03-CGAN
《Conditional Generative Adversarial Nets》 论文地址:https://arxiv.org/pdf/1411.1784.pdf,Conditional GAN (CGAN,条件GAN),是 Mehdi Mirza于2014年11月份发表的一篇文章,也是 GAN 系列的早期经典模型之一,是目前许多GAN应用的前身。
原始GAN的特点:
生成的图像是随机的,不可预测的,无法控制网络输出特定的图片, 生成目标不明确,可控性不强。针对原始GAN不能生成具有特定属性的图片的问题,Mehdi Mirza等人提出了cGAN,其核心在于将属性信息y融入生成器G和判别器D中,属性y可以是任何标签信息,例如图像的类别、人脸图像的面部表情等。
CGAN
cGAN的中心思想是希望 可以控制 GAN 生成的图片,而不是单纯的随机生成图片。具体来说, Conditional GAN 在生成器和判别器的输入中增加了额外的 条件信息,生成器生成的图片只有足够真实且与条件相符,才能够通过判别器。
cGAN将无监督学习转为 有监督学习使得网络可以更好地在我们的掌控下进行学习!比如,我们输入条件 狗 生成一张 狗的图; 输入条件 猫 生成一张猫的图片.
CGAN公式
从公式看, cgan相当于在原始GAN的基础上对生成器部分和判别器部分都加了一个条件
:
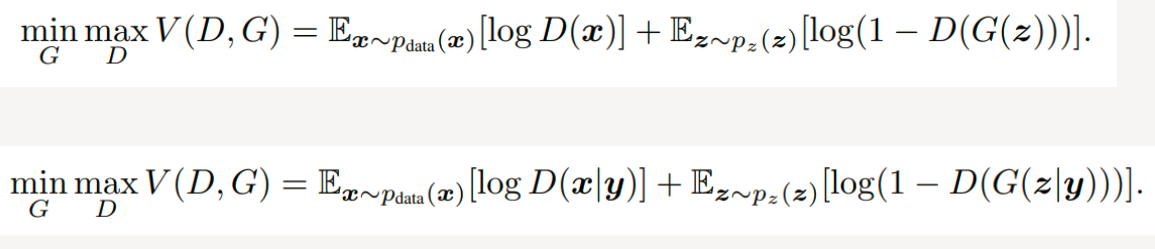
CGAN模型
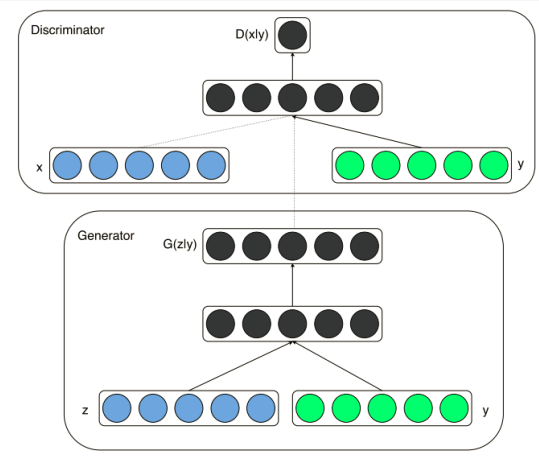
CGAN结构
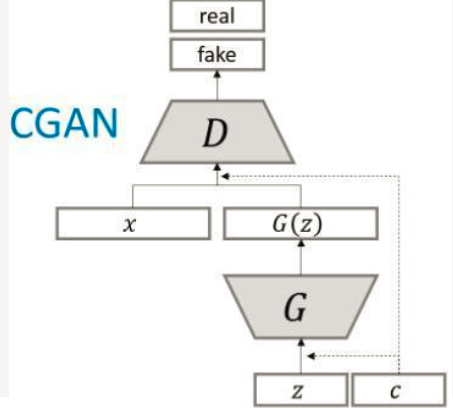
为了实现条件GAN的目的,生成网络和判别网络的原理和训练方式均要有所改变。模型部分,在判别器和生成器中都添加了额外信息 y, y 可以是类别标签或者是其他类型的数据,可以将 y 作为一个额外的输入层丢入判别器和生成器。
在生成器中,作者将输入噪声 z 和 y 连在一起隐含表示,带条件约束这个简单直接的改进被证明非常有效,并广泛用于后续的相关工作中。论文是在MNIST数据集上以类别标签为条件变量,生成指定类别的图像。作者还探索了CGAN在用于图像自动标注的多模态学习上的应用,在MIRFlickr25000数据集上,以图像特征为条件变量,生成该图像的tag的词向量。
CGAN缺陷
cGAN生成的图像虽有很多缺陷,譬如图像边缘模糊,生成的图像分辨率太低等,但是它为后面的pix2pixGAN和CycleGAN开拓了道路,这两个模型转换图像风格时对属性特征的处理方法均受cGAN启发。
CGAN的代码(Pytorch实现)


1 import torch 2 import torch.nn as nn 3 import torch.nn.functional as F 4 from torch.utils import data 5 import torchvision 6 from torchvision import transforms 7 8 import numpy as np 9 import matplotlib.pyplot as plt 10 import os 11 import glob 12 from PIL import Image 13 14 import time 15 16 # one_hot 如何理解? 17 def one_hot(x, class_count=10): 18 return torch.eye(class_count)[x, :] 19 20 transfrom = transforms.Compose([ 21 transforms.ToTensor(), # 取值范围会被归一化到(0, 1)之间 22 transforms.Normalize(mean=0.5, std=0.5) # 设置均值和方差均为0.5 23 ]) 24 25 train_ds = torchvision.datasets.MNIST('data/', 26 train=True, 27 transform=transfrom, 28 target_transform=one_hot, 29 download=True) 30 31 train_dl = torch.utils.data.DataLoader(train_ds, batch_size =64, shuffle=True) 32 33 print(train_ds.class_to_idx) 34 print(train_ds.classes) 35 print(train_ds.data) 36 print(train_ds.root) 37 38 39 #定义生成器 40 class Generator(nn.Module): 41 42 def __init__(self): 43 super(Generator, self).__init__() 44 self.linear1 = nn.Linear(10, 128*7*7) 45 self.bn1 = nn.BatchNorm1d(128*7*7) 46 self.linear2 = nn.Linear(100, 128*7*7) 47 self.bn2 = nn.BatchNorm1d(128*7*7) 48 49 self.deconv1 = nn.ConvTranspose2d(256, 128, 50 kernel_size=(3,3), 51 padding=1) 52 53 self.bn3 = nn.BatchNorm2d(128) 54 self.deconv2 = nn.ConvTranspose2d(128, 64, 55 kernel_size=(4,4), 56 stride=2, 57 padding=1) 58 59 self.bn4 = nn.BatchNorm2d(64) 60 self.deconv3 = nn.ConvTranspose2d(64, 