
04_pix2pixGAN
图像处理的很多问题都是将一张输入的图片转变为一张对应的输出图片,比如灰度图、彩色图之间的转换、图像自动上色等.如果要根据每个问题设定一个特定的loss function 来让CNN去优化,通常都是训练CNN去缩小输入跟输出的欧氏距离,但这样通常会得到比较模糊的输出 .pix2pix GAN主要用于图像之间的转换,又称图像翻译。

论文:Image-to-Image Translation with Conditional Adversarial Networks
链接:https://arxiv.org/pdf/1611.07004.pdf
pix2pixGAN
普通的GAN接收的G部分的输入是随机向量,输出是图像;D部分接收的输入是图像(生成的或是真实的),输出是对或者错。这样G和D联手就能输出真实的图像。
Pix2pixgan本质上是一个cgan,图片 x 作为此cGAN的条件,需要输入到G和D中。 G的输入是x(x 是需要转换的图片),输出是生成的图片G(x)。 D则需要分辨出{x,G(x)}和{x, y}。
pix2pixGAN生成器的设计
对于图像翻译任务来说,它的G输入显然应该是一张图x,输出当然也是一张图y;可以不添加随机输入 z, 添加 z 可以带来多样性。 对于图像翻译这些任务来说, 输入和输出之间会共享很多的信息。 比如轮廓信息是共享的。

如果使用普通的卷积神经网络,那么会导致每一层都承载保存着所有的信息,这样神经网络很容易出错。
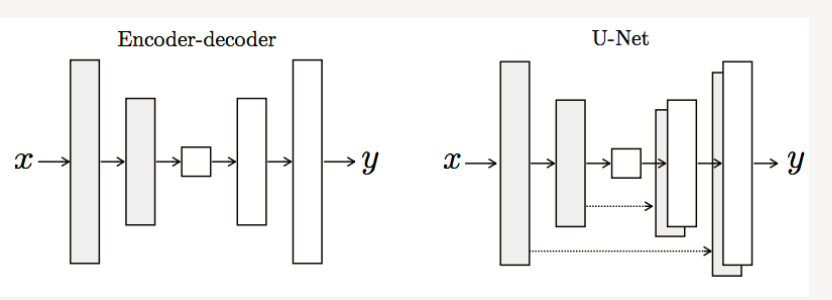
UNET网络结构
U-Net也是Encoder-Decoder模型, 是变形的EncoderDecoder模型。所谓的U-Net是将第i层拼接到第n-i层,这样做是因为第i层和第n-i层的图像大小是一致的,可以认为他们承载着类似的信息。
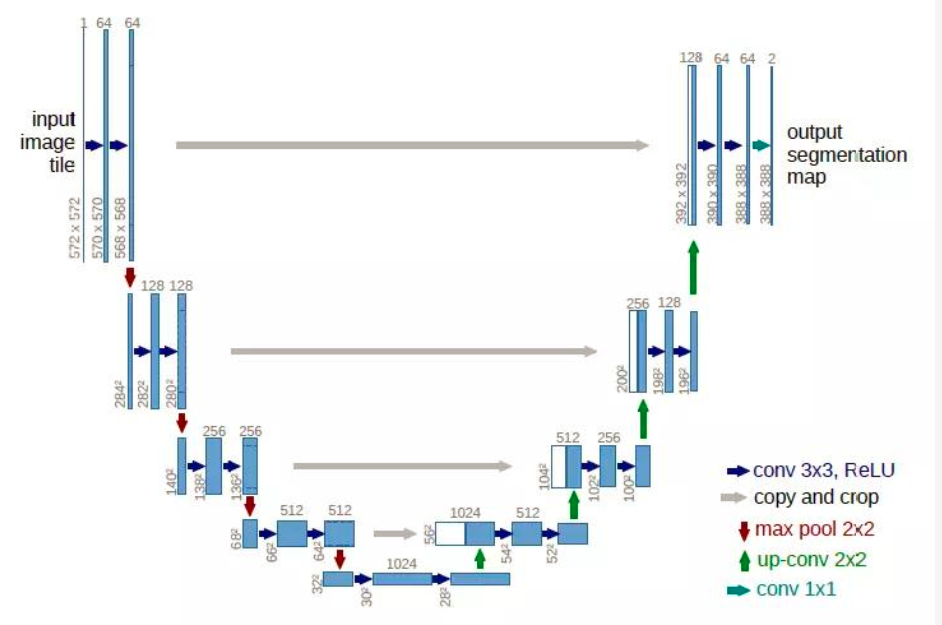
判别器D的设计
但是D的输入却应该发生一些变化,因为除了要生成真实图像之外,还要保证生成的图像和输入图像是匹配的。于是D的输入就做了一些变动。 D中要输入成对的图像。这类似于conditonal GAN。
Pix2Pix中的D被论文中被实现为Patch-D,所谓Patch,是指无论生成的图像有多大,将其切分为多个固定大小的Patch输入进D去判断。
这样设计的好处是: D的输入变小,计算量小,训练速度快。
损失函数
D网络损失函数:输入真实的成对图像希望判定为1.输入生成图像与原图像希望判定为0
G网络损失函数:输入生成图像与原图像希望判定为 1
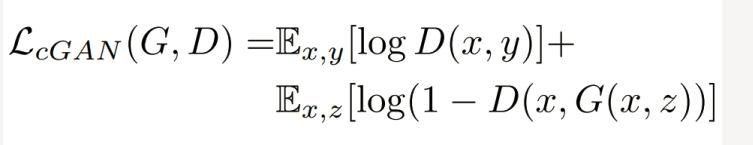
对于图像翻译任务而言, G的输入和输出之间其实共享了很多信息,比如图像上色任务,输入和输出之间就共享了边信息。因而为了保证输入图像和输出图像之间的相似度, 还加入了L1 Loss
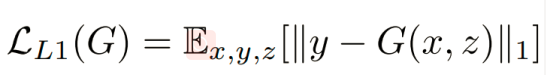
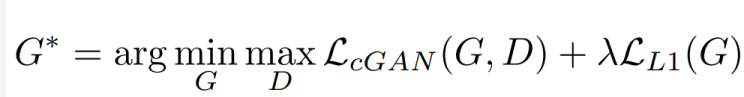
关于噪声输入Z
没有z作为输入,网络仍然可以学习从x→y的映射,但会产生确定性输出。在前面章节我,我们提供随机的高斯噪声z作为生成器的输入,以带来多样性。
但在pix2pixgan论文中指出,此策略没有效果–生成器会学习忽略噪声输入。
对于pix2pixgan模型,通过在生成器的各层之间添加dropout来增加随机性,当然,这样的效果也很有限。
Pix2Pix论文中的要点总结
- cGAN,输入为图像而不是随机向量
- U-Net,使用skip-connection来共享更多的信息
- Pair输入到D来保证映射
- Patch-D来降低计算量提升效果
- L1损失函数的加入来保证输入和输出之间的一致性。
Pix2PixGAN训练的loss及效果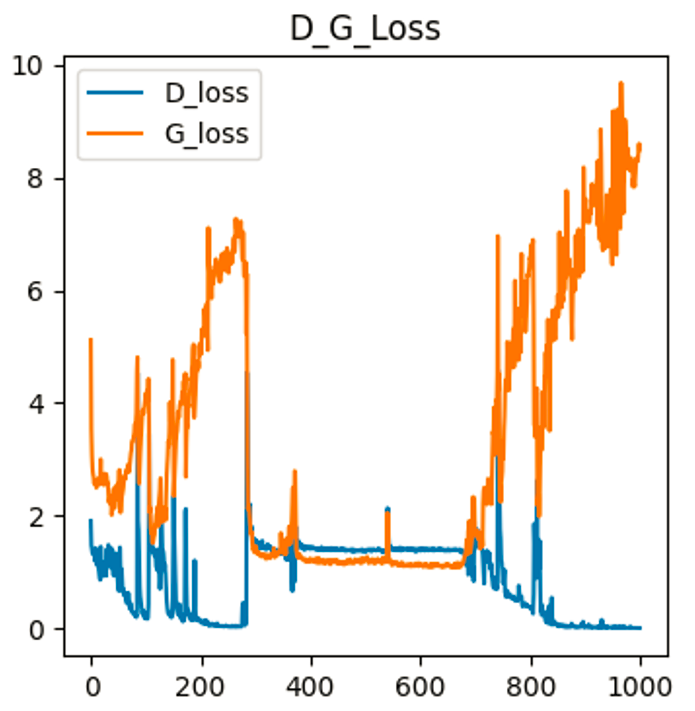
 Pix2Pix的代码实现(Pytorch版本)
Pix2Pix的代码实现(Pytorch版本)


1 import torch 2 import torch.nn as nn 3 import torch.nn.functional as F 4 from torch.utils import data 5 import torchvision #加载图片 6 from torchvision import transforms #图片变换 7 8 import numpy as np 9 import matplotlib.pyplot as plt #绘图 10 import os 11 import glob 12 from PIL import Image 13 14 import time 15 16 # imgs_path = glob.glob('base/*.jpg') 17 # annos_path = glob.glob('base/*.png') 18 19 20 imgs_path = sorted(glob.glob('pix2pixGAN_datasets/training_photos/*.jpg')) 