 0 56 with torch.no_grad(): 57 for X, y in dataloader: 58 X, y = X.to(device), y.to(device) 59 pred, _ = model(X) 60 test_loss += loss_fn(pred, y).item() 61 correct += (pred.argmax(1) == y).type(torch.float).sum().item() 62 test_loss /= num_batches 63 correct /= size 64 return test_loss, correct 65 66 67 #定义生成器 68 class Generator(nn.Module): 69 def __init__(self): 70 super(Generator, self).__init__() 71 self.linear1 = nn.Linear(100, 256*7*7) 72 self.bn1 = nn.BatchNorm1d(256*7*7) 73 self.deconv1 = nn.ConvTranspose2d(256, 128, 74 kernel_size=(3, 3), 75 stride=1, 76 padding=1) # (128, 7, 7) 77 self.bn2 = nn.BatchNorm2d(128) 78 79 self.deconv2 = nn.ConvTranspose2d(128, 64, 80 kernel_size=(4, 4), 81 stride=2, 82 padding=1) # (64, 14, 14) 83 self.bn3 = nn.BatchNorm2d(64) 84 85 self.deconv3 = nn.ConvTranspose2d(64, 1, 86 kernel_size=(4, 4), 87 stride=2, 88 padding=1) # (1, 28, 28) 89 90 def forward(self, x): 91 x = F.relu(self.linear1(x)) 92 x = self.bn1(x) 93 x = x.view(-1, 256, 7, 7) 94 x = F.relu(self.deconv1(x)) 95 x = self.bn2(x) 96 x = F.relu(self.deconv2(x)) 97 x = self.bn3(x) 98 x = torch.tanh(self.deconv3(x)) 99 return x 100 101 # 定义判别器 102 class Discriminator(nn.Module): 103 def __init__(self): 104 super(Discriminator, self).__init__() 105 self.conv1 = nn.Conv2d(1, 64, kernel_size=3, stride=2) 106 self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=2) 107 self.bn = nn.BatchNorm2d(128) 108 self.fc1 = nn.Linear(128*6*6, 10) 109 self.fc2 = nn.Linear(128*6*6, 1) 110 111 def forward(self, x): 112 x = F.dropout2d(F.leaky_relu(self.conv1(x))) 113 x = F.dropout2d(F.leaky_relu(self.conv2(x))) # (batch, 128, 6, 6) 114 x = self.bn(x) 115 x = x.view(-1, 128*6*6) # (batch, 128, 6, 6)--> (batch, 128*6*6) 116 x1 = self.fc1(x) 117 x2 = self.fc2(x) 118 return x1, x2 119 120 gen = Generator().to(device) 121 dis = Discriminator().to(device) 122 loss_softmax_fn = nn.CrossEntropyLoss() # 定义损失函数 = -log(softmax(xi)) 多分类计算损失 123 loss_sigmoid_fn = torch.nn.BCEWithLogitsLoss() # 二分类损失函数 124 d_optimizer = torch.optim.Adam(dis.parameters(), lr=0.00002) 125 g_optimizer = torch.optim.Adam(gen.parameters(), lr=0.0001) 126 127 # 定义可视化函数 128 def generate_and_save_images(model, epoch, test_input): 129 # np.squeeze去掉长度为1的维度 130 predictions = np.squeeze(model(test_input).detach().cpu().numpy()) 131 fig = plt.figure(figsize=(2, 4)) # 可视化16张图片 132 for i in range(predictions.shape[0]): 133 plt.subplot(2, 4, i+1) 134 plt.imshow((predictions[i] + 1)/2) # 注意取值范围的转换 135 plt.axis('off') 136 plt.savefig('./SGAN_mnist/image_at_epoch_{:04d}.png'.format(epoch)) 137 plt.show() 138 plt.close() 139 140 141 # 设置生成绘图图片的随机张量,这里可视化16张图片 142 # 生成16个长度为100的随机正态分布张量 143 test_seed = torch.randn(8, 100, device=device) 144 145 D_loss = [] # 记录训练过程中判别器loss变化 146 G_loss = [] # 记录训练过程中生成器loss变化 147 epochs = [] 148 149 #开始训练 150 for epoch in range(1000): 151 152 epoch_start = time.time() 153 154 D_epoch_loss=0 155 G_epoch_loss=0 156 count = len(unlabel_dl) 157 for unlb_img, _ in unlabel_dl: 158 # count = len(unlabel_dl) 159 unlb_img = unlb_img.to(device) 160 size = unlb_img.shape[0] 161 random_seed = torch.randn(size, 100, device=device) # 生成随机输入 162 163 lb_img, label = next(iter(label_dl)) 164 lb_img = lb_img.to(device) 165 label = label.to(device) 166 167 d_optimizer.zero_grad() 168 _, real_sg_out = dis(unlb_img) # 判别器输入真实图片 169 d_real_sg_loss = loss_sigmoid_fn(real_sg_out, 170 torch.ones_like(real_sg_out, 171 device=device)) 172 d_real_sg_loss.backward() 173 # 生成器输入随机张量得到生成图片 174 generated_img = gen(random_seed) 175 # 判别器输入生成图像,注意此处的detach方法 176 _, fake_sg_output = dis(generated_img.detach()) 177 d_fake_sg_loss = loss_sigmoid_fn(fake_sg_output, 178 torch.zeros_like(fake_sg_output, 179 device=device)) 180 d_fake_sg_loss.backward() 181 182 real_sfm_out, _ = dis(lb_img) # 判别器输入真实图片 183 d_real_sfm_loss = loss_softmax_fn(real_sfm_out, label) 184 d_real_sfm_loss.backward() 185 186 # _, d_real_lb_sg_loss = dis(lb_img) # 判别器输入真实图片 187 # d_real_lb_sg_loss = loss_sigmoid_fn(read_label_sg_out, 188 # torch.ones_like(read_label_sg_out, 189 # device=device)) 190 # d_real_lb_sg_loss.backward() 191 192 193 disc_loss = d_real_sg_loss + d_fake_sg_loss + d_real_sfm_loss # 判别器的总损失 194 195 d_optimizer.step() 196 197 198 g_optimizer.zero_grad() 199 200 _, fake_output = dis(generated_img) # 判别器输入生成图像 201 gen_loss = loss_sigmoid_fn(fake_output, 202 torch.ones_like(fake_output, 203 device=device)) 204 gen_loss.backward() 205 206 g_optimizer.step() 207 208 with torch.no_grad(): 209 D_epoch_loss += disc_loss.item() 210 G_epoch_loss += gen_loss.item() 211 212 epoch_finish = time.time() 213 214 with torch.no_grad(): 215 D_epoch_loss /= count 216 G_epoch_loss /= count 217 D_loss.append(D_epoch_loss) 218 G_loss.append(G_epoch_loss) 219 epochs.append(epoch) 220 221 # 训练完一个Epoch,打印提示并绘制生成的图片 222 if epoch%10 == 0: 223 test_loss, test_acc = test(test_dl, dis, loss_softmax_fn) 224 print("Epoch:", epoch, 225 'test_loss:{:.2f}'.format(test_loss), 226 'test_accs:{:.2f}'.format(test_acc), 227 'time:{:.2f}s'.format(epoch_finish-epoch_start)) 228 generate_and_save_images(gen, epoch, test_seed) 229 230 # 绘制loss函数 231 def D_G_loss_plot(D_loss, G_loss, epotchs): 232 233 fig = plt.figure(figsize=(4, 4)) 234 235 plt.plot(epotchs, D_loss, label='D_loss') 236 plt.plot(epotchs, G_loss, label='G_loss') 237 plt.legend() 238 239 plt.title("D_G_Loss") 240 plt.savefig('./SGAN_mnist/loss_at_epoch_{:04d}.png'.format(epotchs[len(epotchs)-1])) 241 plt.close() 242 243 D_G_loss_plot(D_loss, G_loss, epochs)
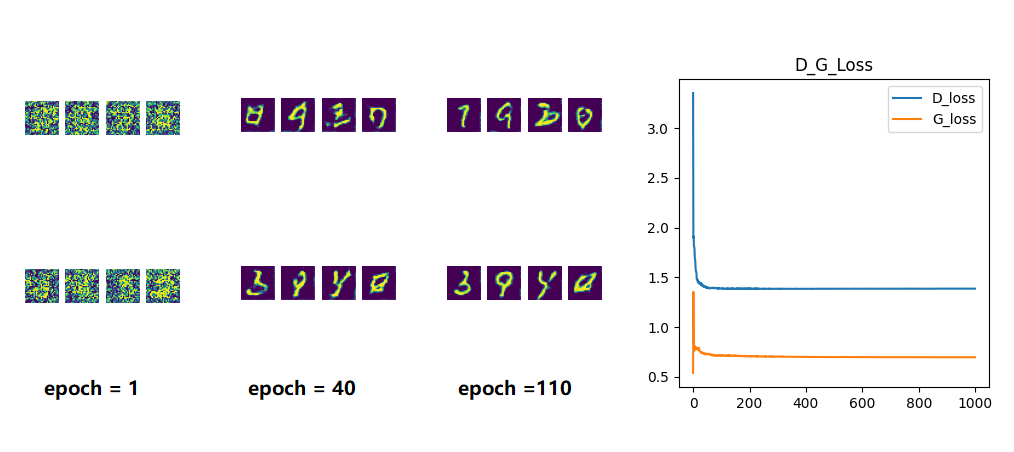
SGAN的效果图及Loss

 浙公网安备 33010602011771号
浙公网安备 33010602011771号