1, 61 kernel_size=(4,4), 62 stride=2, 63 padding=1) 64 65 def forward(self, x1, x2): # label x1[64, 10] rand_seed x2[64, 100] 66 x1 = F.relu(self.linear1(x1)) # x1[64, 10] -->x1[64, 128*7*7] 67 x1 = self.bn1(x1) 68 x1 = x1.view(-1, 128, 7, 7) # x1[64, 128*7*7] -->x1[64, 128, 7, 7] 69 x2 = F.relu(self.linear2(x2)) # x2[64, 100] --> x2[64, 128*7*7] 70 x2 = self.bn2(x2) 71 x2 = x2.view(-1, 128, 7, 7) # x2[64, 128*7*7] -->x2[64, 128, 7, 7] 72 x = torch.cat([x1, x2], axis=1) # x1[64, 128, 7, 7] + x2[64, 128, 7, 7] --> x[64, 256, 7, 7] 73 x = F.relu(self.deconv1(x)) # x[64, 256, 7, 7] --> x[64, 128, 7, 7] 74 x = self.bn3(x) 75 x = F.relu(self.deconv2(x)) # x[64, 128, 7, 7] --> x[64, 64, 14, 14] 76 x = self.bn4(x) 77 x = torch.tanh(self.deconv3(x)) # x[64, 128, 14, 14] --> x[64, 64, 28, 28] --> x[64, 1, 28, 28] 78 return x 79 80 # 定义判别器 81 class Discriminator(nn.Module): 82 83 def __init__(self): 84 85 super(Discriminator, self).__init__() 86 87 self.linear = nn.Linear(10, 1*28*28) 88 self.conv1 = nn.Conv2d(2, 64, 3, 2) 89 self.conv2 = nn.Conv2d(64, 128, 3, 2) 90 self.bn = nn.BatchNorm2d(128) 91 self.fc = nn.Linear(128*6*6, 1) 92 93 def forward(self, x1, x2): # label : x1:[64, 10], img x2[64, 1, 28, 28] 94 95 x1 = F.relu(self.linear(x1)) # 64*10 --> 64*784 96 x1 = x1.view(-1, 1, 28, 28) # 64*784 --> [64,1,28,28] 97 x = torch.cat([x1, x2], axis=1) # x1 [64,1,28,28] + x2[64,1,28,28] -->x[64,2,28,28] 98 x = F.dropout2d(F.leaky_relu(self.conv1(x)), p=0.3) # x[64,2,28,28] --> x[64,64,13,13] 99 x = F.dropout2d(F.leaky_relu(self.conv2(x)), p=0.3) # x[64,64 ,13,13] --> x[64,128,6,6] 100 x = self.bn(x) 101 x = x.view(-1, 128*6*6) # x[64,128,6,6] -->x[64, 128*6*6] 102 x = torch.sigmoid(self.fc(x)) # x[64,128,6,6] --> x[64, 1] 103 104 return x 105 106 device = "cuda" if torch.cuda.is_available() else "cpu" 107 gen = Generator().to(device) 108 dis = Discriminator().to(device) 109 loss_fn = torch.nn.BCELoss() # 定义损失函数 110 d_optimizer = torch.optim.Adam(dis.parameters(), lr=0.0001) 111 g_optimizer = torch.optim.Adam(gen.parameters(), lr=0.0001) 112 113 # 定义可视化函数 114 def generate_and_save_images(model, epoch, label_input, noise_input): 115 # np.squeeze去掉长度为1的维度 116 predictions = np.squeeze(model(label_input, noise_input).cpu().numpy()) 117 fig = plt.figure(figsize=(4, 4)) # 可视化16张图片 118 for i in range(predictions.shape[0]): 119 plt.subplot(4, 4, i+1) 120 plt.imshow((predictions[i] + 1)/2, cmap='gray') # 注意取值范围的转换 121 plt.axis('off') 122 plt.savefig('./CGAN_mnist/image_at_epoch_{:04d}.png'.format(epoch)) 123 plt.show() 124 125 126 # 