21 annos_path = sorted(glob.glob('pix2pixGAN_datasets/training__sketches/*.jpg')) 22 23 print(len(imgs_path), len(annos_path)) 24 25 for img, an_img in zip(imgs_path, annos_path): 26 print(img, an_img) 27 28 #预处理 29 transform = transforms.Compose([ 30 transforms.ToTensor(), 31 transforms.Resize((256,256)), 32 transforms.Normalize(mean=0.5,std=0.5 33 ) 34 ]) 35 36 #定义数据集 37 class CMP_dataset(data.Dataset): 38 def __init__(self,imgs_path,annos_path): 39 self.imgs_path =imgs_path 40 self.annos_path = annos_path 41 def __getitem__(self,index): 42 img_path = self.imgs_path[index] 43 anno_path = self.annos_path[index] 44 pil_img = Image.open(img_path) #读取数据 45 pil_img = transform(pil_img) #转换数据 46 anno_img = Image.open(anno_path) #读取数据 47 anno_img = anno_img.convert("RGB") 48 pil_anno = transform(anno_img) #转换数据 49 return pil_anno,pil_img 50 def __len__(self): 51 return len(self.imgs_path) 52 53 #创建数据集 54 dataset = CMP_dataset(imgs_path,annos_path) 55 #将数据转化为dataloader的格式,方便迭代 56 BATCHSIZE = 32 57 dataloader = data.DataLoader(dataset, 58 batch_size = BATCHSIZE, 59 shuffle = True) 60 annos_batch,imgs_batch = next(iter(dataloader)) 61 62 #定义下采样模块 63 class Downsample(nn.Module): 64 def __init__(self,in_channels,out_channels): 65 super(Downsample,self).__init__() 66 self.conv_relu = nn.Sequential( 67 nn.Conv2d(in_channels,out_channels, 68 kernel_size=3, 69 stride=2, 70 padding=1), 71 nn.LeakyReLU(inplace=True)) 72 self.bn = nn.BatchNorm2d(out_channels) 73 def forward(self,x,is_bn=True): 74 x=self.conv_relu(x) 75 if is_bn: 76 x=self.bn(x) 77 return x 78 79 80 #定义上采样模块 81 class Upsample(nn.Module): 82 def __init__(self,in_channels,out_channels): 83 super(Upsample,self).__init__() 84 self.upconv_relu = nn.Sequential( 85 nn.ConvTranspose2d(in_channels,out_channels, 86 kernel_size=3, 87 stride=2, 88 padding=1, 89 output_padding=1), #反卷积,变为原来的2倍 90 nn.LeakyReLU(inplace=True)) 91 self.bn = nn.BatchNorm2d(out_channels) 92 def forward(self,x,is_drop=False): 93 x=self.upconv_relu(x) 94 x=self.bn(x) 95 if is_drop: 96 x=F.dropout2d(x) 97 return x 98 99 100 #定义生成器:包含6个下采样,5个上采样,一个输出层 101 class Generator(nn.Module): 102 def __init__(self): 103 super(Generator,self).