绘制loss函数 127 def D_G_loss_plot(D_loss, G_loss, epotchs): 128 129 fig = plt.figure(figsize=(4, 4)) 130 131 plt.plot(epotchs, D_loss, label='D_loss') 132 plt.plot(epotchs, G_loss, label='G_loss') 133 plt.legend() 134 135 plt.title("D_G_Loss") 136 plt.savefig('./CGAN_mnist/loss_at_epoch_{:04d}.png'.format(epotchs[len(epotchs)-1])) 137 plt.close() 138 139 # 设置生成绘图图片的随机张量,这里可视化16张图片 140 # 生成16个长度为100的随机正态分布张量 141 noise_seed = torch.randn(16, 100, device=device) # 16*100 142 label_seed = torch.randint(0, 10, size=(16,)) # 16 label,0-9之间的随机数 143 label_seed_onehot = one_hot(label_seed).to(device) #16*10 144 print(label_seed) 145 146 D_loss = [] # 记录训练过程中判别器loss变化 147 G_loss = [] # 记录训练过程中生成器loss变化 148 epochs = [] 149 150 #开始训练 151 for epoch in range(1000): 152 153 epoch_start = time.time() 154 155 D_epoch_loss=0 156 G_epoch_loss=0 157 158 count = len(train_dl.dataset) # train_dl.dataset 60000*28*28 159 160 for step, (img, label) in enumerate(train_dl): 161 img = img.to(device) # 64*1*28*28 162 label = label.to(device) # 64*10 163 164 size=img.shape[0] 165 random_seed = torch.randn(size, 100, device=device) # 生成随机输入 64*100 166 167 d_optimizer.zero_grad() 168 real_output = dis(label, img) # 判别器输入真实图片 real_output[64, 10] 169 d_real_loss = loss_fn(real_output, 170 torch.ones_like(real_output, device=device)) 171 d_real_loss.backward() 172 173 # 生成器输入随机张量得到生成图片 174 generated_img = gen(label, random_seed) 175 # 判别器输入生成图像,注意此处的detach方法 176 fake_output = dis(label, generated_img.detach()) 177 d_fake_loss = loss_fn(fake_output, 178 torch.zeros_like(fake_output, device=device)) 179 d_fake_loss.backward() 180 181 disc_loss = d_real_loss + d_fake_loss # 判别器的总损失 182 d_optimizer.step() 183 184 g_optimizer.zero_grad() 185 fake_output = dis(label, generated_img) # 判别器输入生成图像 186 gen_loss = loss_fn(fake_output, 187 torch.ones_like(fake_output, device=device)) 188 gen_loss.backward() 189 g_optimizer.step() 190 191 with torch.no_grad(): 192 D_epoch_loss += disc_loss.item() 193 G_epoch_loss += gen_loss.item() 194 195 epoch_finish = time.time() 196 197 with torch.no_grad(): 198 D_epoch_loss /= count 199 G_epoch_loss /= count 200 D_loss.append(D_epoch_loss) 201 G_loss.append(G_epoch_loss) 202 epochs.append(epoch) 203 204 # 训练完一个Epoch,打印提示并绘制生成的图片 205 print('Epoch: %d, D_loss: %.6f, G_loss: %.6f, Time: %.3fs' %(epoch, D_epoch_loss, G_epoch_loss, epoch_finish-epoch_start)) 206 print(label_seed) 207 # generate_and_save_images(gen, epoch, label_seed_onehot, noise_seed) 208 209 D_G_loss_plot(D_loss, G_loss, epochs) 210

 浙公网安备 33010602011771号
浙公网安备 33010602011771号