__init__() 104 self.down1 = Downsample(3,64) #64,128,128 105 self.down2 = Downsample(64,128) #128,64,64 106 self.down3 = Downsample(128,256) #256,32,32 107 self.down4 = Downsample(256,512) #512,16,16 108 self.down5 = Downsample(512,512) #512,8,8 109 self.down6 = Downsample(512,512) #512,4,4 110 111 self.up1 = Upsample(512,512) #512,8,8 112 self.up2 = Upsample(1024,512) #512,16,16 113 self.up3 = Upsample(1024,256) #256,32,32 114 self.up4 = Upsample(512,128) #128,64,64 115 self.up5 = Upsample(256,64) #64,128,128 116 117 self.last = nn.ConvTranspose2d(128,3, 118 kernel_size=3, 119 stride=2, 120 padding=1, 121 output_padding=1) #3,256,256 122 123 def forward(self,x): # annos[32, 3, 256, 256] (人脸的素描图像) 124 x1 = self.down1(x) # x[32, 3, 256, 256] --> x1[32, 64, 128, 128] 125 x2 = self.down2(x1) # x1[32, 64, 128, 128] --> x2[32, 128, 64, 64] 126 x3 = self.down3(x2) # x2[32, 64, 128, 128] --> x3[32, 256, 32, 32] 127 x4 = self.down4(x3) # x3[32, 256, 32, 32] --> x4[32, 512, 16, 16] 128 x5 = self.down5(x4) # x4[32, 512, 16, 16] --> x5[32, 512, 8, 8] 129 x6 = self.down6(x5) # x5[32, 512, 16, 16] --> x6[32, 512, 4, 4] 130 131 x6 = self.up1(x6,is_drop=True) # x6[32, 512, 4, 4] --> x6[32, 512, 8, 8] 132 x6 = torch.cat([x6,x5],dim=1) # x6[32, 512, 8, 8] + x5[32, 512, 8, 8] --> x6[32, 1024, 8, 8] 133 134 x6 = self.up2(x6,is_drop=True) # x6[32, 1024, 8, 8] --> x6[32, 512, 16, 16] 135 x6 = torch.cat([x6,x4],dim=1) # x6[32, 512, 16, 16] + x4[32, 512, 16, 16] --> x6[32, 1024, 16, 16] 136 137 x6 = self.up3(x6,is_drop=True) # x6[32, 1024, 16, 16] --> x6[32, 256, 32, 32] 138 x6 = torch.cat([x6,x3],dim=1) # x6[32, 256, 32, 32] + x3[32, 256, 32, 32] --> x6[32, 512, 32, 32] 139 140 x6 = self.up4(x6) # x6[32, 512, 32, 32] --> x6[32, 128, 64, 64] 141 x6 = torch.cat([x6,x2],dim=1) # x6[32, 128, 64, 64] + x2[32, 128, 64, 64] --> x6[32, 256, 64, 64] 142 143 x6 = self.up5(x6) # x6[32, 256, 64, 64] --> x6[32, 64, 128, 128] 144 x6 = torch.cat([x6,x1],dim=1) # x6[32, 64, 128, 128] + x1[32, 64, 128, 128] --> x6[32, 128, 128, 128] 145 146 x6 = torch.tanh(self.last(x6)) # x6[32, 128, 128, 128] --> x6[32, 3, 256, 256] 147 return x6 148 149 #定义判别器 输入anno+img(生成或者真实) concat 150 class Discriminator(nn.Module): 151 def __init__(self): 152 super(Discriminator,self).__init__() 153 self.down1 = Downsample(6,64) 154 self.down2 = Downsample(64,128) 155 self.conv1 = nn.Conv2d(128,256,3) 156 self.bn = nn.BatchNorm2d(256) 157 self.last = nn.Conv2d(256,1,3) 158 def forward(self,anno,img): # anno[32, 3, 256, 256] (真实的人脸图像) img[32, 3, 256, 256](人脸的素描图像) 159 x=torch.cat([anno,img],axis =1) # anno[32, 3, 256, 256] + img[32, 3, 256, 256] --> x[32, 6, 256, 256] 160 x=self.down1(x,is_bn=False) # x[32, 6, 256, 256] --> x[32, 64, 128, 128] 161 x=self.down2(x,is_bn=True) # x[32, 64, 128, 128] --> x[32, 128, 64, 64] 162 x=F.dropout2d(self.bn(F.leaky_relu(self.conv1(x)))) # x[32, 128, 64, 64] --> x[32, 256, 62, 62] 163 x=torch.sigmoid(self.last(x)) #batch*1*60*60 164 return x 165 166 device = "cuda" if torch.cuda.is_available() else'cpu' 167 gen = Generator().to(device) 168 dis = Discriminator().to(device) 169 d_optimizer = torch.optim.Adam(dis.parameters(),lr=1e-3,betas=(0.5,0.999)) 170 g_optimizer = torch.optim.Adam(gen.parameters(),lr=1e-3,betas=(0.5,0.999)) 171 #绘图 172 def generate_images(model,test_anno,test_real, epoch): 173 prediction = model(test_anno).permute(0,2,3,1).detach().cpu().numpy() 174 test_anno = test_anno.permute(0,2,3,1).cpu().numpy() 175 test_real = test_real.permute(0,2,3,1).cpu().numpy() 176 plt.figure(figsize = (10,10)) 177 display_list = [test_anno[0],test_real[0],prediction[0]] 178 title = ['Input','Ground Truth','Output'] 179 for i in range(3): 180 plt.subplot(1,3,i+1) 181 plt.title(title[i]) 182 plt.imshow(display_list[i]) 183 plt.axis('off') #坐标系关掉 184 plt.savefig('pix2pixGAN_datasets/results_img/image_at_epoch_{:04d}.png'.format(epoch)) 185 # plt.show() 186 plt.close() 187 188 test_imgs_path = sorted(glob.glob('pix2pixGAN_datasets/testing_photos/*.jpg')) 189 test_annos_path = sorted(glob.glob('pix2pixGAN_datasets/testing_sketches/*.jpg')) 190 191 test_dataset = CMP_dataset(test_imgs_path,test_annos_path) 192 193 test_dataloader = torch.utils.data.DataLoader( 194 test_dataset, 195 batch_size=BATCHSIZE,) 196 197 #定义损失函数 198 #cgan 损失函数 199 loss_fn = torch.nn.BCELoss() 200 #L1 loss 201 202 annos_batch,imgs_batch = annos_batch.to(device),imgs_batch.to(device) 203 LAMBDA = 7 #L1损失的权重 204 205 # 绘制loss函数 206 def D_G_loss_plot(D_loss, G_loss, epotchs): 207 208 fig = plt.figure(figsize=(4, 4)) 209 210 plt.plot(epotchs, D_loss, label='D_loss') 211 plt.plot(epotchs, G_loss, label='G_loss') 212 plt.legend() 213 214 plt.title("D_G_Loss") 215 plt.savefig('pix2pixGAN_datasets/results_img/loss_at_epoch_{:04d}.png'.format(epotchs[len(epotchs)-1])) 216 plt.close() 217 218 D_loss = []#记录训练过程中判别器loss变化 219 G_loss = []#记录训练过程中生成器loss变化 220 epochs = [] 221 222 #开始训练 223 for epoch in range(1000): 224 225 epoch_start= time.time() 226 227 D_epoch_loss = 0 228 G_epoch_loss = 0 229 count = len(dataloader) 230 for step,(annos,imgs) in enumerate(dataloader): 231 imgs = imgs.to(device) 232 annos = annos.to(device) 233 #定义判别器的损失计算以及优化的过程 234 d_optimizer.zero_grad() 235 disc_real_output = dis(annos,imgs)#输入真实成对图片 236 d_real_loss = loss_fn(disc_real_output,torch.ones_like(disc_real_output, 237 device=device)) 238 d_real_loss.backward() 239 240 gen_output = gen(annos) 241 disc_gen_output = dis(annos,gen_output.detach()) 242 d_fack_loss = loss_fn(disc_gen_output,torch.zeros_like(disc_gen_output, 243 device=device)) 244 d_fack_loss.backward() 245 246 disc_loss = d_real_loss+d_fack_loss#判别器的损失计算 247 d_optimizer.step() 248 249 #定义生成器的损失计算以及优化的过程 250 g_optimizer.zero_grad() 251 disc_gen_out = dis(annos,gen_output) 252 gen_loss_crossentropyloss = loss_fn(disc_gen_out, 253 torch.ones_like(disc_gen_out, 254 device=device)) 255 gen_l1_loss = torch.mean(torch.abs(gen_output-imgs)) # l1 损失 256 gen_loss = gen_loss_crossentropyloss +LAMBDA*gen_l1_loss 257 gen_loss.backward() #反向传播 258 g_optimizer.step() #优化 259 260 #累计每一个批次的loss 261 with torch.no_grad(): 262 D_epoch_loss +=disc_loss.item() 263 G_epoch_loss +=gen_loss.item() 264 265 epoch_finish = time.time() 266 267 #求平均损失 268 with torch.no_grad(): 269 D_epoch_loss /=count 270 G_epoch_loss /=count 271 D_loss.append(D_epoch_loss) 272 G_loss.append(G_epoch_loss) 273 epochs.append(epoch) 274 275 #训练完一个Epoch,打印提示并绘制生成的图片 276 print('Epoch: %d, D_loss: %.6f, G_loss: %.6f, Time: %.3fs' %(epoch, D_epoch_loss, G_epoch_loss, epoch_finish-epoch_start)) 277 # generate_images(gen,annos_batch,imgs_batch, epoch) 278 279 # D_G_loss_plot(D_loss, G_loss, epochs)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号